Towards smallers, faster decoder-only transformers: Architectural variants and their implications
2404.14462
0
0
🏷️
Abstract
Research on Large Language Models (LLMs) has recently seen exponential growth, largely focused on transformer-based architectures, as introduced by [1] and further advanced by the decoder-only variations in [2]. Contemporary studies typically aim to improve model capabilities by increasing both the architecture's complexity and the volume of training data. However, research exploring how to reduce model sizes while maintaining performance is limited. This study introduces three modifications to the decoder-only transformer architecture: ParallelGPT (p-gpt), LinearlyCompressedGPT (lc-gpt), and ConvCompressedGPT (cc-gpt). These variants achieve comparable performance to conventional architectures in code generation tasks while benefiting from reduced model sizes and faster training times. We open-source the model weights and codebase to support future research and development in this domain.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This study introduces three new variants of the decoder-only transformer architecture for large language models (LLMs): ParallelGPT (p-gpt), LinearlyCompressedGPT (lc-gpt), and ConvCompressedGPT (cc-gpt).
- These models aim to achieve comparable performance to conventional transformer-based LLMs while reducing model size and training time.
- The researchers open-sourced the model weights and codebase to support future research and development in this domain.
Plain English Explanation
Large language models (LLMs) have seen rapid growth in recent years, with a focus on improving model capabilities by increasing the complexity of the architecture and the volume of training data. However, there has been limited research on how to reduce the size of these models while maintaining their performance.
This study introduces three new variations of the popular transformer-based architecture for LLMs: ParallelGPT, LinearlyCompressedGPT, and ConvCompressedGPT. These models aim to achieve similar levels of performance as conventional transformer-based LLMs, but with smaller model sizes and faster training times.
By using techniques like parallel processing and compressed representations, the researchers were able to create LLMs that are more efficient and resource-friendly, without sacrificing too much in terms of the model's capabilities. This could be particularly useful for deploying LLMs in edge applications or resource-constrained environments, where smaller and faster models are often preferred.
The researchers have also made the model weights and codebase publicly available, which should help support further research and development in this area. This could lead to the creation of more efficient and accessible LLMs that can be used in a wider range of applications.
Technical Explanation
The paper introduces three new variants of the decoder-only transformer architecture for large language models (LLMs): ParallelGPT (p-gpt), LinearlyCompressedGPT (lc-gpt), and ConvCompressedGPT (cc-gpt).
The key modifications made to the traditional transformer architecture include:
-
ParallelGPT (p-gpt): This variant uses a parallel attention mechanism, where the attention computations are performed in parallel across different dimensions of the input, rather than sequentially. This can lead to faster inference times without sacrificing performance.
-
LinearlyCompressedGPT (lc-gpt): This model uses a linearly compressed representation of the input, effectively reducing the dimensionality of the input while preserving the essential information. This helps to reduce the overall model size and complexity.
-
ConvCompressedGPT (cc-gpt): This variant employs a convolutional compression layer, which can learn a more efficient representation of the input data compared to the traditional linear compression used in lc-gpt. This can further reduce the model size and improve performance.
The researchers evaluated these models on code generation tasks and found that they were able to achieve comparable performance to conventional transformer-based LLMs, while benefiting from reduced model sizes and faster training times. This suggests that these techniques could be useful for efficiently distilling LLMs for edge applications or accelerating the training of transformer models in general.
Critical Analysis
The paper presents a promising approach for reducing the size and improving the efficiency of large language models, which could have significant implications for the widespread deployment of these models in various applications.
However, the researchers acknowledge that the proposed models may not be able to match the performance of the largest and most complex transformer-based LLMs, particularly on tasks that require the full expressive power of these models. Additionally, the researchers note that further research is needed to explore the generalizability of these techniques to other types of tasks and datasets.
It would also be interesting to see how these models perform in terms of their ability to handle out-of-distribution data, their robustness to adversarial attacks, and their interpretability – areas that are often important considerations for real-world deployment of LLMs.
Overall, this research represents an important step towards creating more efficient and accessible large language models, and the open-sourcing of the model weights and codebase is a valuable contribution that should help to advance the field further.
Conclusion
This study introduces three new variants of the decoder-only transformer architecture for large language models (LLMs): ParallelGPT, LinearlyCompressedGPT, and ConvCompressedGPT. These models aim to achieve comparable performance to conventional transformer-based LLMs while benefiting from reduced model sizes and faster training times.
The key innovations include the use of parallel attention mechanisms, linearly compressed representations, and convolutional compression layers, which help to improve the efficiency of the models without sacrificing too much in terms of their capabilities.
By open-sourcing the model weights and codebase, the researchers have made it easier for others to build upon this work and explore further advancements in the area of efficient and accessible large language models. This could lead to the development of LLMs that are more suitable for deployment in edge applications, resource-constrained environments, and a wider range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
A Survey on Transformer Compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
0
0
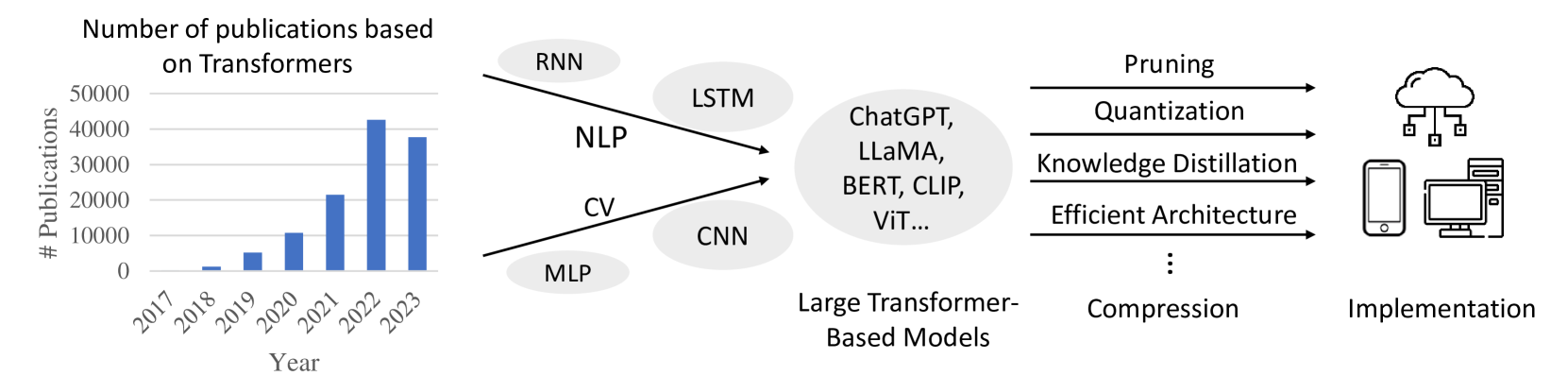
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
4/9/2024
A Primer on the Inner Workings of Transformer-based Language Models
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, Marta R. Costa-juss`a
0
0
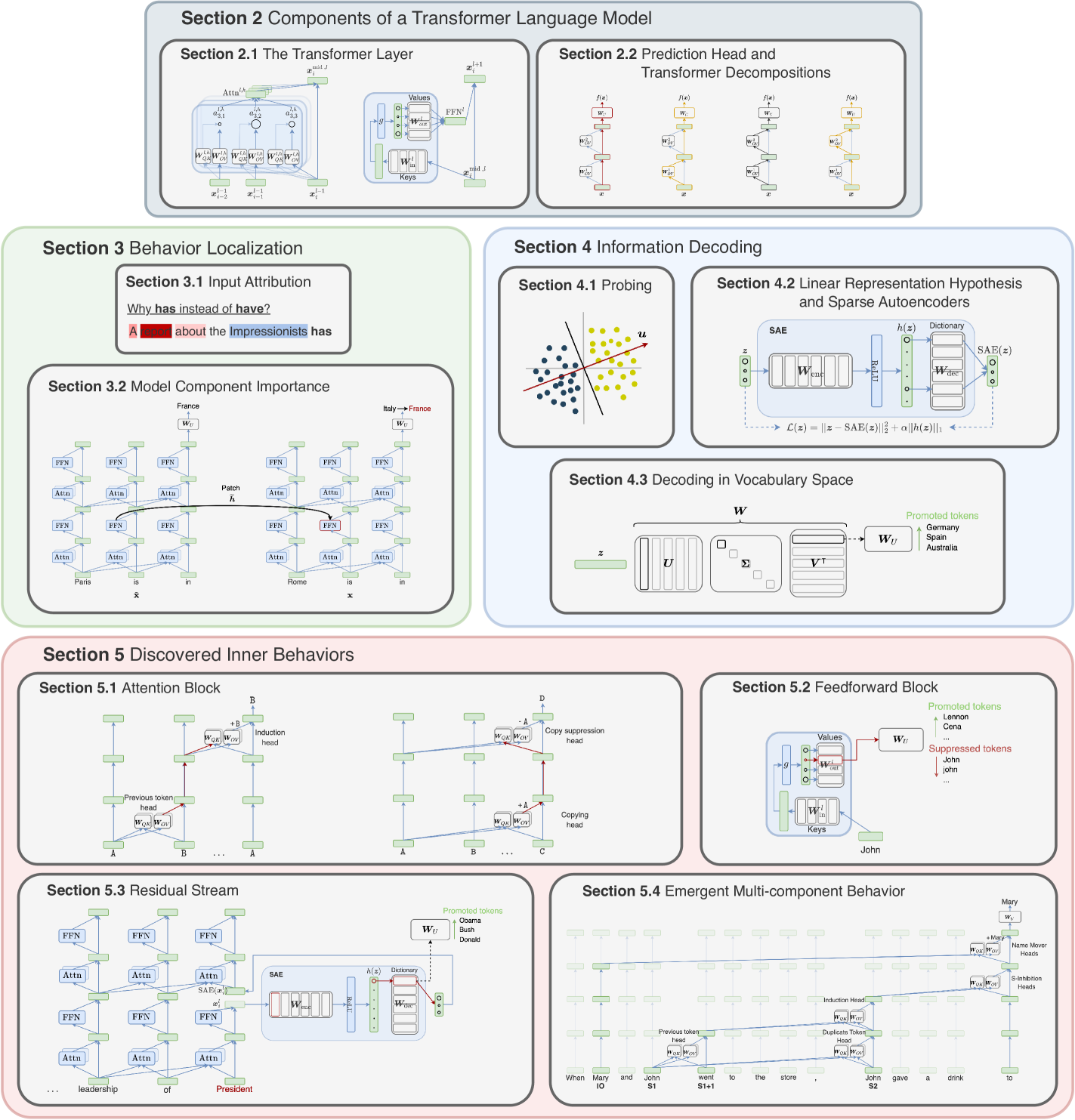
The rapid progress of research aimed at interpreting the inner workings of advanced language models has highlighted a need for contextualizing the insights gained from years of work in this area. This primer provides a concise technical introduction to the current techniques used to interpret the inner workings of Transformer-based language models, focusing on the generative decoder-only architecture. We conclude by presenting a comprehensive overview of the known internal mechanisms implemented by these models, uncovering connections across popular approaches and active research directions in this area.
5/3/2024
👨🏫
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
0
0
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
5/3/2024