Real-time 3D-aware Portrait Editing from a Single Image
2402.14000
0
0

Abstract
This work presents 3DPE, a practical method that can efficiently edit a face image following given prompts, like reference images or text descriptions, in a 3D-aware manner. To this end, a lightweight module is distilled from a 3D portrait generator and a text-to-image model, which provide prior knowledge of face geometry and superior editing capability, respectively. Such a design brings two compelling advantages over existing approaches. First, our system achieves real-time editing with a feedforward network (i.e., ~0.04s per image), over 100x faster than the second competitor. Second, thanks to the powerful priors, our module could focus on the learning of editing-related variations, such that it manages to handle various types of editing simultaneously in the training phase and further supports fast adaptation to user-specified customized types of editing during inference (e.g., with ~5min fine-tuning per style). The code, the model, and the interface will be made publicly available to facilitate future research.
Create account to get full access
Overview
- This paper presents a novel method for real-time 3D-aware portrait editing from a single input image.
- The approach leverages generative face priors to efficiently edit portrait images while preserving 3D facial structure.
- The system can perform various editing tasks like adding accessories, altering expressions, and changing hairstyles in real-time.
Plain English Explanation
This research introduces a new way to edit portrait photos in real-time while maintaining the 3D structure of the face. Rather than just modifying the flat 2D image, the system understands the 3D shape of the face and can make edits that work with this underlying 3D geometry.
Imagine you have a photo of someone's face and you want to add sunglasses or change their expression. Typically, making such edits would be challenging because you'd have to carefully fit the new elements to the 3D contours of the face. This new approach sidesteps that problem by leveraging machine learning models that already understand the 3D structure of human faces.
The key is using "generative face priors" - statistical models trained on many face images that capture the common patterns and structures of human faces in 3D. By tapping into this prior knowledge, the system can efficiently edit portraits while preserving the realistic 3D facial appearance. This allows for quick, natural-looking edits like virtually trying on different hairstyles or accessories.
Technical Explanation
The core of the system is a generator network that can produce photorealistic face images conditioned on a 3D face mesh. This 3D face representation encodes the geometric structure of the face, allowing the generator to create edits that seamlessly integrate with the underlying 3D facial geometry.
To enable real-time performance, the system uses a coarse-to-fine strategy. First, a low-resolution version of the edited face is produced quickly. This rough output is then progressively refined to increase the resolution and detail. Joint optimization of the generator and discriminator networks during training helps the system learn to produce high-quality, 3D-aware edits efficiently.
The paper demonstrates the system's capabilities across a range of portrait editing tasks, including adding accessories, changing expressions, and modifying hairstyles. Quantitative and qualitative evaluations show the method outperforms prior 2D-based approaches in terms of both editing quality and computational efficiency.
Critical Analysis
A key strength of this work is its ability to preserve the 3D facial structure during editing, which helps maintain a natural, photorealistic appearance. The authors note that prior 2D-based methods often struggle with this and can produce unrealistic or distorted results.
That said, the paper does not extensively explore the limitations of the proposed approach. For example, it is unclear how well the system would handle highly occluded or partially obscured faces, or how it might perform on diverse populations beyond the dataset used for training. Additionally, the computational efficiency claims are not benchmarked against the fastest prior art.
Further research could investigate the robustness of the 3D-aware editing to challenging real-world scenarios, as well as explore ways to make the system more generalizable. Conducting user studies to better understand the qualitative benefits of 3D-aware editing could also provide valuable insights.
Conclusion
This paper presents a promising step forward in real-time portrait editing by leveraging 3D facial priors. The ability to make natural-looking edits that preserve the underlying 3D structure of the face represents an important advance over previous 2D-based techniques. While there are still avenues for further refinement and validation, this work demonstrates the potential of 3D-aware generative models to enable efficient and high-quality portrait editing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
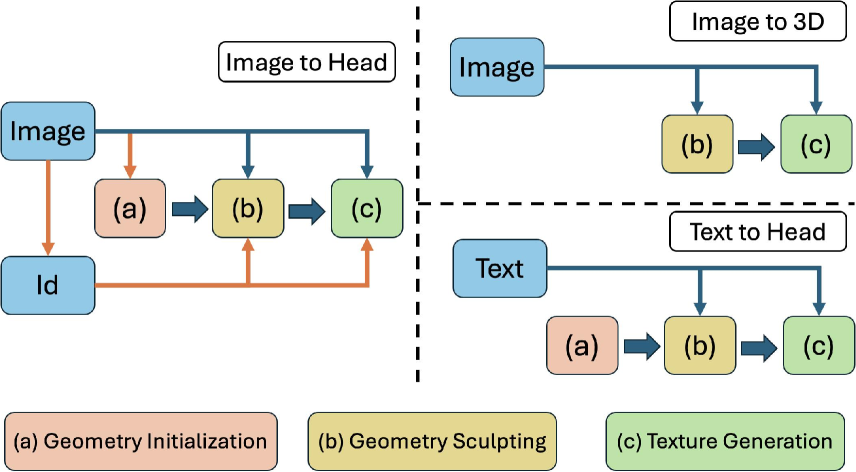
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma
0
0
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
6/26/2024
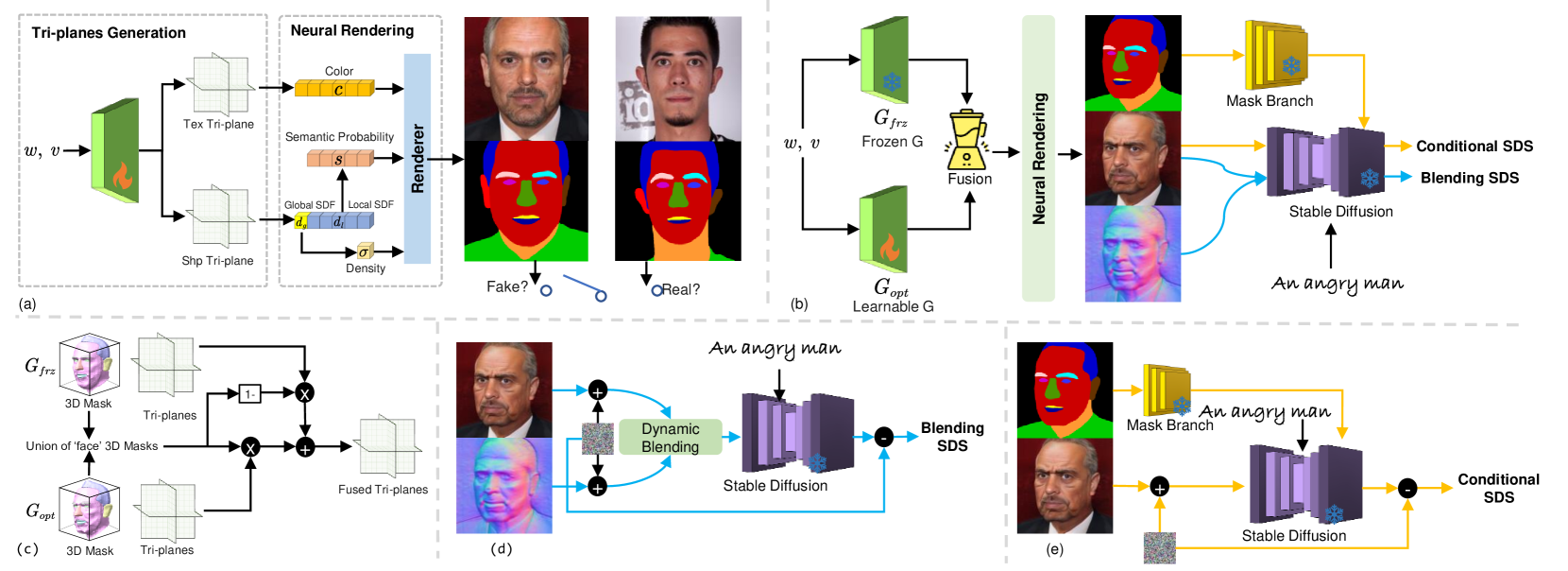
MaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Kangneng Zhou, Daiheng Gao, Xuan Wang, Jie Zhang, Peng Zhang, Xusen Sun, Longhao Zhang, Shiqi Yang, Bang Zhang, Liefeng Bo, Yaxing Wang, Ming-Ming Cheng
0
0
3D-aware portrait editing has a wide range of applications in multiple fields. However, current approaches are limited due that they can only perform mask-guided or text-based editing. Even by fusing the two procedures into a model, the editing quality and stability cannot be ensured. To address this limitation, we propose textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. In this framework, first, we introduce a new SDF-based 3D generator which learns local and global representations with proposed SDF and density consistency losses. This enhances masked-based editing in local areas; second, we present a novel distillation strategy: Conditional Distillation on Geometry and Texture (CDGT). Compared to exiting distillation strategies, it mitigates visual ambiguity and avoids mismatch between texture and geometry, thereby producing stable texture and convincing geometry while editing. Additionally, we create the CatMask-HQ dataset, a large-scale high-resolution cat face annotation for exploration of model generalization and expansion. We perform expensive experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the editing quality and stability of the proposed method. Our method faithfully generates a 3D-aware edited face image based on a modified mask and a text prompt. Our code and models will be publicly released.
5/6/2024
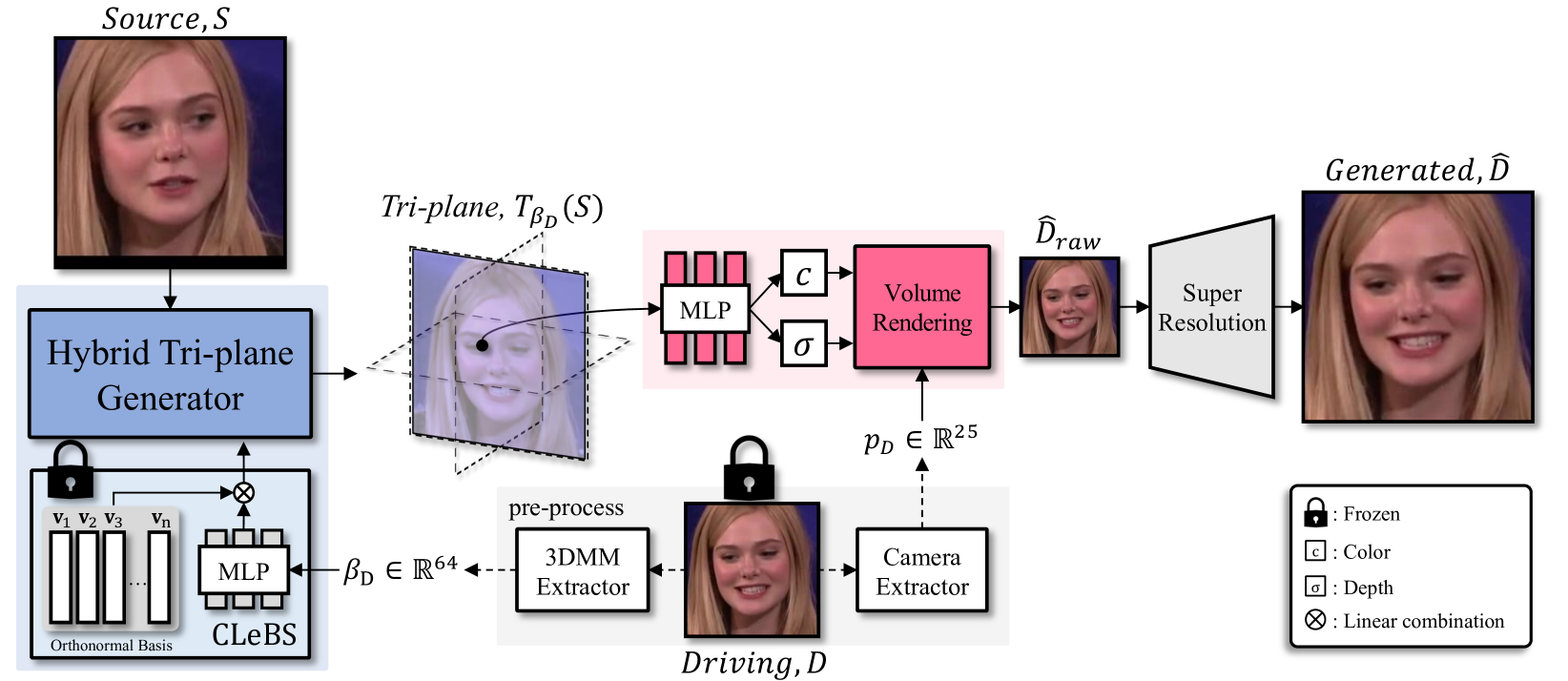
Learning to Generate Conditional Tri-plane for 3D-aware Expression Controllable Portrait Animation
Taekyung Ki, Dongchan Min, Gyeongsu Chae
0
0
In this paper, we present Export3D, a one-shot 3D-aware portrait animation method that is able to control the facial expression and camera view of a given portrait image. To achieve this, we introduce a tri-plane generator that directly generates a tri-plane of 3D prior by transferring the expression parameter of 3DMM into the source image. The tri-plane is then decoded into the image of different view through a differentiable volume rendering. Existing portrait animation methods heavily rely on image warping to transfer the expression in the motion space, challenging on disentanglement of appearance and expression. In contrast, we propose a contrastive pre-training framework for appearance-free expression parameter, eliminating undesirable appearance swap when transferring a cross-identity expression. Extensive experiments show that our pre-training framework can learn the appearance-free expression representation hidden in 3DMM, and our model can generate 3D-aware expression controllable portrait image without appearance swap in the cross-identity manner.
4/3/2024
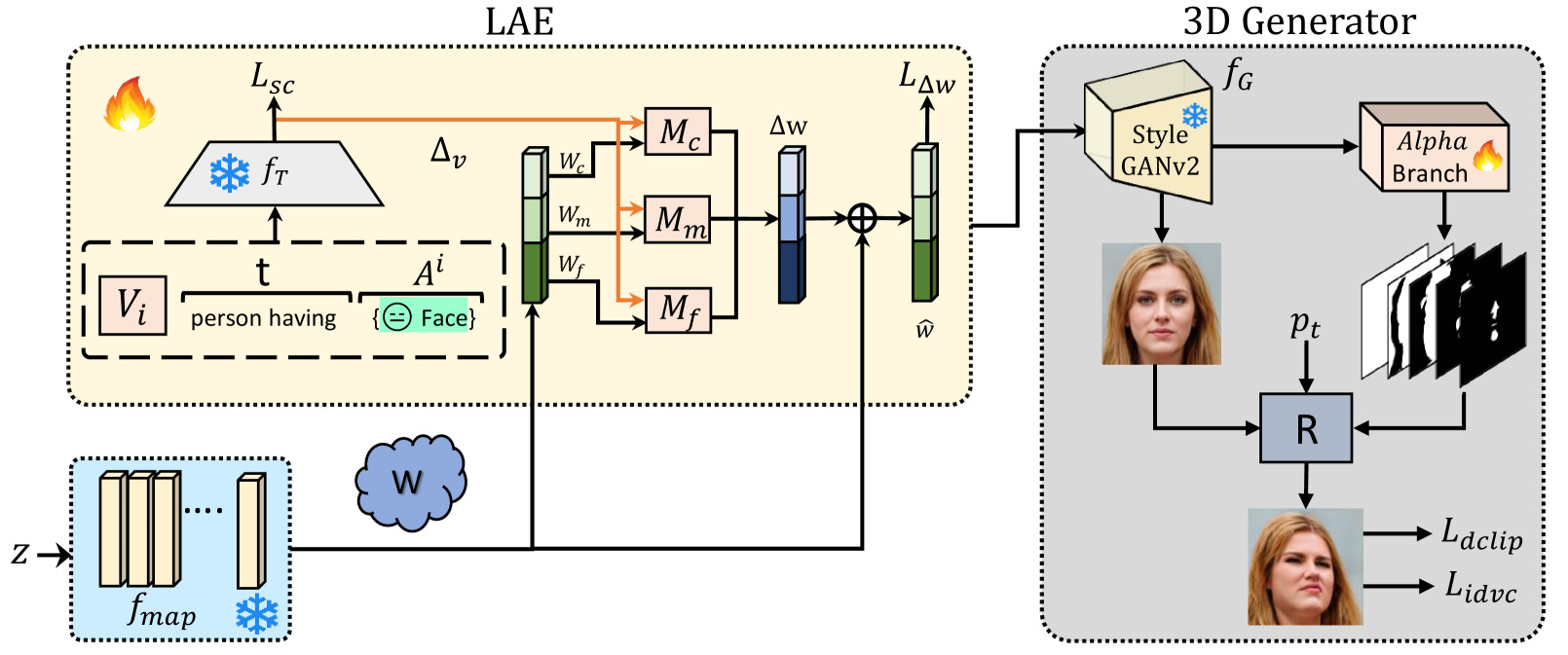
Efficient 3D-Aware Facial Image Editing via Attribute-Specific Prompt Learning
Amandeep Kumar, Muhammad Awais, Sanath Narayan, Hisham Cholakkal, Salman Khan, Rao Muhammad Anwer
0
0
Drawing upon StyleGAN's expressivity and disentangled latent space, existing 2D approaches employ textual prompting to edit facial images with different attributes. In contrast, 3D-aware approaches that generate faces at different target poses require attribute-specific classifiers, learning separate model weights for each attribute, and are not scalable for novel attributes. In this work, we propose an efficient, plug-and-play, 3D-aware face editing framework based on attribute-specific prompt learning, enabling the generation of facial images with controllable attributes across various target poses. To this end, we introduce a text-driven learnable style token-based latent attribute editor (LAE). The LAE harnesses a pre-trained vision-language model to find text-guided attribute-specific editing direction in the latent space of any pre-trained 3D-aware GAN. It utilizes learnable style tokens and style mappers to learn and transform this editing direction to 3D latent space. To train LAE with multiple attributes, we use directional contrastive loss and style token loss. Furthermore, to ensure view consistency and identity preservation across different poses and attributes, we employ several 3D-aware identity and pose preservation losses. Our experiments show that our proposed framework generates high-quality images with 3D awareness and view consistency while maintaining attribute-specific features. We demonstrate the effectiveness of our method on different facial attributes, including hair color and style, expression, and others. Code: https://github.com/VIROBO-15/Efficient-3D-Aware-Facial-Image-Editing.
6/10/2024