Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
2403.07076
0
0
Abstract
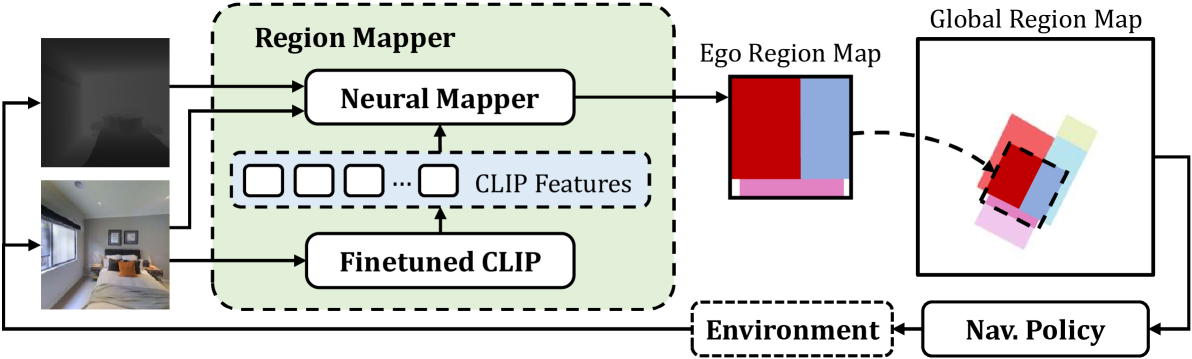
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
Create account to get full access
Overview
- This paper presents a novel approach for mapping high-level semantic regions in indoor environments without relying on object recognition.
- The method leverages spatial and semantic cues to identify and label different functional areas within a scene, such as kitchens, living rooms, and hallways.
- The research has potential applications in areas like robot navigation, augmented reality, and smart home technology.
Plain English Explanation
The researchers in this paper have developed a new way to map out the different zones or areas inside a building, without having to recognize specific objects. Instead of trying to identify individual items like tables, chairs, or appliances, their approach looks at the overall layout and uses clues about the space to figure out what the different regions are used for.
For example, it might notice that an area has a lot of countertops, cabinets, and a sink, and use that information to determine it's likely a kitchen. Or it might see an open space with seating arrangements and conclude it's a living room. By identifying these high-level semantic regions, the system can build a more understandable and useful map of the indoor environment.
This could be really helpful for things like robot navigation, where a robot needs to know where the different functional areas are in order to move around efficiently. It could also benefit augmented reality applications, allowing digital information to be overlaid in a way that's contextually relevant to each zone. And in smart home systems, this kind of semantic mapping could enable better automation and control based on the intended use of each space.
The key innovation here is that they've found a way to do this mapping without relying on object recognition, which can be a tricky and error-prone task. Instead, they focus on the overall layout and usage patterns of the space, which tends to be more reliable and generalizable.
Technical Explanation
The paper introduces a new method for mapping high-level semantic regions in indoor environments without the need for object detection or recognition. The approach leverages spatial and semantic cues to identify and label different functional areas within a scene, such as kitchens, living rooms, and hallways.
The system works by first building a 3D point cloud representation of the environment using RGBD sensors. It then extracts a set of low-level features related to the geometry, layout, and material properties of the space. These features are used to train a machine learning model that can recognize and classify the high-level semantic regions.
Key innovations include the use of semantics-aware mapping to incorporate contextual information, and a loss function designed to handle the open-set challenge of identifying regions not seen during training.
The authors evaluate their approach on several real-world indoor datasets, demonstrating strong performance in accurately labeling different functional areas. They also show how this semantic mapping can enable efficient exploration and predictive occupancy grids for downstream applications.
Critical Analysis
The paper presents a compelling approach for semantic mapping that avoids the need for explicit object recognition, which can be a challenging and error-prone task. By focusing on higher-level spatial and contextual cues, the system is able to achieve robust performance in classifying different functional regions.
That said, the authors acknowledge several limitations and areas for future work. For example, the current method relies on complete 3D scans of the environment, which may not always be available or practical. Extending the approach to work with more partial or noisy data could broaden its real-world applicability.
Additionally, the paper only evaluates the system on a limited set of indoor environments. Further testing on a wider range of building layouts and usage patterns would help validate the generalizability of the approach.
Another potential area for improvement is in the interpretability and explainability of the model's decision-making process. Understanding why the system classifies certain regions in a particular way could lead to further refinements and make the technology more trustworthy for critical applications.
Overall, this research represents a promising step forward in semantic mapping and could have significant implications for fields like robotics, augmented reality, and smart home automation.
Conclusion
This paper introduces a novel approach for mapping high-level semantic regions in indoor environments without relying on object recognition. By leveraging spatial and contextual cues, the system is able to accurately identify and label different functional areas like kitchens, living rooms, and hallways.
The key innovation is that it sidesteps the challenges of object detection, instead focusing on the overall layout and usage patterns of the space. This enables more robust and generalizable semantic mapping that could have important applications in areas like robot navigation, augmented reality, and smart home technology.
While the current method has some limitations, such as the need for complete 3D scans, the research represents a promising step forward in this important field. As the technology continues to evolve, it may pave the way for more intuitive and intelligent systems that can better understand and interact with the indoor spaces around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Open-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
Laksh Nanwani, Kumaraditya Gupta, Aditya Mathur, Swayam Agrawal, A. H. Abdul Hafez, K. Madhava Krishna
0
0
Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
4/30/2024

Robotic Exploration through Semantic Topometric Mapping
Scott Fredriksson, Akshit Saradagi, George Nikolakopoulos
0
0
In this article, we introduce a novel strategy for robotic exploration in unknown environments using a semantic topometric map. As it will be presented, the semantic topometric map is generated by segmenting the grid map of the currently explored parts of the environment into regions, such as intersections, pathways, dead-ends, and unexplored frontiers, which constitute the structural semantics of an environment. The proposed exploration strategy leverages metric information of the frontier, such as distance and angle to the frontier, similar to existing frameworks, with the key difference being the additional utilization of structural semantic information, such as properties of the intersections leading to frontiers. The algorithm for generating semantic topometric mapping utilized by the proposed method is lightweight, resulting in the method's online execution being both rapid and computationally efficient. Moreover, the proposed framework can be applied to both structured and unstructured indoor and outdoor environments, which enhances the versatility of the proposed exploration algorithm. We validate our exploration strategy and demonstrate the utility of structural semantics in exploration in two complex indoor environments by utilizing a Turtlebot3 as the robotic agent. Compared to traditional frontier-based methods, our findings indicate that the proposed approach leads to faster exploration and requires less computation time.
6/27/2024

QueSTMaps: Queryable Semantic Topological Maps for 3D Scene Understanding
Yash Mehan, Kumaraditya Gupta, Rohit Jayanti, Anirudh Govil, Sourav Garg, Madhava Krishna
0
0
Understanding the structural organisation of 3D indoor scenes in terms of rooms is often accomplished via floorplan extraction. Robotic tasks such as planning and navigation require a semantic understanding of the scene as well. This is typically achieved via object-level semantic segmentation. However, such methods struggle to segment out topological regions like kitchen in the scene. In this work, we introduce a two-step pipeline. First, we extract a topological map, i.e., floorplan of the indoor scene using a novel multi-channel occupancy representation. Then, we generate CLIP-aligned features and semantic labels for every room instance based on the objects it contains using a self-attention transformer. Our language-topology alignment supports natural language querying, e.g., a place to cook locates the kitchen. We outperform the current state-of-the-art on room segmentation by ~20% and room classification by ~12%. Our detailed qualitative analysis and ablation studies provide insights into the problem of joint structural and semantic 3D scene understanding.
4/10/2024

Monocular Localization with Semantics Map for Autonomous Vehicles
Jixiang Wan, Xudong Zhang, Shuzhou Dong, Yuwei Zhang, Yuchen Yang, Ruoxi Wu, Ye Jiang, Jijunnan Li, Jinquan Lin, Ming Yang
0
0
Accurate and robust localization remains a significant challenge for autonomous vehicles. The cost of sensors and limitations in local computational efficiency make it difficult to scale to large commercial applications. Traditional vision-based approaches focus on texture features that are susceptible to changes in lighting, season, perspective, and appearance. Additionally, the large storage size of maps with descriptors and complex optimization processes hinder system performance. To balance efficiency and accuracy, we propose a novel lightweight visual semantic localization algorithm that employs stable semantic features instead of low-level texture features. First, semantic maps are constructed offline by detecting semantic objects, such as ground markers, lane lines, and poles, using cameras or LiDAR sensors. Then, online visual localization is performed through data association of semantic features and map objects. We evaluated our proposed localization framework in the publicly available KAIST Urban dataset and in scenarios recorded by ourselves. The experimental results demonstrate that our method is a reliable and practical localization solution in various autonomous driving localization tasks.
6/7/2024