Efficient Continual Learning with Low Memory Footprint For Edge Device

0

Sign in to get full access
Overview
- This paper introduces a novel approach for realistic continual learning called "The Name of the Title Is Hope".
- The proposed method aims to address the key challenges in continual learning, such as catastrophic forgetting and limited computational resources.
- The paper explores various techniques, including pre-trained model adaptation, adaptive memory replay, and resource-efficient prompting.
- The authors also investigate the order parameters and phase transitions in continual learning, as well as a brain-inspired approach for robust feature distillation.
Plain English Explanation
The paper introduces a new way of training artificial intelligence (AI) systems to learn continuously, without forgetting what they've learned before. This is a challenging problem in the field of AI, known as "continual learning."
The proposed method, called "The Name of the Title Is Hope," aims to address some of the key issues in continual learning. One of the main problems is that when an AI system learns a new task, it can often "forget" how to do previous tasks, a phenomenon called "catastrophic forgetting." The paper explores different techniques to help the AI system remember what it has learned in the past, while also efficiently using its computational resources.
For example, the researchers look at ways to adapt pre-trained AI models to new tasks, without completely retraining the model from scratch. They also investigate using "memory replay," where the system rehearses past tasks to help maintain its knowledge. Additionally, the paper explores techniques for "resource-efficient prompting," which can help the AI system learn new tasks without requiring a lot of computational power.
The authors also delve into the theoretical aspects of continual learning, examining the "order parameters" and "phase transitions" that occur as the AI system learns and adapts over time. Finally, the paper explores a "brain-inspired" approach, drawing inspiration from how the human brain learns and retains information, to develop more robust feature distillation techniques.
Overall, the goal of this research is to create AI systems that can learn and adapt continuously, without forgetting what they've learned before, and do so in a efficient and resource-conscious way.
Technical Explanation
The paper introduces a novel continual learning approach called "The Name of the Title Is Hope," which aims to address key challenges in this field, such as catastrophic forgetting and limited computational resources.
The authors explore various techniques to tackle these challenges, including:
-
Pre-trained Model Adaptation: The paper investigates methods for adapting pre-trained models to new tasks, rather than retraining the entire model from scratch. This can help the AI system leverage its existing knowledge and learn new tasks more efficiently.
-
Adaptive Memory Replay: The researchers propose using an "adaptive memory replay" mechanism, where the system rehearses past tasks to help maintain its knowledge and prevent forgetting.
-
Resource-Efficient Prompting: The paper explores techniques for "resource-efficient prompting," which can enable the AI system to learn new tasks without requiring a lot of computational power.
-
Order Parameters and Phase Transitions: The authors delve into the theoretical aspects of continual learning, examining the "order parameters" and "phase transitions" that occur as the system learns and adapts over time.
-
Brain-Inspired Continual Learning: Finally, the paper explores a "brain-inspired" approach to continual learning, drawing inspiration from how the human brain learns and retains information, to develop more robust feature distillation techniques.
The paper presents extensive experiments and analyses to validate the effectiveness of the proposed methods, demonstrating their ability to address the key challenges in continual learning while maintaining high performance on various benchmarks.
Critical Analysis
The paper presents a comprehensive and well-designed approach to continual learning, addressing several important challenges in the field. The authors have explored a range of techniques, from pre-trained model adaptation to brain-inspired feature distillation, which shows a strong understanding of the problem and the state-of-the-art solutions.
One potential limitation of the research is the scope of the experiments, which may not cover all possible scenarios and edge cases in real-world applications. The authors acknowledge this and suggest that further research is needed to fully understand the limitations and potential issues with their approach.
Additionally, the theoretical analysis of order parameters and phase transitions, while insightful, may be challenging for some readers to fully comprehend. The authors could have done more to explain these concepts in a more accessible way for a broader audience.
Overall, the paper presents a promising approach to continual learning and offers valuable insights that could inspire further research in this important field. Readers are encouraged to think critically about the research and consider how the proposed techniques might be applied or extended in their own work.
Conclusion
This paper introduces a novel continual learning approach called "The Name of the Title Is Hope," which aims to address key challenges in the field, such as catastrophic forgetting and limited computational resources. The authors explore a range of techniques, including pre-trained model adaptation, adaptive memory replay, resource-efficient prompting, order parameter analysis, and brain-inspired feature distillation.
The proposed methods demonstrate strong performance on various benchmarks, suggesting that they could be valuable tools for developing AI systems that can learn and adapt continuously without forgetting their past knowledge. While the paper presents a comprehensive and well-designed approach, it also acknowledges the need for further research to fully understand the limitations and potential issues with the proposed techniques.
Overall, this work represents an important contribution to the field of continual learning and could inspire new avenues of research and development in this rapidly evolving area of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Continual Learning with Low Memory Footprint For Edge Device
Zeqing Wang, Fei Cheng, Kangye Ji, Bohu Huang
Continual learning(CL) is a useful technique to acquire dynamic knowledge continually. Although powerful cloud platforms can fully exert the ability of CL,e.g., customized recommendation systems, similar personalized requirements for edge devices are almost disregarded. This phenomenon stems from the huge resource overhead involved in training neural networks and overcoming the forgetting problem of CL. This paper focuses on these scenarios and proposes a compact algorithm called LightCL. Different from other CL methods bringing huge resource consumption to acquire generalizability among all tasks for delaying forgetting, LightCL compress the resource consumption of already generalized components in neural networks and uses a few extra resources to improve memory in other parts. We first propose two new metrics of learning plasticity and memory stability to seek generalizability during CL. Based on the discovery that lower and middle layers have more generalizability and deeper layers are opposite, we $textit{Maintain Generalizability}$ by freezing the lower and middle layers. Then, we $textit{Memorize Feature Patterns}$ to stabilize the feature extracting patterns of previous tasks to improve generalizability in deeper layers. In the experimental comparison, LightCL outperforms other SOTA methods in delaying forgetting and reduces at most $textbf{6.16$times$}$ memory footprint, proving the excellent performance of LightCL in efficiency. We also evaluate the efficiency of our method on an edge device, the Jetson Nano, which further proves our method's practical effectiveness.
Read more7/18/2024

0
Redundancy-Aware Efficient Continual Learning on Edge Devices
Sheng Li, Geng Yuan, Yawen Wu, Yue Dai, Tianyu Wang, Chao Wu, Alex K. Jones, Jingtong Hu, Yanzhi Wang, Xulong Tang
Many emerging applications, such as robot-assisted eldercare and object recognition, generally employ deep learning neural networks (DNNs) and require the deployment of DNN models on edge devices. These applications naturally require i) handling streaming-in inference requests and ii) fine-tuning the deployed models to adapt to possible deployment scenario changes. Continual learning (CL) is widely adopted to satisfy these needs. CL is a popular deep learning paradigm that handles both continuous model fine-tuning and overtime inference requests. However, an inappropriate model fine-tuning scheme could involve significant redundancy and consume considerable time and energy, making it challenging to apply CL on edge devices. In this paper, we propose ETuner, an efficient edge continual learning framework that optimizes inference accuracy, fine-tuning execution time, and energy efficiency through both inter-tuning and intra-tuning optimizations. Experimental results show that, on average, ETuner reduces overall fine-tuning execution time by 64%, energy consumption by 56%, and improves average inference accuracy by 1.75% over the immediate model fine-tuning approach.
Read more8/26/2024

0
Learning to Learn without Forgetting using Attention
Anna Vettoruzzo, Joaquin Vanschoren, Mohamed-Rafik Bouguelia, Thorsteinn Rognvaldsson
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
Read more8/15/2024
0
Realistic Continual Learning Approach using Pre-trained Models
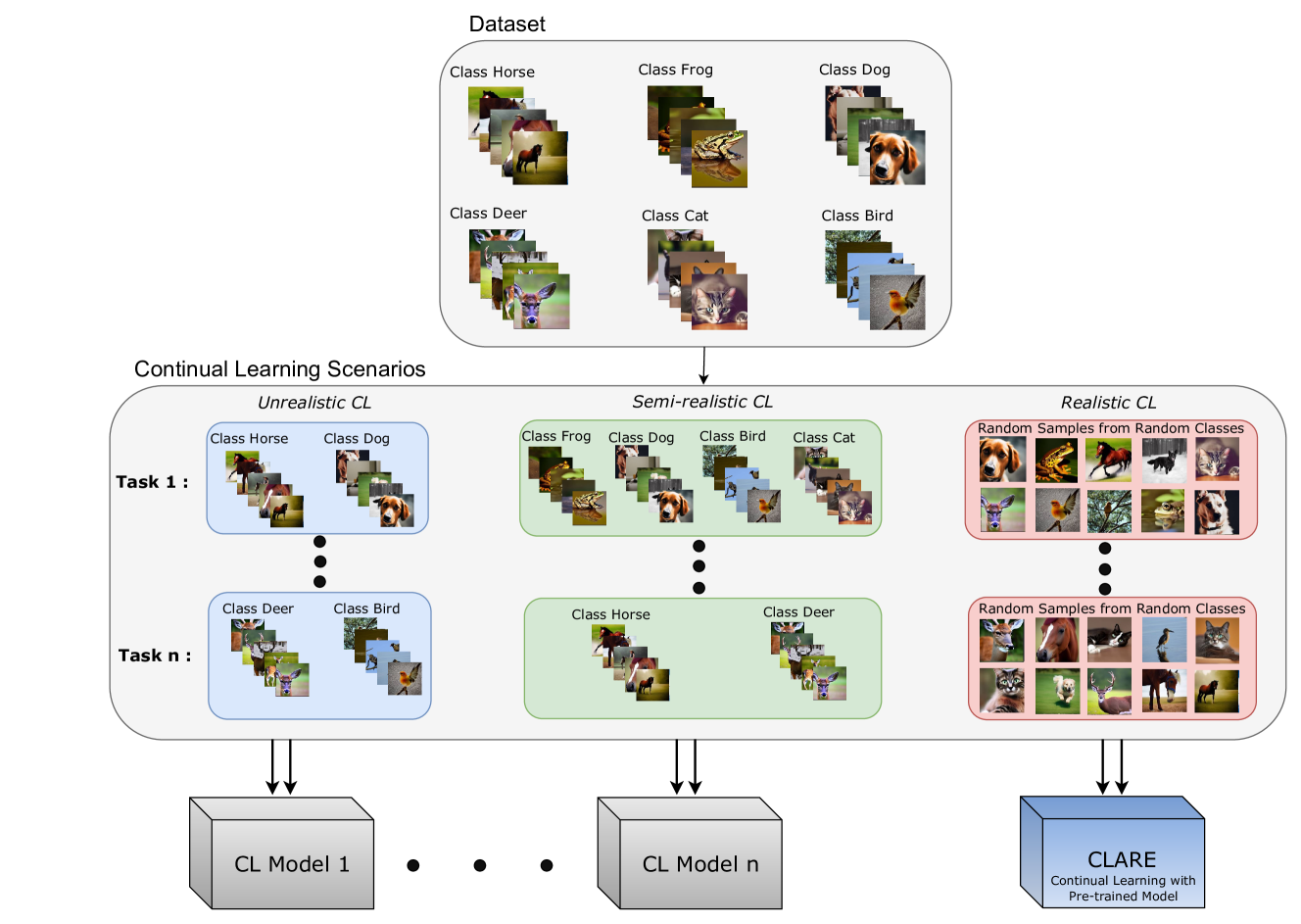
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024