A Survey on Efficient Inference for Large Language Models
2404.14294
0
0
Abstract
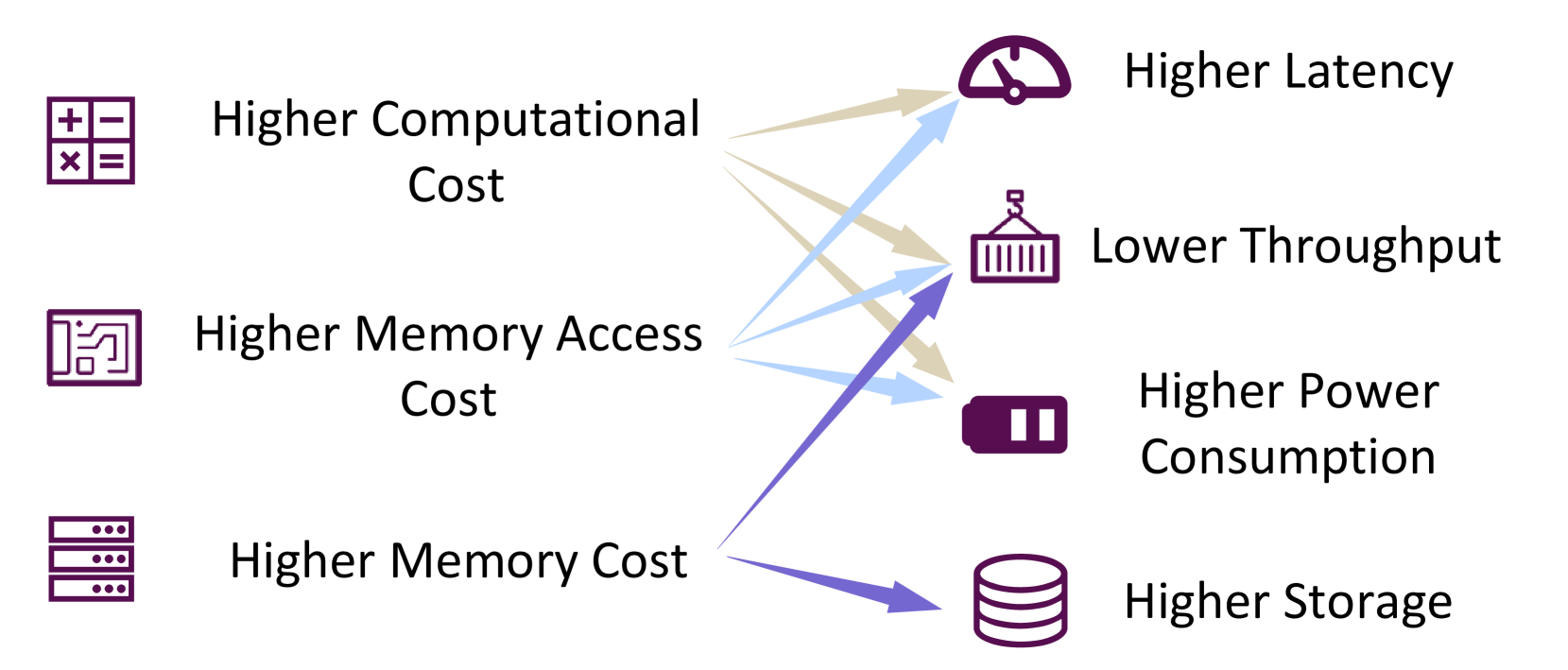
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a comprehensive survey on efficient inference techniques for large language models (LLMs).
- It covers a range of approaches, including model compression, efficient decoding, metric-aware inference, and planning-based inference.
- The paper also discusses speculative decoding for improving efficiency in multimodal LLMs.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful, but running them can be very computationally expensive and slow. This paper looks at different techniques researchers have developed to make LLM inference (the process of using a trained model to generate new text) more efficient and faster.
One approach is model compression, where the size of the LLM is reduced without losing too much accuracy. This allows the model to run faster on the same hardware. Another approach is efficient decoding, which focuses on optimizing the algorithms used to generate text from the LLM, rather than the model itself.
The paper also discusses metric-aware inference, which adapts the LLM's output to optimize for specific metrics, like brevity or fluency, without sacrificing overall quality. And planning-based inference uses techniques from AI planning to intelligently guide the text generation process.
Finally, the paper explores speculative decoding for multimodal LLMs, which can generate multiple possible outputs in parallel to improve efficiency.
Overall, this survey provides a comprehensive look at the latest techniques researchers are using to make large language models faster and more practical to use in real-world applications.
Technical Explanation
The paper begins by providing an overview of transformer-based LLMs, which form the foundation for many of the most powerful language models today. It then dives into the various approaches for efficient LLM inference:
Model Compression: Techniques like weight pruning, quantization, and knowledge distillation can reduce the size of LLMs without significant accuracy loss, enabling faster inference on the same hardware.
Efficient Decoding: Optimizations to the beam search and sampling algorithms used to generate text from LLMs can improve inference speed, such as using adaptive beam sizes or exploring the output space more intelligently.
Metric-Aware Inference: Rather than optimizing solely for perplexity, LLM inference can be tailored to optimize for specific metrics like brevity, fluency, or relevance using techniques like regression scoring.
Planning-Based Inference: Incorporating AI planning concepts can help guide the text generation process in a more efficient and targeted way, rather than relying on generic beam search.
For multimodal LLMs that handle both text and other modalities like images, the paper also explores Speculative Decoding, which generates multiple output hypotheses in parallel to improve overall efficiency.
Critical Analysis
The paper provides a comprehensive and well-structured overview of the current state of efficient inference techniques for large language models. It covers a wide range of approaches and discusses the strengths and limitations of each.
One potential area for further research mentioned in the paper is the need for more principled ways to evaluate the efficiency-accuracy tradeoffs of these techniques. The authors note that many of the proposed methods rely on heuristics or task-specific metrics, and a more unified framework for measuring efficiency could help drive the field forward.
Additionally, the paper acknowledges that most of the existing work has focused on English LLMs, and there is a need to explore the applicability of these techniques to models in other languages and modalities.
Overall, this survey serves as a valuable resource for researchers and practitioners working on improving the practicality and real-world deployability of large language models.
Conclusion
This paper presents a thorough examination of the latest techniques for making inference with large language models more efficient and practical. By exploring approaches like model compression, efficient decoding, metric-aware inference, and planning-based inference, the authors showcase the diverse range of strategies researchers are pursuing to address the computational challenges of LLMs.
The insights provided in this survey have the potential to significantly impact the field of natural language processing, enabling more widespread deployment of powerful language models in a wide range of applications, from chatbots and virtual assistants to content generation and language understanding systems. As LLMs continue to grow in scale and capability, the importance of developing efficient inference methods will only increase, making this paper a timely and valuable contribution to the research literature.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Tianyu Ding, Tianyi Chen, Haidong Zhu, Jiachen Jiang, Yiqi Zhong, Jinxin Zhou, Guangzhi Wang, Zhihui Zhu, Ilya Zharkov, Luming Liang
0
0
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
4/22/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
💬
Beyond the Speculative Game: A Survey of Speculative Execution in Large Language Models
Chen Zhang, Zhuorui Liu, Dawei Song
0
0
With the increasingly giant scales of (causal) large language models (LLMs), the inference efficiency comes as one of the core concerns along the improved performance. In contrast to the memory footprint, the latency bottleneck seems to be of greater importance as there can be billions of requests to a LLM (e.g., GPT-4) per day. The bottleneck is mainly due to the autoregressive innateness of LLMs, where tokens can only be generated sequentially during decoding. To alleviate the bottleneck, the idea of speculative execution, which originates from the field of computer architecture, is introduced to LLM decoding in a textit{draft-then-verify} style. Under this regime, a sequence of tokens will be drafted in a fast pace by utilizing some heuristics, and then the tokens shall be verified in parallel by the LLM. As the costly sequential inference is parallelized, LLM decoding speed can be significantly boosted. Driven by the success of LLMs in recent couple of years, a growing literature in this direction has emerged. Yet, there lacks a position survey to summarize the current landscape and draw a roadmap for future development of this promising area. To meet this demand, we present the very first survey paper that reviews and unifies literature of speculative execution in LLMs (e.g., blockwise parallel decoding, speculative decoding, etc.) in a comprehensive framework and a systematic taxonomy. Based on the taxonomy, we present a critical review and comparative analysis of the current arts. Finally we highlight various key challenges and future directions to further develop the area.
4/24/2024

Metric-aware LLM inference for regression and scoring
Michal Lukasik, Harikrishna Narasimhan, Aditya Krishna Menon, Felix Yu, Sanjiv Kumar
0
0
Large language models (LLMs) have demonstrated strong results on a range of NLP tasks. Typically, outputs are obtained via autoregressive sampling from the LLM's underlying distribution. Building on prior work on Minimum Bayes Risk Decoding, we show that this inference strategy can be suboptimal for a range of regression and scoring tasks, and associated evaluation metrics. As a remedy, we propose metric aware LLM inference: a decision theoretic approach optimizing for custom regression and scoring metrics at inference time. We report improvements over baselines on academic benchmarks and publicly available models.
4/5/2024