Efficient Multi-Objective Neural Architecture Search via Pareto Dominance-based Novelty Search

0

Sign in to get full access
Overview
- The paper presents a novel multi-objective neural architecture search (MONAS) method called Pareto Dominance-based Novelty Search (PDNS).
- PDNS aims to efficiently discover a diverse set of high-performing neural network architectures by leveraging a training-free novelty search approach.
- The key idea is to guide the search towards novel and high-performing architectures using Pareto dominance as the novelty metric, without the need for training.
Plain English Explanation
Efficient Multi-Objective Neural Architecture Search via Pareto Dominance-based Novelty Search tackles the challenge of finding the best neural network architectures for a given task. This is important because the right architecture can significantly improve the performance of machine learning models.
The researchers propose a method called Pareto Dominance-based Novelty Search (PDNS) that efficiently explores the space of possible neural network architectures. Instead of training each architecture and measuring its performance, which can be very computationally expensive, PDNS uses a training-free approach to identify novel and high-performing architectures.
The key idea is to use Pareto dominance as a novelty metric. Pareto dominance means that one architecture is considered "better" than another if it performs better on at least one objective (e.g., accuracy, inference time) without performing worse on any other objective. By searching for architectures that are novel in this Pareto sense, PDNS can discover a diverse set of high-performing neural network designs without the need for costly training.
Technical Explanation
Pareto Dominance-based Novelty Search (PDNS) is a multi-objective neural architecture search (MONAS) method that efficiently explores the space of possible neural network architectures. Unlike traditional MONAS approaches that require training each candidate architecture to evaluate its performance, PDNS uses a training-free novelty search strategy to identify novel and high-performing architectures.
The core of PDNS is the use of Pareto dominance as the novelty metric. Pareto dominance is a concept from multi-objective optimization, where one solution (architecture) is said to Pareto dominate another if it performs better on at least one objective (e.g., accuracy, inference time) without performing worse on any other objective. By searching for architectures that are novel in this Pareto sense, PDNS can discover a diverse set of high-performing neural network designs without the need for costly training.
The PDNS algorithm works as follows:
- Initialization: Start with an initial set of random neural network architectures.
- Novelty Evaluation: For each architecture, compute its novelty score based on Pareto dominance. Architectures that are not dominated by any others in the current population receive a higher novelty score.
- Selection: Select a subset of the most novel architectures to be the parents for the next generation.
- Mutation: Apply mutation operators to the selected parent architectures to generate the child architectures for the next generation.
- Repeat: Repeat steps 2-4 until the search is complete.
The authors demonstrate the effectiveness of PDNS on several benchmark datasets and show that it can discover a diverse set of high-performing neural network architectures more efficiently than traditional MONAS methods.
Critical Analysis
The paper presents a promising approach to multi-objective neural architecture search, but there are a few potential limitations and areas for further research:
-
Generalization: The authors only evaluate PDNS on a few benchmark datasets. It would be valuable to see how the method performs on a wider range of tasks and domains to assess its generalization capabilities.
-
Objective Selection: The choice of objectives (e.g., accuracy, inference time) can have a significant impact on the discovered architectures. The paper does not provide much guidance on how to select appropriate objectives for a given problem.
-
Computational Efficiency: While PDNS is more efficient than training-based MONAS methods, the novelty evaluation step still requires comparing each candidate architecture against the entire population. This could become computationally expensive as the search space grows larger.
-
Hybrid Approaches: Combining the training-free novelty search of PDNS with some limited training or other heuristics could potentially further improve the search efficiency and the quality of the discovered architectures.
Overall, the Pareto Dominance-based Novelty Search approach presented in this paper is a thoughtful and promising contribution to the field of multi-objective neural architecture search. The authors have identified an interesting way to leverage Pareto dominance as a novelty metric to guide the search, and the results demonstrate the potential of this approach. Further research to address the limitations and explore hybrid methods could lead to even more efficient and effective MONAS techniques.
Conclusion
Efficient Multi-Objective Neural Architecture Search via Pareto Dominance-based Novelty Search introduces a novel multi-objective neural architecture search (MONAS) method called Pareto Dominance-based Novelty Search (PDNS). PDNS aims to efficiently discover a diverse set of high-performing neural network architectures by using a training-free novelty search approach based on Pareto dominance.
The key innovation of PDNS is the use of Pareto dominance as the novelty metric, which allows the search to identify architectures that are novel and high-performing without the need for costly training. The results demonstrate the effectiveness of this approach on several benchmark datasets, and the paper highlights the potential of training-free MONAS methods to accelerate the development of efficient neural network architectures.
While the paper presents a promising contribution, there are also some potential limitations and areas for further research, such as exploring the generalization of PDNS, investigating the impact of objective selection, and considering hybrid approaches that combine training-free and training-based techniques. Overall, this work represents an important step forward in the field of multi-objective neural architecture search.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Multi-Objective Neural Architecture Search via Pareto Dominance-based Novelty Search
An Vo, Ngoc Hoang Luong
Neural Architecture Search (NAS) aims to automate the discovery of high-performing deep neural network architectures. Traditional objective-based NAS approaches typically optimize a certain performance metric (e.g., prediction accuracy), overlooking large parts of the architecture search space that potentially contain interesting network configurations. Furthermore, objective-driven population-based metaheuristics in complex search spaces often quickly exhaust population diversity and succumb to premature convergence to local optima. This issue becomes more complicated in NAS when performance objectives do not fully align with the actual performance of the candidate architectures, as is often the case with training-free metrics. While training-free metrics have gained popularity for their rapid performance estimation of candidate architectures without incurring computation-heavy network training, their effective incorporation into NAS remains a challenge. This paper presents the Pareto Dominance-based Novelty Search for multi-objective NAS with Multiple Training-Free metrics (MTF-PDNS). Unlike conventional NAS methods that optimize explicit objectives, MTF-PDNS promotes population diversity by utilizing a novelty score calculated based on multiple training-free performance and complexity metrics, thereby yielding a broader exploration of the search space. Experimental results on standard NAS benchmark suites demonstrate that MTF-PDNS outperforms conventional methods driven by explicit objectives in terms of convergence speed, diversity maintenance, architecture transferability, and computational costs.
Read more7/31/2024
0
Multi-objective Differentiable Neural Architecture Search
Rhea Sanjay Sukthanker, Arber Zela, Benedikt Staffler, Samuel Dooley, Josif Grabocka, Frank Hutter
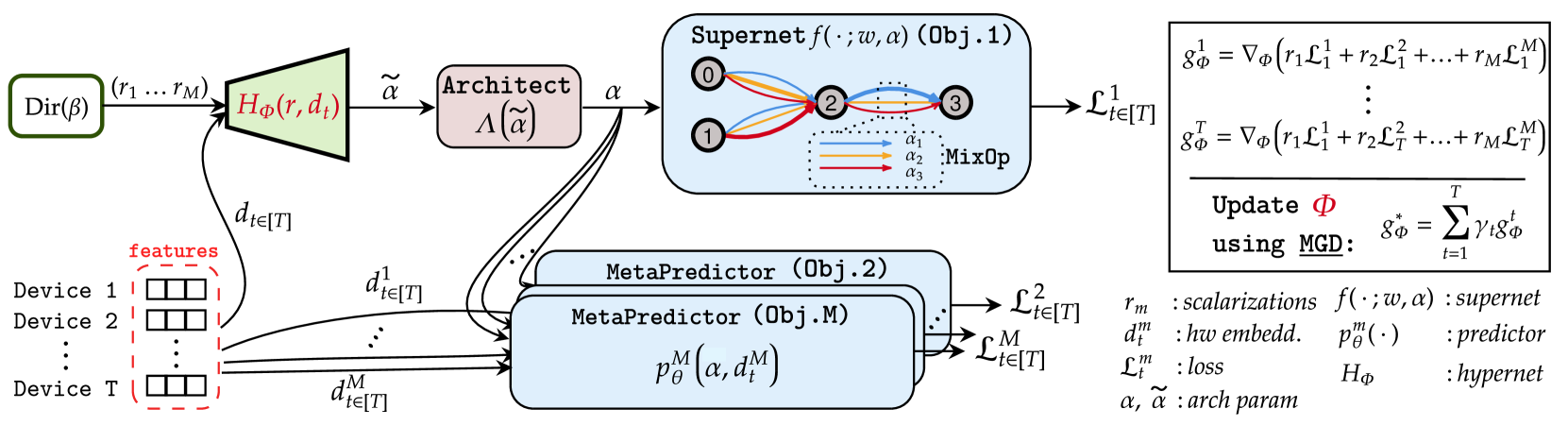
Pareto front profiling in multi-objective optimization (MOO), i.e. finding a diverse set of Pareto optimal solutions, is challenging, especially with expensive objectives like neural network training. Typically, in MOO neural architecture search (NAS), we aim to balance performance and hardware metrics across devices. Prior NAS approaches simplify this task by incorporating hardware constraints into the objective function, but profiling the Pareto front necessitates a computationally expensive search for each constraint. In this work, we propose a novel NAS algorithm that encodes user preferences for the trade-off between performance and hardware metrics, and yields representative and diverse architectures across multiple devices in just one search run. To this end, we parameterize the joint architectural distribution across devices and multiple objectives via a hypernetwork that can be conditioned on hardware features and preference vectors, enabling zero-shot transferability to new devices. Extensive experiments with up to 19 hardware devices and 3 objectives showcase the effectiveness and scalability of our method. Finally, we show that, without extra costs, our method outperforms existing MOO NAS methods across a broad range of qualitatively different search spaces and datasets, including MobileNetV3 on ImageNet-1k, an encoder-decoder transformer space for machine translation and a decoder-only transformer space for language modelling.
Read more6/21/2024
0
Multi-objective Neural Architecture Search by Learning Search Space Partitions
Yiyang Zhao, Linnan Wang, Tian Guo
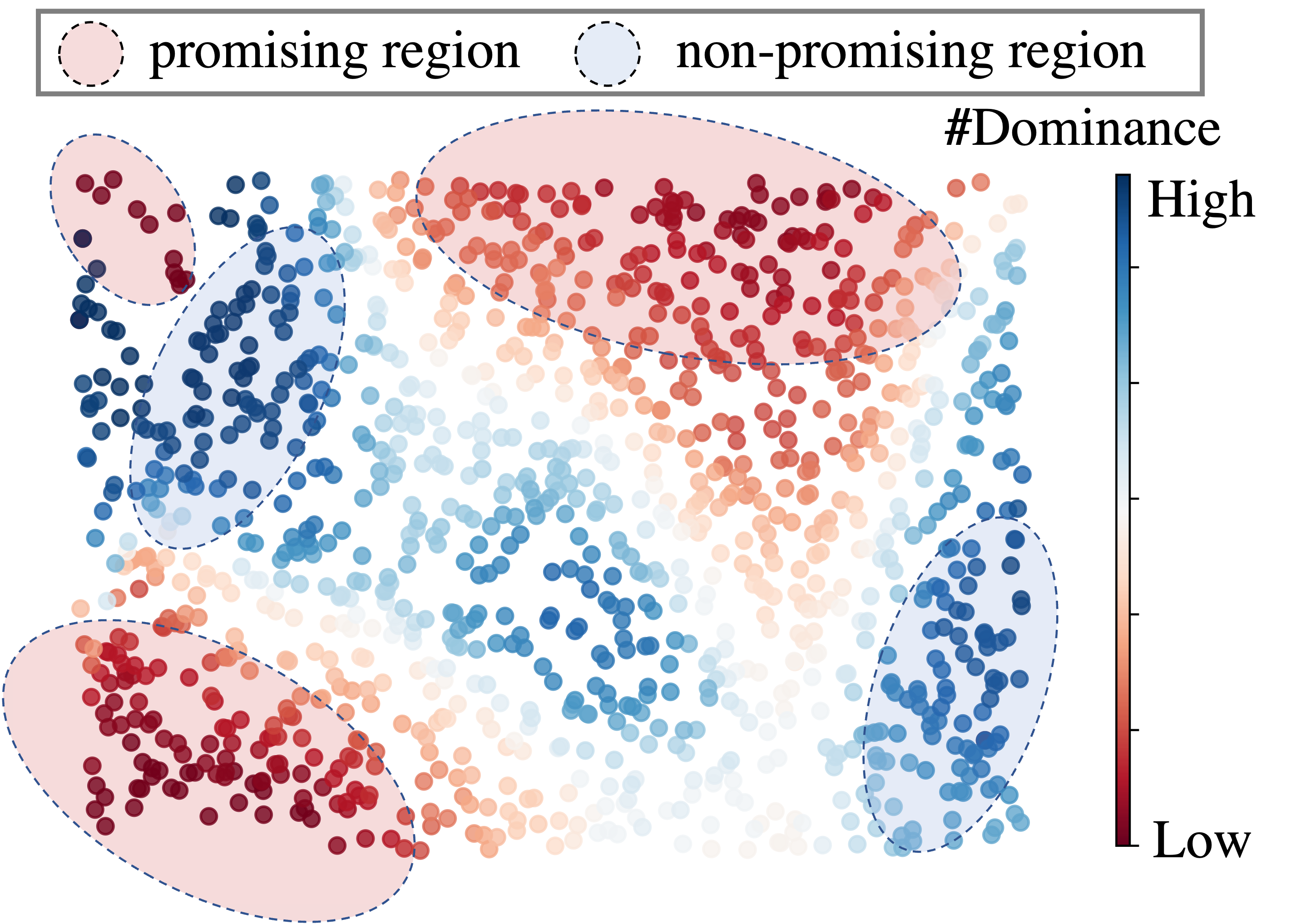
Deploying deep learning models requires taking into consideration neural network metrics such as model size, inference latency, and #FLOPs, aside from inference accuracy. This results in deep learning model designers leveraging multi-objective optimization to design effective deep neural networks in multiple criteria. However, applying multi-objective optimizations to neural architecture search (NAS) is nontrivial because NAS tasks usually have a huge search space, along with a non-negligible searching cost. This requires effective multi-objective search algorithms to alleviate the GPU costs. In this work, we implement a novel multi-objectives optimizer based on a recently proposed meta-algorithm called LaMOO on NAS tasks. In a nutshell, LaMOO speedups the search process by learning a model from observed samples to partition the search space and then focusing on promising regions likely to contain a subset of the Pareto frontier. Using LaMOO, we observe an improvement of more than 200% sample efficiency compared to Bayesian optimization and evolutionary-based multi-objective optimizers on different NAS datasets. For example, when combined with LaMOO, qEHVI achieves a 225% improvement in sample efficiency compared to using qEHVI alone in NasBench201. For real-world tasks, LaMOO achieves 97.36% accuracy with only 1.62M #Params on CIFAR10 in only 600 search samples. On ImageNet, our large model reaches 80.4% top-1 accuracy with only 522M #FLOPs.
Read more7/19/2024

0
Multi-Objective Hardware Aware Neural Architecture Search using Hardware Cost Diversity
Nilotpal Sinha, Peyman Rostami, Abd El Rahman Shabayek, Anis Kacem, Djamila Aouada
Hardware-aware Neural Architecture Search approaches (HW-NAS) automate the design of deep learning architectures, tailored specifically to a given target hardware platform. Yet, these techniques demand substantial computational resources, primarily due to the expensive process of assessing the performance of identified architectures. To alleviate this problem, a recent direction in the literature has employed representation similarity metric for efficiently evaluating architecture performance. Nonetheless, since it is inherently a single objective method, it requires multiple runs to identify the optimal architecture set satisfying the diverse hardware cost constraints, thereby increasing the search cost. Furthermore, simply converting the single objective into a multi-objective approach results in an under-explored architectural search space. In this study, we propose a Multi-Objective method to address the HW-NAS problem, called MO-HDNAS, to identify the trade-off set of architectures in a single run with low computational cost. This is achieved by optimizing three objectives: maximizing the representation similarity metric, minimizing hardware cost, and maximizing the hardware cost diversity. The third objective, i.e. hardware cost diversity, is used to facilitate a better exploration of the architecture search space. Experimental results demonstrate the effectiveness of our proposed method in efficiently addressing the HW-NAS problem across six edge devices for the image classification task.
Read more4/22/2024