Efficient Multimodal Large Language Models: A Survey

0
Sign in to get full access
Overview
- This paper provides a comprehensive survey of efficient multimodal large language models, which are advanced AI systems that can understand and generate human-like text, images, and other media.
- The authors examine the latest architectural innovations, training techniques, and inference optimizations that allow these models to operate efficiently, even on resource-constrained devices.
- The survey covers a range of topics, including efficient multimodal large language models, multimodal large language-vision models, large language models for multilingualism, and efficient inference techniques.
Plain English Explanation
Large language models are powerful AI systems that can understand and generate human-like text, much like how our own brains process and produce language. These models have become increasingly advanced, with the ability to also work with images, video, and other types of media, known as multimodal capabilities.
However, these large, complex models can be computationally intensive and require significant computing power to run efficiently. This paper explores the latest innovations that are making these multimodal language models more efficient, allowing them to run on a wider range of devices, from powerful servers to everyday smartphones.
The authors examine new architectural designs, training techniques, and optimization methods that enable these models to perform their tasks without consuming excessive amounts of memory or energy. This includes methods for compressing the models, accelerating their inference (the process of generating new text or media), and making them more flexible and adaptable to different hardware and software environments.
By making these large language models more efficient, the researchers are helping to unlock their potential for a wide range of real-world applications, from smart assistants and language translation to content creation and multimodal analysis. This could lead to more accessible and impactful AI-powered technologies that can benefit people in their daily lives.
Technical Explanation
The paper provides a comprehensive survey of the latest advancements in efficient multimodal large language models, which are advanced AI systems capable of understanding and generating human-like text, images, and other media.
The authors examine the architectural innovations that are enabling these models to operate more efficiently, such as the use of lightweight transformer modules, sparse attention mechanisms, and other techniques that reduce the computational and memory requirements of the models. The paper also covers training techniques, like distillation and knowledge transfer, that can help optimize the models for efficient inference.
In addition, the survey delves into efficient inference methods, which are the techniques used to generate new text, images, or other outputs from the trained models. This includes quantization, pruning, and other optimization approaches that can speed up the inference process and make it more resource-efficient, even on resource-constrained devices.
The paper also explores the latest advancements in multimodal large language-vision models, which combine large language models with computer vision capabilities, and large language models for multilingualism, which can understand and generate text in multiple languages.
Critical Analysis
The paper provides a thorough and well-researched overview of the latest developments in efficient multimodal large language models. The authors have done an excellent job of synthesizing the key architectural innovations, training techniques, and inference optimization methods that are enabling these models to become more computationally efficient and accessible.
One limitation of the paper is that it does not delve deeply into the potential societal and ethical implications of these advanced AI systems. As these models become more powerful and ubiquitous, it will be important to consider their impact on issues like privacy, bias, and the displacement of human labor.
Additionally, the paper could have provided more critical analysis of the trade-offs and limitations of the various efficiency-enhancing techniques discussed. For example, while techniques like model compression can improve efficiency, they may also result in a loss of model performance or accuracy.
Overall, this paper serves as an excellent resource for researchers and practitioners working in the field of efficient multimodal large language models. By highlighting the latest advancements and providing a comprehensive technical overview, the authors have made a valuable contribution to the ongoing development of these transformative AI technologies.
Conclusion
This survey paper provides a detailed and up-to-date look at the latest innovations in efficient multimodal large language models, which are AI systems capable of understanding and generating human-like text, images, and other media. By exploring the architectural designs, training techniques, and inference optimization methods that are enabling these models to operate more efficiently, the authors have shed light on the key developments that are making these advanced AI systems more accessible and impactful.
As these efficient multimodal large language models continue to evolve, they have the potential to unlock a wide range of real-world applications, from smart assistants and language translation to content creation and multimodal analysis. By making these powerful AI technologies more efficient and resource-friendly, the research community is helping to pave the way for more widespread adoption and positive societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Multimodal Large Language Models: A Survey
Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, Yabiao Wang, Chengjie Wang, Lizhuang Ma
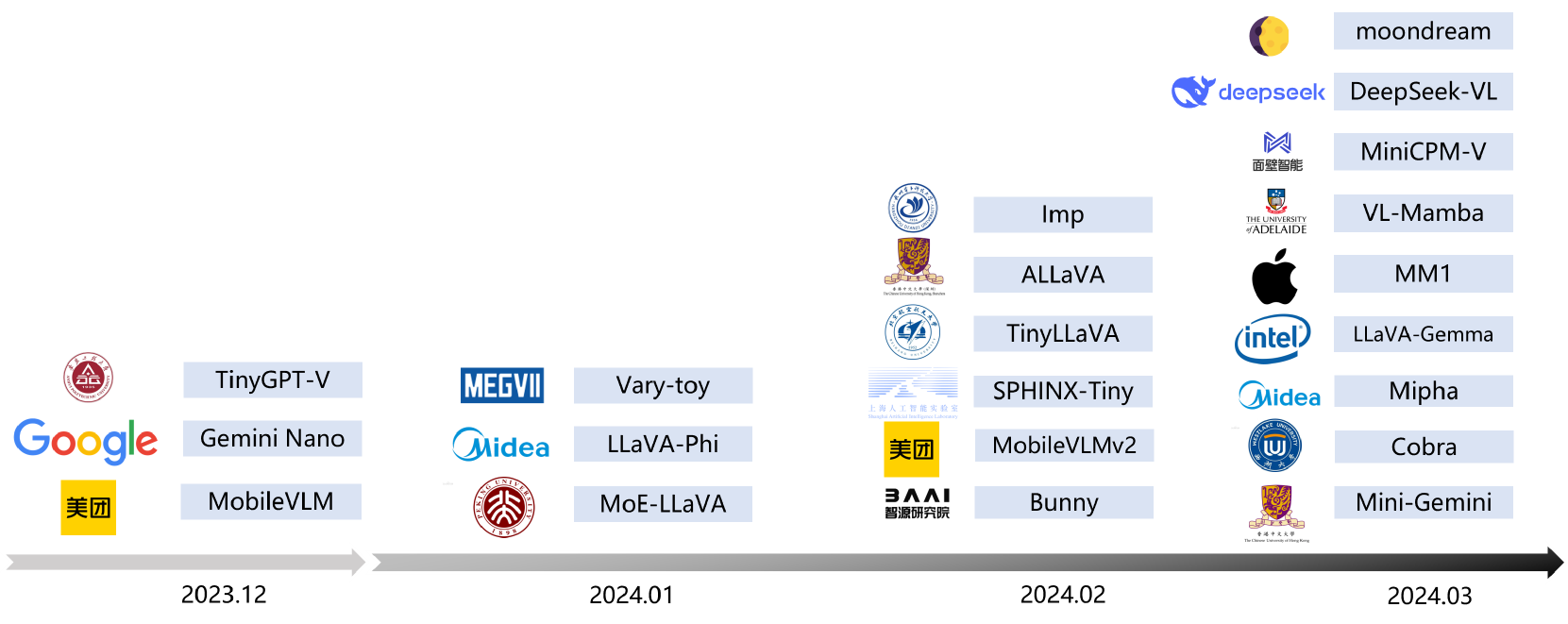
In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions. Please refer to our GitHub repository for more details: https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
Read more8/12/2024
💬
0
Efficient Large Language Models: A Survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
Read more5/24/2024

0
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
Jiaqi Wang, Hanqi Jiang, Yiheng Liu, Chong Ma, Xu Zhang, Yi Pan, Mengyuan Liu, Peiran Gu, Sichen Xia, Wenjun Li, Yutong Zhang, Zihao Wu, Zhengliang Liu, Tianyang Zhong, Bao Ge, Tuo Zhang, Ning Qiang, Xintao Hu, Xi Jiang, Xin Zhang, Wei Zhang, Dinggang Shen, Tianming Liu, Shu Zhang
In an era defined by the explosive growth of data and rapid technological advancements, Multimodal Large Language Models (MLLMs) stand at the forefront of artificial intelligence (AI) systems. Designed to seamlessly integrate diverse data types-including text, images, videos, audio, and physiological sequences-MLLMs address the complexities of real-world applications far beyond the capabilities of single-modality systems. In this paper, we systematically sort out the applications of MLLM in multimodal tasks such as natural language, vision, and audio. We also provide a comparative analysis of the focus of different MLLMs in the tasks, and provide insights into the shortcomings of current MLLMs, and suggest potential directions for future research. Through these discussions, this paper hopes to provide valuable insights for the further development and application of MLLM.
Read more8/6/2024

0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024