Construction of Domain-specified Japanese Large Language Model for Finance through Continual Pre-training
2404.10555
0
0
💬
Abstract
Large language models (LLMs) are now widely used in various fields, including finance. However, Japanese financial-specific LLMs have not been proposed yet. Hence, this study aims to construct a Japanese financial-specific LLM through continual pre-training. Before tuning, we constructed Japanese financial-focused datasets for continual pre-training. As a base model, we employed a Japanese LLM that achieved state-of-the-art performance on Japanese financial benchmarks among the 10-billion-class parameter models. After continual pre-training using the datasets and the base model, the tuned model performed better than the original model on the Japanese financial benchmarks. Moreover, the outputs comparison results reveal that the tuned model's outputs tend to be better than the original model's outputs in terms of the quality and length of the answers. These findings indicate that domain-specific continual pre-training is also effective for LLMs. The tuned model is publicly available on Hugging Face.
Create account to get full access
Overview
- Researchers have developed a Japanese financial-specific large language model (LLM) through continual pre-training.
- They first constructed Japanese financial-focused datasets for the continual pre-training process.
- They then used a state-of-the-art Japanese LLM as a base model and fine-tuned it on the financial datasets.
- The resulting model outperformed the original model on Japanese financial benchmarks in terms of the quality and length of the answers.
- The tuned model is publicly available on Hugging Face.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models have been widely used in various fields, including finance. However, until now, there haven't been any LLMs specifically trained on Japanese financial data.
To address this gap, researchers created a new Japanese financial-focused LLM. They first gathered a collection of Japanese financial documents and data, which they used to further train an existing high-performing Japanese LLM. This process of "continual pre-training" helps the model develop a deeper understanding of financial concepts and language.
After the additional training, the researchers found that the updated model performed better than the original on tests of Japanese financial tasks. The tuned model was able to provide higher-quality and more detailed answers to financial questions compared to the original.
The researchers have made this improved Japanese financial LLM publicly available on the Hugging Face platform, where others can access and use it for their own financial applications and research.
Technical Explanation
The researchers first constructed Japanese financial-focused datasets for the continual pre-training process. As a base model, they employed a Japanese LLM that had achieved state-of-the-art performance on Japanese financial benchmarks among the 10-billion-class parameter models.
They then used this base model and the financial datasets to perform continual pre-training, a technique that further adapts a pre-trained model to a specific domain or task. After this fine-tuning process, the resulting model outperformed the original base model on the Japanese financial benchmarks.
Specifically, the researchers found that the tuned model's outputs were of higher quality and contained more detailed answers compared to the original model. This indicates that domain-specific continual pre-training can be an effective approach for improving the performance of LLMs in specialized areas like finance.
The researchers have made the tuned Japanese financial-specific LLM publicly available on Hugging Face, allowing others to access and utilize this resource for their own financial applications and research.
Critical Analysis
The researchers have provided a valuable contribution by developing a Japanese financial-specific LLM, as this fills an important gap in the field. By using continual pre-training, they were able to adapt an existing high-performing Japanese LLM to the financial domain, resulting in improved performance on relevant benchmarks.
However, the paper does not delve into the specific details of the datasets used for the continual pre-training or the exact architectural changes made to the base model. Additionally, the researchers do not provide a thorough analysis of the model's limitations or potential biases that may arise from the financial domain-specific training.
Further research could explore the generalizability of this approach to other specialized domains, such as legal or medical fields. Investigating the model's robustness to distribution shifts or its ability to handle complex financial reasoning tasks would also be valuable areas for future work.
Conclusion
This research demonstrates the effectiveness of domain-specific continual pre-training for improving the performance of large language models in specialized areas like finance. By fine-tuning a high-performing Japanese LLM on Japanese financial datasets, the researchers were able to develop a model that outperformed the original on relevant benchmarks.
The availability of this Japanese financial-specific LLM on Hugging Face represents a valuable resource for researchers and practitioners in the field of finance, who can leverage this model for a wide range of applications, from automated financial analysis to natural language-based financial decision support. This research paves the way for further advancements in domain-specific language models and their real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Pretraining and Updating Language- and Domain-specific Large Language Model: A Case Study in Japanese Business Domain
Kosuke Takahashi, Takahiro Omi, Kosuke Arima, Tatsuya Ishigaki
0
0
Several previous studies have considered language- and domain-specific large language models (LLMs) as separate topics. This study explores the combination of a non-English language and a high-demand industry domain, focusing on a Japanese business-specific LLM. This type of a model requires expertise in the business domain, strong language skills, and regular updates of its knowledge. We trained a 13-billion-parameter LLM from scratch using a new dataset of business texts and patents, and continually pretrained it with the latest business documents. Further we propose a new benchmark for Japanese business domain question answering (QA) and evaluate our models on it. The results show that our pretrained model improves QA accuracy without losing general knowledge, and that continual pretraining enhances adaptation to new information. Our pretrained model and business domain benchmark are publicly available.
4/17/2024
Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities
Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masanari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, Naoaki Okazaki
0
0
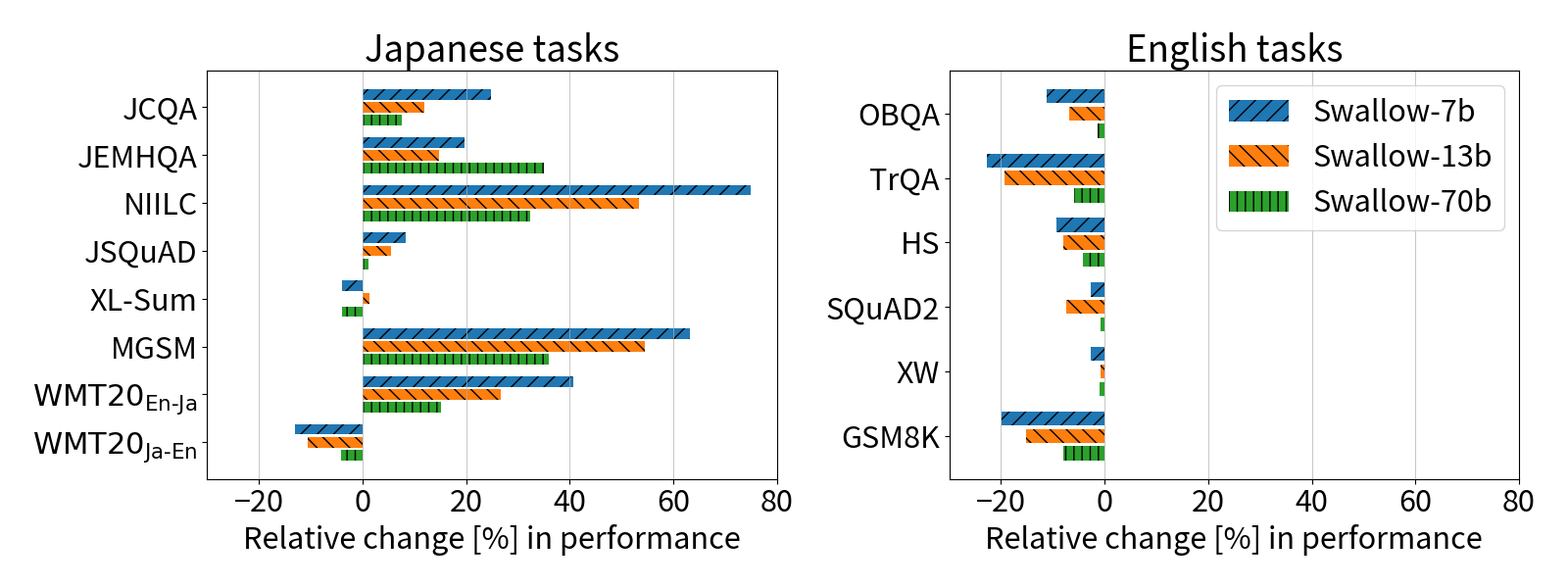
Cross-lingual continual pre-training of large language models (LLMs) initially trained on English corpus allows us to leverage the vast amount of English language resources and reduce the pre-training cost. In this study, we constructed Swallow, an LLM with enhanced Japanese capability, by extending the vocabulary of Llama 2 to include Japanese characters and conducting continual pre-training on a large Japanese web corpus. Experimental results confirmed that the performance on Japanese tasks drastically improved through continual pre-training, and the performance monotonically increased with the amount of training data up to 100B tokens. Consequently, Swallow achieved superior performance compared to other LLMs that were trained from scratch in English and Japanese. An analysis of the effects of continual pre-training revealed that it was particularly effective for Japanese question answering tasks. Furthermore, to elucidate effective methodologies for cross-lingual continual pre-training from English to Japanese, we investigated the impact of vocabulary expansion and the effectiveness of incorporating parallel corpora. The results showed that the efficiency gained through vocabulary expansion had no negative impact on performance, except for the summarization task, and that the combined use of parallel corpora enhanced translation ability.
4/30/2024
Efficient Continual Pre-training by Mitigating the Stability Gap
Yiduo Guo, Jie Fu, Huishuai Zhang, Dongyan Zhao, Yikang Shen
0
0
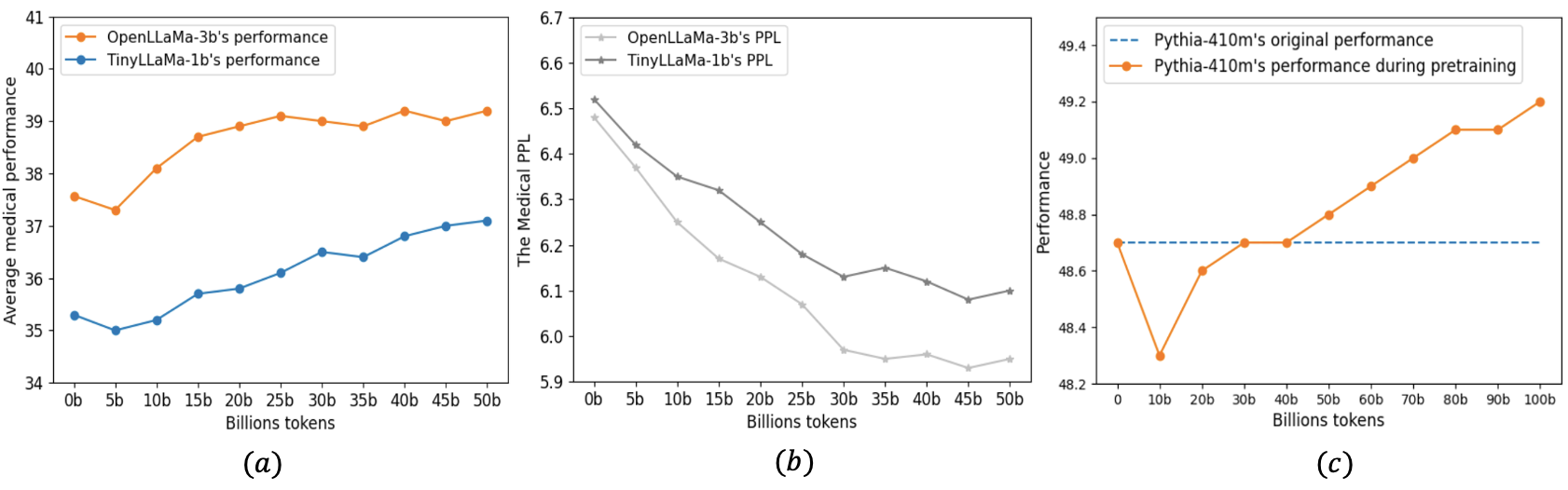
Continual pre-training has increasingly become the predominant approach for adapting Large Language Models (LLMs) to new domains. This process involves updating the pre-trained LLM with a corpus from a new domain, resulting in a shift in the training distribution. To study the behavior of LLMs during this shift, we measured the model's performance throughout the continual pre-training process. we observed a temporary performance drop at the beginning, followed by a recovery phase, a phenomenon known as the stability gap, previously noted in vision models classifying new classes. To address this issue and enhance LLM performance within a fixed compute budget, we propose three effective strategies: (1) Continually pre-training the LLM on a subset with a proper size for multiple epochs, resulting in faster performance recovery than pre-training the LLM on a large corpus in a single epoch; (2) Pre-training the LLM only on high-quality sub-corpus, which rapidly boosts domain performance; and (3) Using a data mixture similar to the pre-training data to reduce distribution gap. We conduct various experiments on Llama-family models to validate the effectiveness of our strategies in both medical continual pre-training and instruction tuning. For example, our strategies improve the average medical task performance of the OpenLlama-3B model from 36.2% to 40.7% with only 40% of the original training budget and enhance the average general task performance without causing forgetting. Furthermore, we apply our strategies to the Llama-3-8B model. The resulting model, Llama-3-Physician, achieves the best medical performance among current open-source models, and performs comparably to or even better than GPT-4 on several medical benchmarks. We release our models at url{https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct}.
6/28/2024
💬
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Hao Wang
0
0
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
4/26/2024