Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores

0

Sign in to get full access
Overview
- This paper presents a novel technique for efficiently accelerating large language models (LLMs) on GPU tensor cores using ultra-low bit quantization.
- The proposed approach, called Efficient Arbitrary Precision Acceleration (EAPA), enables fast and accurate inference of LLMs by leveraging GPU tensor cores.
- EAPA achieves this by using a novel quantization scheme that preserves the model's accuracy while enabling efficient computation on tensor cores.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, running these models on hardware can be computationally expensive, especially for large-scale applications. This paper introduces a technique called Efficient Arbitrary Precision Acceleration (EAPA) that can dramatically speed up the inference of LLMs on graphics processing units (GPUs).
The key idea behind EAPA is to use a clever way of representing the model's weights and activations in a compressed format, while still preserving the model's accuracy. This compressed format can then be efficiently computed on specialized hardware in GPUs called tensor cores, which are designed for fast matrix multiplication.
By using this approach, the researchers were able to achieve significant speedups in LLM inference, making these powerful models more practical to deploy in real-world applications. The technique could be especially useful for applications that require fast language processing, such as chatbots, translation services, or content generation.
Technical Explanation
The paper introduces a novel technique called Efficient Arbitrary Precision Acceleration (EAPA) that enables fast and accurate inference of large language models (LLMs) on GPU tensor cores.
EAPA leverages a quantization scheme that can represent the model's weights and activations using ultra-low bit precision (e.g., 2-4 bits) without significantly impacting the model's accuracy. This compressed representation can then be efficiently computed on the tensor cores in modern GPUs, which are designed for fast matrix multiplication operations.
The key innovations of EAPA include:
- Adaptive Precision Quantization: A quantization technique that dynamically adjusts the bit precision of different model components to maintain accuracy.
- Tensor Core-Friendly Encoding: A novel encoding scheme that allows the compressed model weights and activations to be efficiently computed on GPU tensor cores.
- Outlier-Preserving Quantization: A quantization approach that preserves the accuracy of outlier values, which are important for LLM performance.
Through extensive experiments, the paper demonstrates that EAPA can achieve significant speedups (up to 5x) in LLM inference compared to baseline approaches, while maintaining the model's accuracy. This makes EAPA a promising technique for deploying large, powerful language models in real-world applications that require fast and efficient inference.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the EAPA technique, including comparisons to state-of-the-art quantization methods and detailed ablation studies. The results clearly demonstrate the effectiveness of EAPA in accelerating LLM inference on GPU tensor cores.
However, the paper does not discuss some potential limitations or areas for further research. For example, it would be interesting to see how EAPA performs on a wider range of LLM architectures and tasks, beyond the specific models and benchmarks evaluated in the paper. Additionally, the paper does not explore the energy efficiency or hardware cost implications of the EAPA approach, which could be important considerations for real-world deployment.
Overall, the paper makes a strong contribution to the field of efficient inference for large language models, and the EAPA technique appears to be a promising approach for accelerating these models on GPU hardware. Further research to address potential limitations and expand the evaluation could help strengthen the impact of this work.
Conclusion
This paper presents a novel technique called Efficient Arbitrary Precision Acceleration (EAPA) that enables fast and accurate inference of large language models (LLMs) on GPU tensor cores. EAPA achieves this by using a novel quantization scheme that can represent the model's weights and activations in a highly compressed format, while still preserving the model's accuracy.
The key innovations of EAPA include adaptive precision quantization, tensor core-friendly encoding, and outlier-preserving quantization. Through extensive experiments, the paper demonstrates that EAPA can achieve significant speedups in LLM inference (up to 5x) compared to baseline approaches, making it a promising technique for deploying large, powerful language models in real-world applications that require fast and efficient inference.
Overall, this work represents an important advancement in the field of efficient inference for large language models, and the EAPA technique could have far-reaching implications for the deployment of these powerful AI systems in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores
Shaobo Ma, Chao Fang, Haikuo Shao, Zhongfeng Wang
Large language models (LLMs) have been widely applied but face challenges in efficient inference. While quantization methods reduce computational demands, ultra-low bit quantization with arbitrary precision is hindered by limited GPU Tensor Core support and inefficient memory management, leading to suboptimal acceleration. To address these challenges, we propose a comprehensive acceleration scheme for arbitrary precision LLMs. At its core, we introduce a novel bipolar-INT data format that facilitates parallel computing and supports symmetric quantization, effectively reducing data redundancy. Building on this, we implement an arbitrary precision matrix multiplication scheme that decomposes and recovers matrices at the bit level, enabling flexible precision while maximizing GPU Tensor Core utilization. Furthermore, we develop an efficient matrix preprocessing method that optimizes data layout for subsequent computations. Finally, we design a data recovery-oriented memory management system that strategically utilizes fast shared memory, significantly enhancing kernel execution speed and minimizing memory access latency. Experimental results demonstrate our approach's effectiveness, with up to 13times speedup in matrix multiplication compared to NVIDIA's CUTLASS. When integrated into LLMs, we achieve up to 6.7times inference acceleration. These improvements significantly enhance LLM inference efficiency, enabling broader and more responsive applications of LLMs.
Read more9/27/2024

0
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Chao Zeng, Songwei Liu, Yusheng Xie, Hong Liu, Xiaojian Wang, Miao Wei, Shu Yang, Fangmin Chen, Xing Mei
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their practical application is constrained by substantial memory and computational demands. Post-training quantization (PTQ) is considered an effective method to accelerate LLM inference. Despite its growing popularity in LLM model compression, PTQ deployment faces two major challenges. First, low-bit quantization leads to performance degradation. Second, restricted by the limited integer computing unit type on GPUs, quantized matrix operations with different precisions cannot be effectively accelerated. To address these issues, we introduce a novel arbitrary-bit quantization algorithm and inference framework, ABQ-LLM. It achieves superior performance across various quantization settings and enables efficient arbitrary-precision quantized inference on the GPU. ABQ-LLM introduces several key innovations: (1) a distribution correction method for transformer blocks to mitigate distribution differences caused by full quantization of weights and activations, improving performance at low bit-widths. (2) the bit balance strategy to counteract performance degradation from asymmetric distribution issues at very low bit-widths (e.g., 2-bit). (3) an innovative quantization acceleration framework that reconstructs the quantization matrix multiplication of arbitrary precision combinations based on BTC (Binary TensorCore) equivalents, gets rid of the limitations of INT4/INT8 computing units. ABQ-LLM can convert each component bit width gain into actual acceleration gain, maximizing performance under mixed precision(e.g., W6A6, W2A8). Based on W2*A8 quantization configuration on LLaMA-7B model, it achieved a WikiText2 perplexity of 7.59 (2.17$downarrow $ vs 9.76 in AffineQuant). Compared to SmoothQuant, we realized 1.6$times$ acceleration improvement and 2.7$times$ memory compression gain.
Read more8/26/2024

0
OPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models
Jahyun Koo, Dahoon Park, Sangwoo Jung, Jaeha Kung
To overcome the burden on the memory size and bandwidth due to ever-increasing size of large language models (LLMs), aggressive weight quantization has been recently studied, while lacking research on quantizing activations. In this paper, we present a hardware-software co-design method that results in an energy-efficient LLM accelerator, named OPAL, for generation tasks. First of all, a novel activation quantization method that leverages the microscaling data format while preserving several outliers per sub-tensor block (e.g., four out of 128 elements) is proposed. Second, on top of preserving outliers, mixed precision is utilized that sets 5-bit for inputs to sensitive layers in the decoder block of an LLM, while keeping inputs to less sensitive layers to 3-bit. Finally, we present the OPAL hardware architecture that consists of FP units for handling outliers and vectorized INT multipliers for dominant non-outlier related operations. In addition, OPAL uses log2-based approximation on softmax operations that only requires shift and subtraction to maximize power efficiency. As a result, we are able to improve the energy efficiency by 1.6~2.2x, and reduce the area by 2.4~3.1x with negligible accuracy loss, i.e., <1 perplexity increase.
Read more9/25/2024
0
Fast and Efficient 2-bit LLM Inference on GPU: 2/4/16-bit in a Weight Matrix with Asynchronous Dequantization
Jinhao Li, Jiaming Xu, Shiyao Li, Shan Huang, Jun Liu, Yaoxiu Lian, Guohao Dai
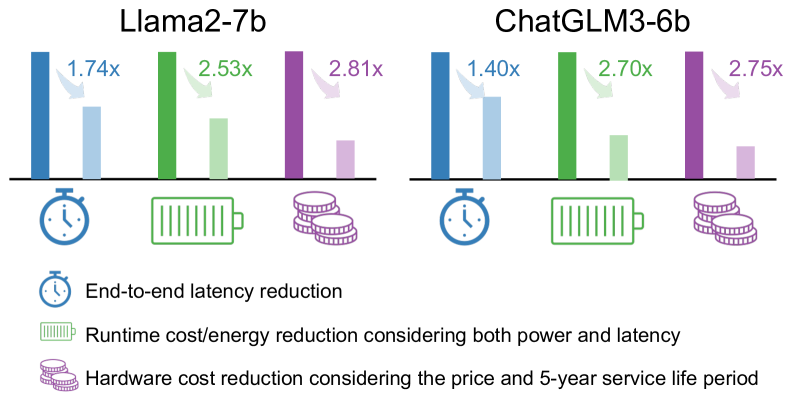
Large language models (LLMs) have demonstrated impressive abilities in various domains while the inference cost is expensive. Many previous studies exploit quantization methods to reduce LLM inference cost by reducing latency and memory consumption. Applying 2-bit single-precision weight quantization brings >3% accuracy loss, so the state-of-the-art methods use mixed-precision methods for LLMs (e.g. Llama2-7b, etc.) to improve the accuracy. However, challenges still exist: (1) Uneven distribution in weight matrix. (2) Large speed degradation by adding sparse outliers. (3) Time-consuming dequantization operations on GPUs. To tackle these challenges and enable fast and efficient LLM inference on GPUs, we propose the following techniques in this paper. (1) Intra-weight mixed-precision quantization. (2) Exclusive 2-bit sparse outlier with minimum speed degradation. (3) Asynchronous dequantization. We conduct extensive experiments on different model families (e.g. Llama3, etc.) and model sizes. We achieve 2.91-bit for each weight considering all scales/zeros for different models with negligible loss. As a result, with our 2/4/16 mixed-precision quantization for each weight matrix and asynchronous dequantization during inference, our design achieves an end-to-end speedup for Llama2-7b is 1.74x over the original model, and we reduce both runtime cost and total cost by up to 2.53x and 2.29x with less GPU requirements.
Read more7/2/2024