Efficient Large Language Models: A Survey
2312.03863
0
0
💬
Abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
Create account to get full access
Overview
- This paper provides a comprehensive survey of research on efficient large language models (LLMs).
- LLMs have shown remarkable capabilities in tasks like natural language understanding and generation, but their resource-intensive nature highlights the need for efficient techniques.
- The survey organizes the literature into a taxonomy of three main categories: model-centric, data-centric, and framework-centric approaches to efficient LLMs.
- The authors have created a GitHub repository to track the papers featured in the survey and incorporate new research as it emerges.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like language. These models have demonstrated impressive abilities in a variety of important tasks, such as natural language understanding and generation. This means they have the potential to make a significant impact on our society.
However, the development and use of LLMs requires a lot of computing power and other resources, which can be a challenge. This paper aims to provide a comprehensive overview of the research being done to make LLMs more efficient, so they can be used more widely and effectively.
The paper organizes the research into three main categories:
- Model-centric approaches: These focus on improving the efficiency of the LLM architecture itself, such as by reducing the model size or complexity.
- Data-centric approaches: These focus on optimizing the data used to train the LLMs, such as by reducing the amount of data needed or making better use of the available data.
- Framework-centric approaches: These focus on the overall systems and frameworks used to deploy and run LLMs, such as by improving the efficiency of the inference process.
The authors have also created a GitHub repository to help keep track of the research papers covered in the survey and incorporate new work as it becomes available. This should be a valuable resource for researchers and practitioners working in this important and exciting field.
Technical Explanation
The paper presents a comprehensive survey of research on efficient large language models (LLMs). LLMs have demonstrated remarkable capabilities in tasks such as natural language understanding and generation, making them potentially transformative technologies. However, the considerable resources required to develop and deploy LLMs, including computational power and data, highlight the strong need for effective techniques to improve their efficiency.
The authors organize the literature on efficient LLMs into a taxonomy with three main categories:
- Model-centric approaches: These focus on improving the efficiency of the LLM architecture itself. Strategies in this category include model compression, parameter sharing, and architecture search.
- Data-centric approaches: These focus on optimizing the data used to train the LLMs. Techniques include data distillation, data augmentation, and efficient data collection.
- Framework-centric approaches: These focus on the overall systems and frameworks used to deploy and run LLMs. Approaches in this category include efficient inference, distributed training, and hardware-software co-design.
The survey provides a detailed review of the key ideas, methodologies, and insights from representative papers in each of these categories. For example, the survey on efficient inference for large language models discusses techniques like quantization, pruning, and knowledge distillation to improve the inference efficiency of LLMs.
The authors have also created a GitHub repository to organize the papers featured in the survey and facilitate ongoing updates as new research emerges. This resource should be valuable for researchers and practitioners working on efficient LLMs.
Critical Analysis
The survey provides a comprehensive and well-structured overview of the current research on efficient large language models (LLMs). By organizing the literature into three main categories (model-centric, data-centric, and framework-centric), the authors offer a clear and systematic way for readers to understand the different approaches being explored.
One potential limitation of the survey is that it may not capture the most recent developments in the field, as the research landscape is rapidly evolving. However, the authors' plan to maintain the accompanying GitHub repository should help address this by incorporating new papers as they are published.
Another area that could be explored further is the practical implications and real-world applications of the efficient LLM techniques discussed in the survey. While the paper touches on the potential impact of LLMs, a deeper analysis of the specific use cases and challenges of deploying these models in various domains would provide valuable insights for both researchers and practitioners.
Additionally, the survey could benefit from a more critical evaluation of the strengths, weaknesses, and trade-offs of the different efficient LLM approaches. This would help readers understand the nuances and limitations of the various techniques, and encourage them to think critically about the research and form their own opinions.
Conclusion
This survey provides a comprehensive and well-organized overview of the current research on efficient large language models (LLMs). By categorizing the literature into model-centric, data-centric, and framework-centric approaches, the authors offer a clear and systematic understanding of the different strategies being explored to address the efficiency challenges of these powerful AI models.
The creation of the accompanying GitHub repository is a valuable addition, as it will allow the survey to be continuously updated with new research, ensuring that it remains a relevant and useful resource for both researchers and practitioners working in this exciting and rapidly evolving field. As LLMs continue to demonstrate their potential to transform various domains, the importance of developing efficient techniques to deploy these models at scale will only grow. This survey provides a solid foundation for understanding and advancing the state of the art in efficient LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
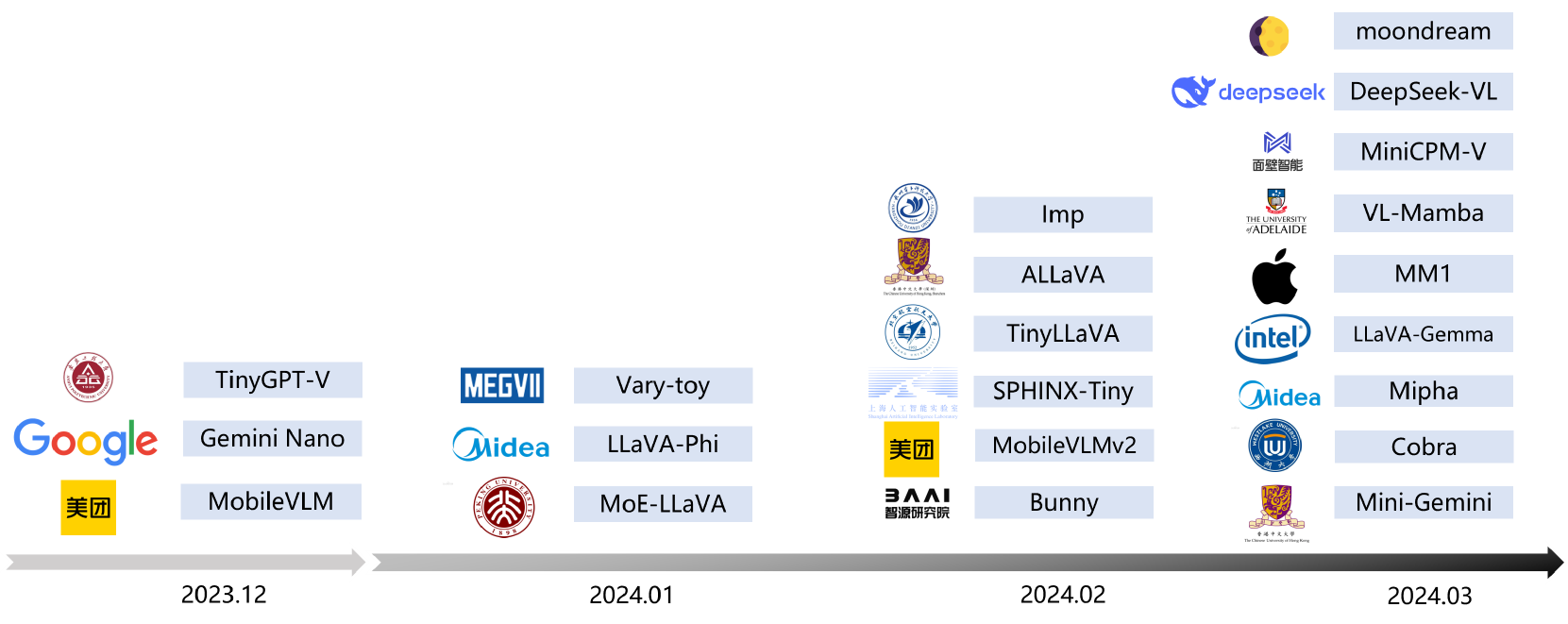
Efficient Multimodal Large Language Models: A Survey
Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, Yabiao Wang, Chengjie Wang, Lizhuang Ma
0
0
In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions. Please refer to our GitHub repository for more details: https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
5/20/2024
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Tianyu Ding, Tianyi Chen, Haidong Zhu, Jiachen Jiang, Yiqi Zhong, Jinxin Zhou, Guangzhi Wang, Zhihui Zhu, Ilya Zharkov, Luming Liang
0
0
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
4/22/2024

A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
0
0
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
6/4/2024
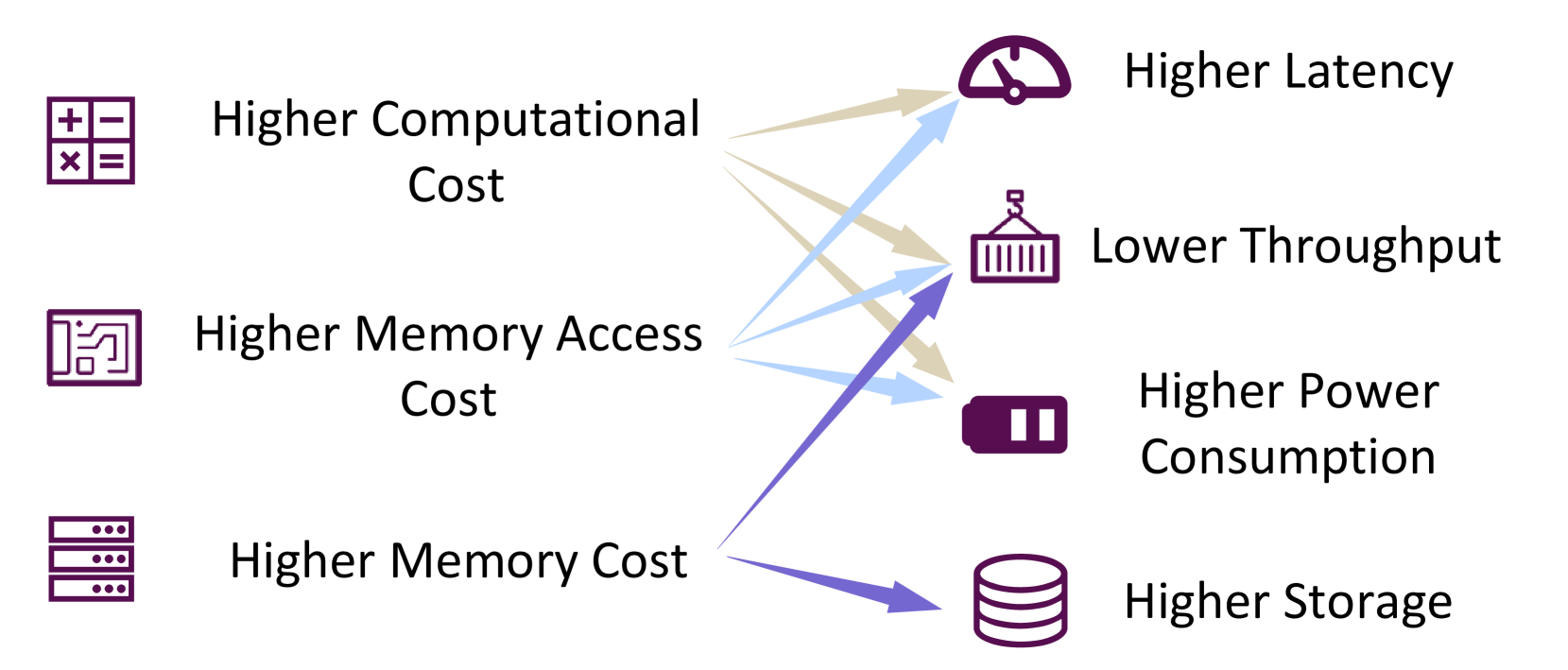
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
6/11/2024