Compact Speech Translation Models via Discrete Speech Units Pretraining

0
🗣️
Sign in to get full access
Overview
- This paper explores a novel approach for training compact speech translation models using discrete speech units.
- The proposed method involves pretraining the model on a large corpus of transcribed speech data, using discrete speech units to represent the audio input.
- The authors demonstrate that this pretraining strategy can lead to significant improvements in speech translation performance, while also reducing the model size and computational requirements.
Plain English Explanation
The paper presents a new way to build speech translation models that are smaller and more efficient, without sacrificing performance. The key idea is to preprocess the audio input into a set of discrete speech units, which act as a compressed representation of the speech signal.
By training the speech translation model to work with these discrete units, rather than the raw audio, the authors find that the model can achieve high-quality translations while using fewer parameters and less computational resources. This is particularly important for applications where model size and efficiency are critical, such as on mobile devices or in low-power settings.
The pretraining approach involves first training a model to recognize and encode the audio input into these discrete speech units, which capture the essential features of the speech signal. The speech translation model is then trained on top of this pre-trained discrete unit representation, allowing it to leverage the learned speech features without having to learn them from scratch.
The authors show that this strategy leads to significant improvements in translation quality compared to models trained directly on raw audio or with other pretraining techniques. It also results in smaller and more efficient models, which could enable new applications and deployment scenarios for speech translation technology.
Technical Explanation
The paper proposes a novel pretraining strategy for building compact speech translation models. The key idea is to first train a model to convert the raw audio input into a sequence of discrete speech units, which serve as a compressed representation of the speech signal.
This discrete unit pretraining is performed using a large corpus of transcribed speech data, leveraging techniques from the discreteSLU and Can-we-achieve-high-quality-direct-speech papers. The resulting discrete unit encoder is then used to preprocess the audio input for the speech translation model, which is trained on top of this representation.
The authors show that this pretraining approach leads to significant performance gains compared to models trained directly on raw audio or with other pretraining techniques, such as textless-acoustic-model-self-supervised-distillation-noise and transferable-speech-to-text-large-language-model. Furthermore, the resulting speech translation models are more compact and efficient, with reduced model size and computational requirements.
The authors also explore the potential of using the discrete units for zero-shot text-to-speech translation, as demonstrated in the ditto-tts-efficient-scalable-zero-shot-text work, further enhancing the versatility of the proposed approach.
Critical Analysis
The paper presents a promising approach for building compact and efficient speech translation models, with several strengths and potential limitations:
Strengths:
- The use of discrete speech units as a compressed representation of the audio input is a novel and effective strategy, leading to significant performance gains.
- The pretraining approach allows the speech translation model to leverage the learned speech features without having to learn them from scratch, resulting in more efficient models.
- The potential for zero-shot text-to-speech translation using the discrete units is an exciting avenue for future research.
Limitations:
- The paper does not provide a thorough analysis of the impact of different discrete unit vocabulary sizes and their trade-offs in terms of translation quality and model efficiency.
- The experiments are limited to a single language pair (English-German), and it would be valuable to see how the approach generalizes to a wider range of language combinations.
- The paper does not delve into the interpretability of the learned discrete speech units and how they relate to linguistic or acoustic concepts.
Overall, the paper presents a compelling approach that could have important implications for the development of practical and deployable speech translation systems. Further research exploring the nuances of the discrete unit pretraining and its broader applicability would be valuable.
Conclusion
This paper introduces a novel pretraining strategy for building compact and efficient speech translation models. By leveraging discrete speech units as a compressed representation of the audio input, the authors demonstrate significant improvements in translation quality and model size/computational requirements compared to other approaches.
The discrete unit pretraining allows the speech translation model to effectively leverage learned speech features, without having to learn them from scratch. This, in turn, enables the development of smaller and more efficient models that could be deployed in a wider range of real-world applications, from mobile devices to low-power edge computing scenarios.
The potential for using the discrete units for zero-shot text-to-speech translation further highlights the versatility of the proposed approach and its broader implications for the field of speech and language processing. As the demand for high-quality, low-latency, and energy-efficient speech technologies continues to grow, this work represents an important step forward in addressing these challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Compact Speech Translation Models via Discrete Speech Units Pretraining
Tsz Kin Lam, Alexandra Birch, Barry Haddow
We propose a pretraining method to use Self-Supervised Speech (SSS) model to creating more compact Speech-to-text Translation. In contrast to using the SSS model for initialization, our method is more suitable to memory constrained scenario such as on-device deployment. Our method is based on Discrete Speech Units (DSU) extracted from the SSS model. In the first step, our method pretrains two smaller encoder-decoder models on 1) Filterbank-to-DSU (Fbk-to-DSU) and 2) DSU-to-Translation (DSU-to-Trl) data respectively. The DSU thus become the distillation inputs of the smaller models. Subsequently, the encoder from the Fbk-to-DSU model and the decoder from the DSU-to-Trl model are taken to initialise the compact model. Finally, the compact model is finetuned on the paired Fbk-Trl data. In addition to being compact, our method requires no transcripts, making it applicable to low-resource settings. It also avoids speech discretization in inference and is more robust to the DSU tokenization. Evaluation on CoVoST-2 (X-En) shows that our method has consistent improvement over the baseline in three metrics while being compact i.e., only half the SSS model size.
Read more6/27/2024

0
DiscreteSLU: A Large Language Model with Self-Supervised Discrete Speech Units for Spoken Language Understanding
Suwon Shon, Kwangyoun Kim, Yi-Te Hsu, Prashant Sridhar, Shinji Watanabe, Karen Livescu
The integration of pre-trained text-based large language models (LLM) with speech input has enabled instruction-following capabilities for diverse speech tasks. This integration requires the use of a speech encoder, a speech adapter, and an LLM, trained on diverse tasks. We propose the use of discrete speech units (DSU), rather than continuous-valued speech encoder outputs, that are converted to the LLM token embedding space using the speech adapter. We generate DSU using a self-supervised speech encoder followed by k-means clustering. The proposed model shows robust performance on speech inputs from seen/unseen domains and instruction-following capability in spoken question answering. We also explore various types of DSU extracted from different layers of the self-supervised speech encoder, as well as Mel frequency Cepstral Coefficients (MFCC). Our findings suggest that the ASR task and datasets are not crucial in instruction-tuning for spoken question answering tasks.
Read more6/14/2024
0
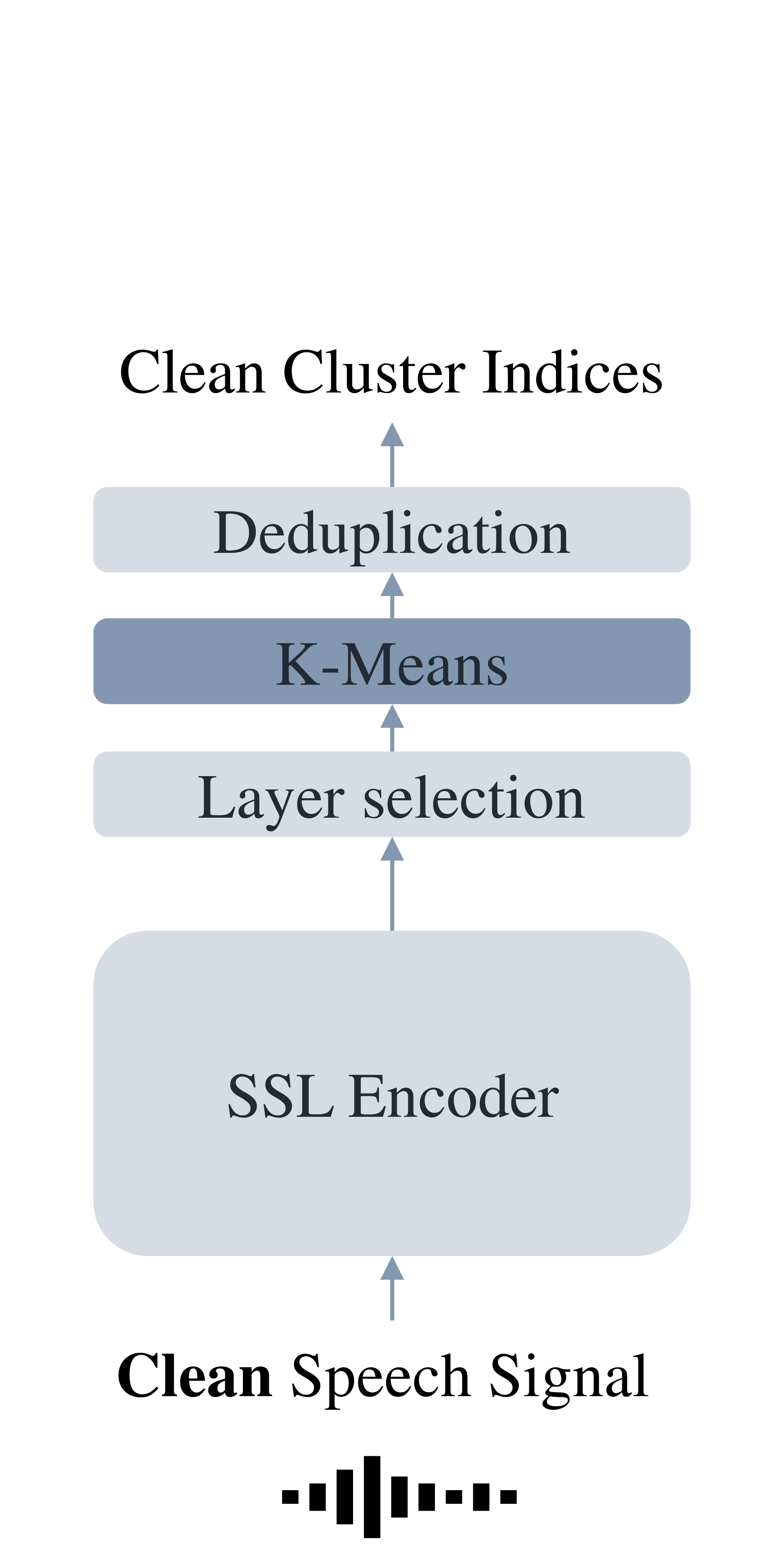
Efficient Extraction of Noise-Robust Discrete Units from Self-Supervised Speech Models
Jakob Poncelet, Yujun Wang, Hugo Van hamme
Continuous speech can be converted into a discrete sequence by deriving discrete units from the hidden features of self-supervised learned (SSL) speech models. Although SSL models are becoming larger and trained on more data, they are often sensitive to real-life distortions like additive noise or reverberation, which translates to a shift in discrete units. We propose a parameter-efficient approach to generate noise-robust discrete units from pre-trained SSL models by training a small encoder-decoder model, with or without adapters, to simultaneously denoise and discretise the hidden features of the SSL model. The model learns to generate a clean discrete sequence for a noisy utterance, conditioned on the SSL features. The proposed denoiser outperforms several pre-training methods on the tasks of noisy discretisation and noisy speech recognition, and can be finetuned to the target environment with a few recordings of unlabeled target data.
Read more9/5/2024
🏋️
0
Textless Unit-to-Unit training for Many-to-Many Multilingual Speech-to-Speech Translation
Minsu Kim, Jeongsoo Choi, Dahun Kim, Yong Man Ro
This paper proposes a textless training method for many-to-many multilingual speech-to-speech translation that can also benefit the transfer of pre-trained knowledge to text-based systems, text-to-speech synthesis and text-to-speech translation. To this end, we represent multilingual speech with speech units that are the discretized representations of speech features derived from a self-supervised speech model. By treating the speech units as pseudo-text, we can focus on the linguistic content of the speech, which can be easily associated with both speech and text modalities at the phonetic level information. By setting both the inputs and outputs of our learning problem as speech units, we propose to train an encoder-decoder model in a many-to-many spoken language translation setting, namely Unit-to-Unit Translation (UTUT). Specifically, the encoder is conditioned on the source language token to correctly understand the input spoken language, while the decoder is conditioned on the target language token to generate the translated speech in the target language. Therefore, during the training, the model can build the knowledge of how languages are comprehended and how to relate them to different languages. Since speech units can be easily associated from both audio and text by quantization and phonemization respectively, the trained model can easily transferred to text-related tasks, even if it is trained in a textless manner. We demonstrate that the proposed UTUT model can be effectively utilized not only for Speech-to-Speech Translation (S2ST) but also for multilingual Text-to-Speech Synthesis (T2S) and Text-to-Speech Translation (T2ST), requiring only minimal fine-tuning steps on text inputs. By conducting comprehensive experiments encompassing various languages, we validate the efficacy of the proposed method across diverse multilingual tasks.
Read more8/20/2024