Efficient Encoder-Decoder Transformer Decoding for Decomposable Tasks

1
Sign in to get full access
Overview
- This paper presents a novel approach to efficient transformer decoding, which is a key component of large language models.
- The proposed method, called "Encode Once and Decode in Parallel" (EODP), allows for parallel decoding of multiple prompts simultaneously, reducing the overall computational cost.
- The paper explores the theoretical foundations of the EODP approach and demonstrates its effectiveness through extensive experiments on various benchmark tasks.
Plain English Explanation
The paper deals with a crucial aspect of large language models known as "transformer decoding." Transformer models are the backbone of many state-of-the-art natural language processing systems, including chatbots, language translators, and text summarizers.
The key insight behind the researchers' approach is to encode the input once and then decode multiple prompts in parallel, rather than processing each prompt sequentially. This parallel decoding strategy can significantly reduce the computational resources required to generate text, making language models more efficient and scalable.
To understand this better, imagine you have a group of friends who all want you to help them with their writing assignments. Instead of helping each friend one by one, you could have them all provide their assignments at the same time and provide feedback to the entire group simultaneously. This would be much more efficient than helping each friend individually.
Similarly, the EODP method allows language models to process multiple prompts in parallel, leveraging the inherent parallelism of modern hardware. This can lead to substantial speed-ups and cost savings, particularly when deploying these models at scale.
Technical Explanation
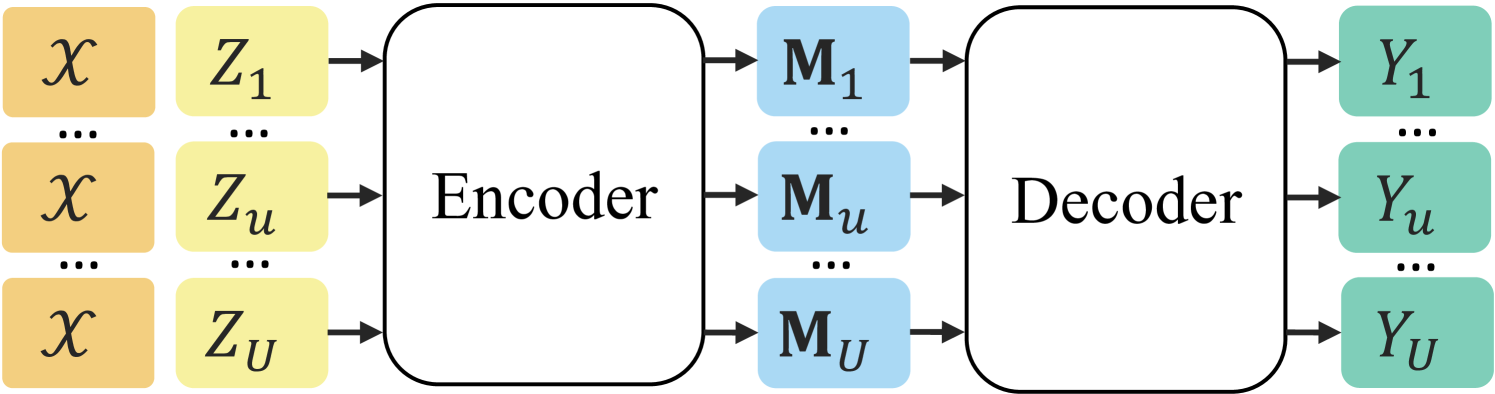
The paper introduces the "Encode Once and Decode in Parallel" (EODP) framework, which builds upon the standard encoder-decoder architecture of transformer models. In a typical transformer, the encoder processes the input sequence, and the decoder generates the output sequence one token at a time.
The EODP approach decouples the encoder and decoder computations, allowing the encoder to be executed only once for multiple prompts. This is achieved by caching the encoder outputs and reusing them during the parallel decoding of different prompts. The authors also propose several techniques to optimize the memory usage and computational efficiency of this parallel decoding process.
The paper presents a thorough theoretical analysis of the EODP framework, demonstrating its advantages in terms of computational complexity and memory usage compared to traditional sequential decoding. The authors also conduct extensive experiments on various benchmarks, including machine translation, text summarization, and language generation tasks, showcasing the significant performance improvements achieved by the EODP method.
Critical Analysis
The paper presents a well-designed and rigorously evaluated approach to efficient transformer decoding. The authors acknowledge some limitations, such as the potential memory overhead for storing the cached encoder outputs, and suggest future research directions to address these challenges.
One potential concern is the generalizability of the EODP approach to more complex transformer architectures, such as those with cross-attention mechanisms or dynamic computation graphs. The paper focuses on the standard encoder-decoder transformer, and it would be valuable to see how the proposed techniques can be extended to handle these more advanced models.
Additionally, the paper does not explore the impact of the EODP method on the quality of the generated text, as the focus is primarily on improving computational efficiency. It would be interesting to see if the parallel decoding approach introduces any trade-offs in terms of output quality, which could be an important consideration for real-world applications.
Conclusion
The "Encode Once and Decode in Parallel" (EODP) framework presented in this paper offers a promising solution for improving the efficiency of transformer decoding, a critical component of large language models. By leveraging parallel processing, the EODP method can significantly reduce the computational resources required to generate text, making these models more scalable and cost-effective.
The theoretical analysis and empirical results demonstrate the advantages of the EODP approach, and the insights provided in this paper can inform the development of more efficient and practical language models. As the demand for powerful, yet resource-efficient natural language processing systems continues to grow, innovations like EODP will play an important role in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Efficient Encoder-Decoder Transformer Decoding for Decomposable Tasks
Bo-Ru Lu, Nikita Haduong, Chien-Yu Lin, Hao Cheng, Noah A. Smith, Mari Ostendorf
Transformer-based NLP models are powerful but have high computational costs that limit deployment. Finetuned encoder-decoder models are popular in specialized domains and can outperform larger more generalized decoder-only models, such as GPT-4. We introduce a new configuration for encoder-decoder models that improves efficiency on structured output and decomposable tasks where multiple outputs are required for a single shared input. Our method, prompt-in-decoder (PiD), encodes the input once and decodes the output in parallel, boosting both training and inference efficiency by avoiding duplicate input encoding and increasing the operational intensity (ratio of numbers of arithmetic operation to memory access) of decoding process by sharing the input key-value cache. We achieve computation reduction that roughly scales with the number of subtasks, gaining up to 4.6x speed-up over state-of-the-art models for dialogue state tracking, summarization, and question-answering tasks, with comparable or better performance.
Read more5/24/2024

0
Multi-Prompting Decoder Helps Better Language Understanding
Zifeng Cheng, Zhaoling Chen, Zhiwei Jiang, Yafeng Yin, Shiping Ge, Yuliang Liu, Qing Gu
Recent Pre-trained Language Models (PLMs) usually only provide users with the inference APIs, namely the emerging Model-as-a-Service (MaaS) setting. To adapt MaaS PLMs to downstream tasks without accessing their parameters and gradients, some existing methods focus on the output-side adaptation of PLMs, viewing the PLM as an encoder and then optimizing a task-specific decoder for decoding the output hidden states and class scores of the PLM. Despite the effectiveness of these methods, they only use a single prompt to query PLMs for decoding, leading to a heavy reliance on the quality of the adopted prompt. In this paper, we propose a simple yet effective Multi-Prompting Decoder (MPD) framework for MaaS adaptation. The core idea is to query PLMs with multiple different prompts for each sample, thereby obtaining multiple output hidden states and class scores for subsequent decoding. Such multi-prompting decoding paradigm can simultaneously mitigate reliance on the quality of a single prompt, alleviate the issue of data scarcity under the few-shot setting, and provide richer knowledge extracted from PLMs. Specifically, we propose two decoding strategies: multi-prompting decoding with optimal transport for hidden states and calibrated decoding for class scores. Extensive experiments demonstrate that our method achieves new state-of-the-art results on multiple natural language understanding datasets under the few-shot setting.
Read more6/11/2024

0
Exploring the Role of Large Language Models in Prompt Encoding for Diffusion Models
Bingqi Ma, Zhuofan Zong, Guanglu Song, Hongsheng Li, Yu Liu
Large language models (LLMs) based on decoder-only transformers have demonstrated superior text understanding capabilities compared to CLIP and T5-series models. However, the paradigm for utilizing current advanced LLMs in text-to-image diffusion models remains to be explored. We observed an unusual phenomenon: directly using a large language model as the prompt encoder significantly degrades the prompt-following ability in image generation. We identified two main obstacles behind this issue. One is the misalignment between the next token prediction training in LLM and the requirement for discriminative prompt features in diffusion models. The other is the intrinsic positional bias introduced by the decoder-only architecture. To deal with this issue, we propose a novel framework to fully harness the capabilities of LLMs. Through the carefully designed usage guidance, we effectively enhance the text representation capability for prompt encoding and eliminate its inherent positional bias. This allows us to integrate state-of-the-art LLMs into the text-to-image generation model flexibly. Furthermore, we also provide an effective manner to fuse multiple LLMs into our framework. Considering the excellent performance and scaling capabilities demonstrated by the transformer architecture, we further design an LLM-Infused Diffusion Transformer (LI-DiT) based on the framework. We conduct extensive experiments to validate LI-DiT across model size and data size. Benefiting from the inherent ability of the LLMs and our innovative designs, the prompt understanding performance of LI-DiT easily surpasses state-of-the-art open-source models as well as mainstream closed-source commercial models including Stable Diffusion 3, DALL-E 3, and Midjourney V6. The powerful LI-DiT-10B will be available through the online platform and API after further optimization and security checks.
Read more6/24/2024
🏷️
0
Towards smallers, faster decoder-only transformers: Architectural variants and their implications
Sathya Krishnan Suresh, Shunmugapriya P
Research on Large Language Models (LLMs) has recently seen exponential growth, largely focused on transformer-based architectures, as introduced by [1] and further advanced by the decoder-only variations in [2]. Contemporary studies typically aim to improve model capabilities by increasing both the architecture's complexity and the volume of training data. However, research exploring how to reduce model sizes while maintaining performance is limited. This study introduces three modifications to the decoder-only transformer architecture: ParallelGPT (p-gpt), LinearlyCompressedGPT (lc-gpt), and ConvCompressedGPT (cc-gpt). These variants achieve comparable performance to conventional architectures in code generation tasks while benefiting from reduced model sizes and faster training times. We open-source the model weights and codebase to support future research and development in this domain.
Read more4/24/2024