Efficient Extraction of Noise-Robust Discrete Units from Self-Supervised Speech Models

0
Sign in to get full access
Overview
- The paper proposes an efficient method for extracting noise-robust discrete units from self-supervised speech models.
- The discrete units can be used as building blocks for various speech applications, such as speech recognition, synthesis, and translation.
- The authors demonstrate the effectiveness of their approach on multiple benchmarks, showing that the extracted discrete units outperform existing methods in terms of noise robustness and downstream task performance.
Plain English Explanation
The paper presents a new way to extract noise-resistant building blocks from self-taught speech models. These building blocks, called discrete units, can be used as the foundation for various speech-related applications, like speech recognition, speech generation, and speech translation.
The key idea is to develop an efficient method to extract these discrete units from self-supervised speech models. Self-supervised models are trained on large amounts of unlabeled speech data, allowing them to learn patterns and representations that are useful for a variety of tasks without the need for manual labeling.
The authors demonstrate that the discrete units extracted using their approach perform better than existing methods, especially in noisy environments. This is important because real-world speech often includes background noise, which can degrade the performance of speech systems. By using the noise-robust discrete units, the authors show that their approach can maintain high performance even in challenging, noisy conditions.
Technical Explanation
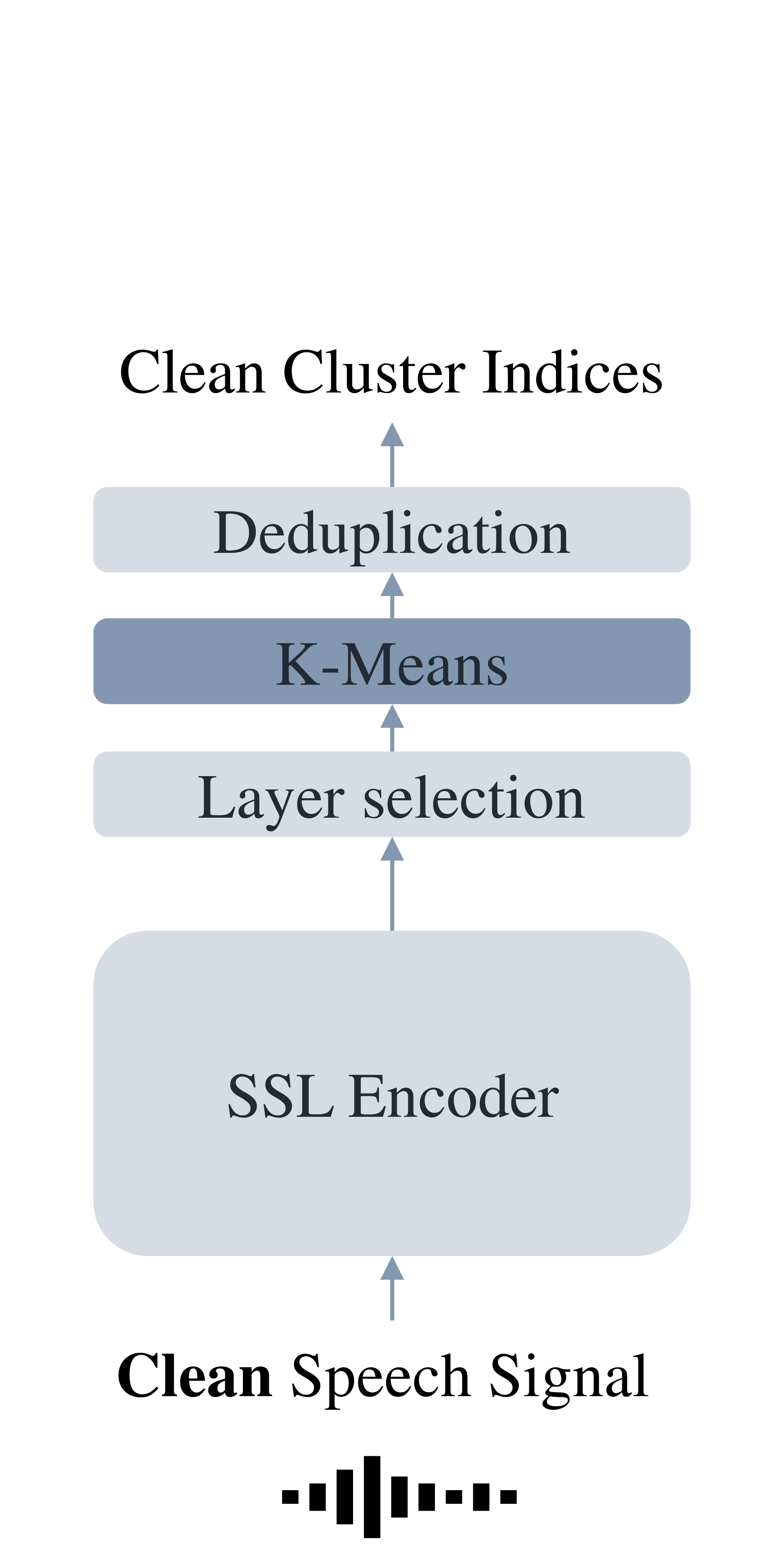
The paper introduces a novel method for efficiently extracting noise-robust discrete units from self-supervised speech models. The discrete units are learned in an unsupervised manner, without the need for manual labeling of the speech data.
The authors train a self-supervised speech model using a contrastive learning objective, which encourages the model to learn representations that are invariant to noise and other speech distortions. They then extract the discrete units by clustering the learned representations and assigning each input speech frame to the closest cluster centroid.
To improve the noise robustness of the discrete units, the authors fine-tune the self-supervised model using a multi-task objective, which combines the original contrastive learning loss with an auxiliary loss that encourages the model to predict the discrete unit assignments even in the presence of noise.
The authors evaluate the extracted discrete units on several downstream speech tasks, including speech recognition, speech synthesis, and speech translation. They show that the noise-robust discrete units outperform existing methods in terms of task performance, especially in noisy conditions.
Critical Analysis
The paper presents a compelling approach for extracting noise-robust discrete units from self-supervised speech models. The authors' focus on noise robustness is particularly important, as real-world speech often includes background noise that can degrade the performance of speech systems.
One potential limitation of the work is that the evaluation is primarily focused on standard speech benchmarks, which may not fully capture the practical challenges of deploying speech systems in the real world. It would be interesting to see how the discrete units perform in more diverse and realistic scenarios, such as conversational speech or speech from non-native speakers.
Additionally, the paper does not provide much insight into the internal representations learned by the self-supervised model or the clustering algorithm used to extract the discrete units. A more in-depth analysis of these components could help understand the strengths and weaknesses of the approach and guide future improvements.
Overall, the paper makes a valuable contribution to the field of self-supervised speech representation learning, and the noise-robust discrete units could have significant practical applications in a wide range of speech-based technologies.
Conclusion
The paper presents a novel and efficient method for extracting noise-robust discrete units from self-supervised speech models. The authors demonstrate the effectiveness of their approach on multiple speech benchmarks, showing that the discrete units outperform existing methods in terms of noise robustness and downstream task performance.
The noise-robust discrete units could serve as building blocks for a variety of speech applications, such as speech recognition, speech synthesis, and speech translation. This work represents an important step towards developing more robust and practical speech systems that can operate reliably in real-world, noisy environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Extraction of Noise-Robust Discrete Units from Self-Supervised Speech Models
Jakob Poncelet, Yujun Wang, Hugo Van hamme
Continuous speech can be converted into a discrete sequence by deriving discrete units from the hidden features of self-supervised learned (SSL) speech models. Although SSL models are becoming larger and trained on more data, they are often sensitive to real-life distortions like additive noise or reverberation, which translates to a shift in discrete units. We propose a parameter-efficient approach to generate noise-robust discrete units from pre-trained SSL models by training a small encoder-decoder model, with or without adapters, to simultaneously denoise and discretise the hidden features of the SSL model. The model learns to generate a clean discrete sequence for a noisy utterance, conditioned on the SSL features. The proposed denoiser outperforms several pre-training methods on the tasks of noisy discretisation and noisy speech recognition, and can be finetuned to the target environment with a few recordings of unlabeled target data.
Read more9/5/2024

0
DiscreteSLU: A Large Language Model with Self-Supervised Discrete Speech Units for Spoken Language Understanding
Suwon Shon, Kwangyoun Kim, Yi-Te Hsu, Prashant Sridhar, Shinji Watanabe, Karen Livescu
The integration of pre-trained text-based large language models (LLM) with speech input has enabled instruction-following capabilities for diverse speech tasks. This integration requires the use of a speech encoder, a speech adapter, and an LLM, trained on diverse tasks. We propose the use of discrete speech units (DSU), rather than continuous-valued speech encoder outputs, that are converted to the LLM token embedding space using the speech adapter. We generate DSU using a self-supervised speech encoder followed by k-means clustering. The proposed model shows robust performance on speech inputs from seen/unseen domains and instruction-following capability in spoken question answering. We also explore various types of DSU extracted from different layers of the self-supervised speech encoder, as well as Mel frequency Cepstral Coefficients (MFCC). Our findings suggest that the ASR task and datasets are not crucial in instruction-tuning for spoken question answering tasks.
Read more6/14/2024

0
How Should We Extract Discrete Audio Tokens from Self-Supervised Models?
Pooneh Mousavi, Jarod Duret, Salah Zaiem, Luca Della Libera, Artem Ploujnikov, Cem Subakan, Mirco Ravanelli
Discrete audio tokens have recently gained attention for their potential to bridge the gap between audio and language processing. Ideal audio tokens must preserve content, paralinguistic elements, speaker identity, and many other audio details. Current audio tokenization methods fall into two categories: Semantic tokens, acquired through quantization of Self-Supervised Learning (SSL) models, and Neural compression-based tokens (codecs). Although previous studies have benchmarked codec models to identify optimal configurations, the ideal setup for quantizing pretrained SSL models remains unclear. This paper explores the optimal configuration of semantic tokens across discriminative and generative tasks. We propose a scalable solution to train a universal vocoder across multiple SSL layers. Furthermore, an attention mechanism is employed to identify task-specific influential layers, enhancing the adaptability and performance of semantic tokens in diverse audio applications.
Read more6/18/2024
🗣️
0
Compact Speech Translation Models via Discrete Speech Units Pretraining
Tsz Kin Lam, Alexandra Birch, Barry Haddow
We propose a pretraining method to use Self-Supervised Speech (SSS) model to creating more compact Speech-to-text Translation. In contrast to using the SSS model for initialization, our method is more suitable to memory constrained scenario such as on-device deployment. Our method is based on Discrete Speech Units (DSU) extracted from the SSS model. In the first step, our method pretrains two smaller encoder-decoder models on 1) Filterbank-to-DSU (Fbk-to-DSU) and 2) DSU-to-Translation (DSU-to-Trl) data respectively. The DSU thus become the distillation inputs of the smaller models. Subsequently, the encoder from the Fbk-to-DSU model and the decoder from the DSU-to-Trl model are taken to initialise the compact model. Finally, the compact model is finetuned on the paired Fbk-Trl data. In addition to being compact, our method requires no transcripts, making it applicable to low-resource settings. It also avoids speech discretization in inference and is more robust to the DSU tokenization. Evaluation on CoVoST-2 (X-En) shows that our method has consistent improvement over the baseline in three metrics while being compact i.e., only half the SSS model size.
Read more6/27/2024