Efficient Robot Learning for Perception and Mapping
2405.14688
0
0
🌐
Abstract
Holistic scene understanding poses a fundamental contribution to the autonomous operation of a robotic agent in its environment. Key ingredients include a well-defined representation of the surroundings to capture its spatial structure as well as assigning semantic meaning while delineating individual objects. Classic components from the toolbox of roboticists to address these tasks are simultaneous localization and mapping (SLAM) and panoptic segmentation. Although recent methods demonstrate impressive advances, mostly due to employing deep learning, they commonly utilize in-domain training on large datasets. Since following such a paradigm substantially limits their real-world application, my research investigates how to minimize human effort in deploying perception-based robotic systems to previously unseen environments. In particular, I focus on leveraging continual learning and reducing human annotations for efficient learning. An overview of my work can be found at https://vniclas.github.io.
Create account to get full access
Overview
- This research paper explores the challenge of holistic scene understanding for autonomous robotic agents, which involves representing the spatial structure of the environment and assigning semantic meaning to individual objects.
- The authors highlight the limitations of current deep learning-based approaches, which heavily rely on large, in-domain training datasets, and instead focus on minimizing human effort in deploying perception-based robotic systems to previously unseen environments.
- The key strategies investigated in this research include leveraging continual learning and reducing human annotations for efficient learning.
Plain English Explanation
Robots need to understand their surroundings to navigate and interact with the world effectively. This involves two main tasks: mapping the spatial layout of the environment and identifying the different objects and their meanings. Researchers have developed techniques like simultaneous localization and mapping (SLAM) and panoptic segmentation to tackle these challenges.
Recent advancements, largely driven by deep learning, have made impressive progress. However, these methods typically require large, specially-curated datasets for training, which can limit their real-world applicability. This research aims to address this limitation by exploring ways to minimize the human effort needed to deploy these perception-based robotic systems in new environments.
The key ideas investigated in this work include continual learning, where the system can continuously learn and adapt to new information without forgetting what it has already learned, and reducing the amount of human-provided annotations required for efficient learning.
Technical Explanation
The paper presents an overview of the author's research on holistic scene understanding for autonomous robotic agents. The core challenges addressed are the representation of the spatial structure of the environment and the semantic annotation of individual objects.
The authors highlight the limitations of current deep learning-based approaches, which heavily rely on large, in-domain training datasets. To address this, the research focuses on minimizing human effort in deploying perception-based robotic systems to previously unseen environments.
The key strategies investigated include leveraging continual learning to enable the system to continuously learn and adapt to new information without forgetting its previous knowledge, as well as reducing the amount of human-provided annotations required for efficient learning.
The authors also discuss their work on outlier-robust long-term robotic mapping and online robot navigation and manipulation, which are closely related to the core challenges of holistic scene understanding.
Critical Analysis
The paper presents a well-structured overview of the author's research on minimizing human effort in deploying perception-based robotic systems. The focus on continual learning and reduced annotation requirements is a promising approach to address the limitations of current deep learning-based methods, which heavily rely on large, in-domain training datasets.
However, the paper does not provide specific details on the technical implementation or the experimental results of the proposed approaches. It would be helpful to have a more in-depth discussion of the key algorithms, their performance, and the trade-offs involved in the different techniques.
Additionally, the paper could benefit from a more critical analysis of the potential challenges and limitations of the research. For example, how do the continual learning and reduced annotation methods perform in the face of drastic changes in the environment or the introduction of novel object classes? What are the potential sources of error or bias in these approaches, and how can they be mitigated?
Conclusion
This research paper provides a high-level overview of the author's work on holistic scene understanding for autonomous robotic agents. The key focus is on minimizing human effort in deploying these perception-based systems to previously unseen environments, with a particular emphasis on leveraging continual learning and reducing the amount of required human annotations.
The proposed strategies hold promise in addressing the limitations of current deep learning-based approaches, which are heavily reliant on large, in-domain training datasets. If successful, these innovations could significantly enhance the real-world applicability and deployment of autonomous robotic systems, with potential implications for a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

HIPer: A Human-Inspired Scene Perception Model for Multifunctional Mobile Robots
Florenz Graf, Jochen Lindermayr, Birgit Graf, Werner Kraus, Marco F. Huber
0
0
Taking over arbitrary tasks like humans do with a mobile service robot in open-world settings requires a holistic scene perception for decision-making and high-level control. This paper presents a human-inspired scene perception model to minimize the gap between human and robotic capabilities. The approach takes over fundamental neuroscience concepts, such as a triplet perception split into recognition, knowledge representation, and knowledge interpretation. A recognition system splits the background and foreground to integrate exchangeable image-based object detectors and SLAM, a multi-layer knowledge base represents scene information in a hierarchical structure and offers interfaces for high-level control, and knowledge interpretation methods deploy spatio-temporal scene analysis and perceptual learning for self-adjustment. A single-setting ablation study is used to evaluate the impact of each component on the overall performance for a fetch-and-carry scenario in two simulated and one real-world environment.
4/30/2024
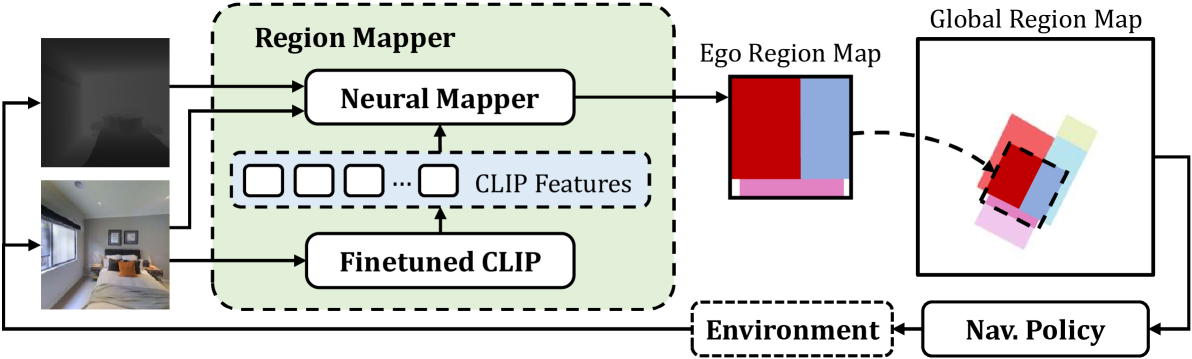
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Roberto Bigazzi, Lorenzo Baraldi, Shreyas Kousik, Rita Cucchiara, Marco Pavone
0
0
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
4/16/2024

Outlier-Robust Long-Term Robotic Mapping Leveraging Ground Segmentation
Hyungtae Lim
0
0
Despite the remarkable advancements in deep learning-based perception technologies and simultaneous localization and mapping (SLAM), one can face the failure of these approaches when robots encounter scenarios outside their modeled experiences (here, the term modeling encompasses both conventional pattern finding and data-driven approaches). In particular, because learning-based methods are prone to catastrophic failure when operated in untrained scenes, there is still a demand for conventional yet robust approaches that work out of the box in diverse scenarios, such as real-world robotic services and SLAM competitions. In addition, the dynamic nature of real-world environments, characterized by changing surroundings over time and the presence of moving objects, leads to undesirable data points that hinder a robot from localization and path planning. Consequently, methodologies that enable long-term map management, such as multi-session SLAM and static map building, become essential. Therefore, to achieve a robust long-term robotic mapping system that can work out of the box, first, I propose (i) fast and robust ground segmentation to reject the ground points, which are featureless and thus not helpful for localization and mapping. Then, by employing the concept of graduated non-convexity (GNC), I propose (ii) outlier-robust registration with ground segmentation that overcomes the presence of gross outliers within the feature matching results, and (iii) hierarchical multi-session SLAM that not only uses our proposed GNC-based registration but also employs a GNC solver to be robust against outlier loop candidates. Finally, I propose (iv) instance-aware static map building that can handle the presence of moving objects in the environment based on the observation that most moving objects in urban environments are inevitably in contact with the ground.
5/29/2024

Online Robot Navigation and Manipulation with Distilled Vision-Language Models
Kangcheng Liu
0
0
Autonomous robot navigation within the dynamic unknown environment is of crucial significance for mobile robotic applications including robot navigation in last-mile delivery and robot-enabled automated supplies in industrial and hospital delivery applications. Current solutions still suffer from limitations, such as the robot cannot recognize unknown objects in real-time and cannot navigate freely in a dynamic, narrow, and complex environment. We propose a complete software framework for autonomous robot perception and navigation within very dense obstacles and dense human crowds. First, we propose a framework that accurately detects and segments open-world object categories in a zero-shot manner, which overcomes the over-segmentation limitation of the current SAM model. Second, we proposed the distillation strategy to distill the knowledge to segment the free space of the walkway for robot navigation without the label. In the meantime, we design the trimming strategy that works collaboratively with distillation to enable lightweight inference to deploy the neural network on edge devices such as NVIDIA-TX2 or Xavier NX during autonomous navigation. Integrated into the robot navigation system, extensive experiments demonstrate that our proposed framework has achieved superior performance in terms of both accuracy and efficiency in robot scene perception and autonomous robot navigation.
5/14/2024