Efficient Video to Audio Mapper with Visual Scene Detection

0

Sign in to get full access
Overview
- The paper proposes an efficient video-to-audio mapping system with visual scene detection.
- It aims to generate high-quality audio from video inputs by leveraging machine learning techniques.
- The system incorporates a visual scene detection component to enhance the audio generation process.
Plain English Explanation
The paper presents a new approach for converting video to audio. The key idea is to use machine learning to analyze the visual scenes in a video and then generate corresponding high-quality audio.
The system first detects the different visual scenes or environments within the video, such as a busy city street or a quiet forest. It then uses this information about the visual context to help produce more realistic and appropriate audio to match the video.
For example, if the system detects a city street scene, it might generate the sounds of traffic, pedestrians, and other urban noises. But if it detects a forest scene, it might generate more natural sounds like birds chirping and leaves rustling.
The researchers believe this approach leads to more coherent and semantically consistent audio generation compared to previous methods that didn't take the visual context into account.
Technical Explanation
The proposed system has two key components: a video encoder and an audio decoder.
The video encoder first analyzes the input video frames to detect the different visual scenes or environments present. This scene detection module uses convolutional neural networks to classify the visual content.
The audio decoder then takes the video features and the detected scene information as inputs. It uses this multimodal data to generate the corresponding audio waveform. The audio decoder employs an autoregressive model to progressively synthesize the audio sample by sample.
The researchers trained and evaluated the system on a large dataset of video-audio pairs. They found that incorporating the visual scene detection component led to significant improvements in the quality and realism of the generated audio compared to prior video-to-audio mapping approaches.
Critical Analysis
The paper presents a promising approach for efficient video-to-audio conversion that leverages visual scene understanding. However, the researchers acknowledge several limitations and areas for future work:
- The current system only supports a fixed set of visual scene classes, so its performance may be limited for diverse or complex real-world videos.
- The audio generation quality could potentially be further improved by incorporating more advanced audio synthesis techniques or by modeling long-range audio dependencies.
- The computational efficiency of the system was not extensively evaluated, which is an important practical consideration for real-world deployment.
Additionally, the paper does not address potential ethical concerns around the use of such video-to-audio conversion technology, such as the risk of generating fake or misleading audio content. Further research is needed to understand the societal implications of this technology.
Conclusion
The proposed video-to-audio mapping system with visual scene detection represents an important step forward in audiovisual content generation. By incorporating scene-aware information, the system can generate more semantically consistent and realistic audio to accompany video inputs.
While the paper highlights several promising directions, additional research is needed to address the limitations and explore the broader societal impact of this technology. Nonetheless, this work contributes to the ongoing efforts to bridge the gap between visual and auditory modalities and enable more seamless and immersive multimedia experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Video to Audio Mapper with Visual Scene Detection
Mingjing Yi, Ming Li
Video-to-audio (V2A) generation aims to produce corresponding audio given silent video inputs. This task is particularly challenging due to the cross-modality and sequential nature of the audio-visual features involved. Recent works have made significant progress in bridging the domain gap between video and audio, generating audio that is semantically aligned with the video content. However, a critical limitation of these approaches is their inability to effectively recognize and handle multiple scenes within a video, often leading to suboptimal audio generation in such cases. In this paper, we first reimplement a state-of-the-art V2A model with a slightly modified light-weight architecture, achieving results that outperform the baseline. We then propose an improved V2A model that incorporates a scene detector to address the challenge of switching between multiple visual scenes. Results on VGGSound show that our model can recognize and handle multiple scenes within a video and achieve superior performance against the baseline for both fidelity and relevance.
Read more9/17/2024
0
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
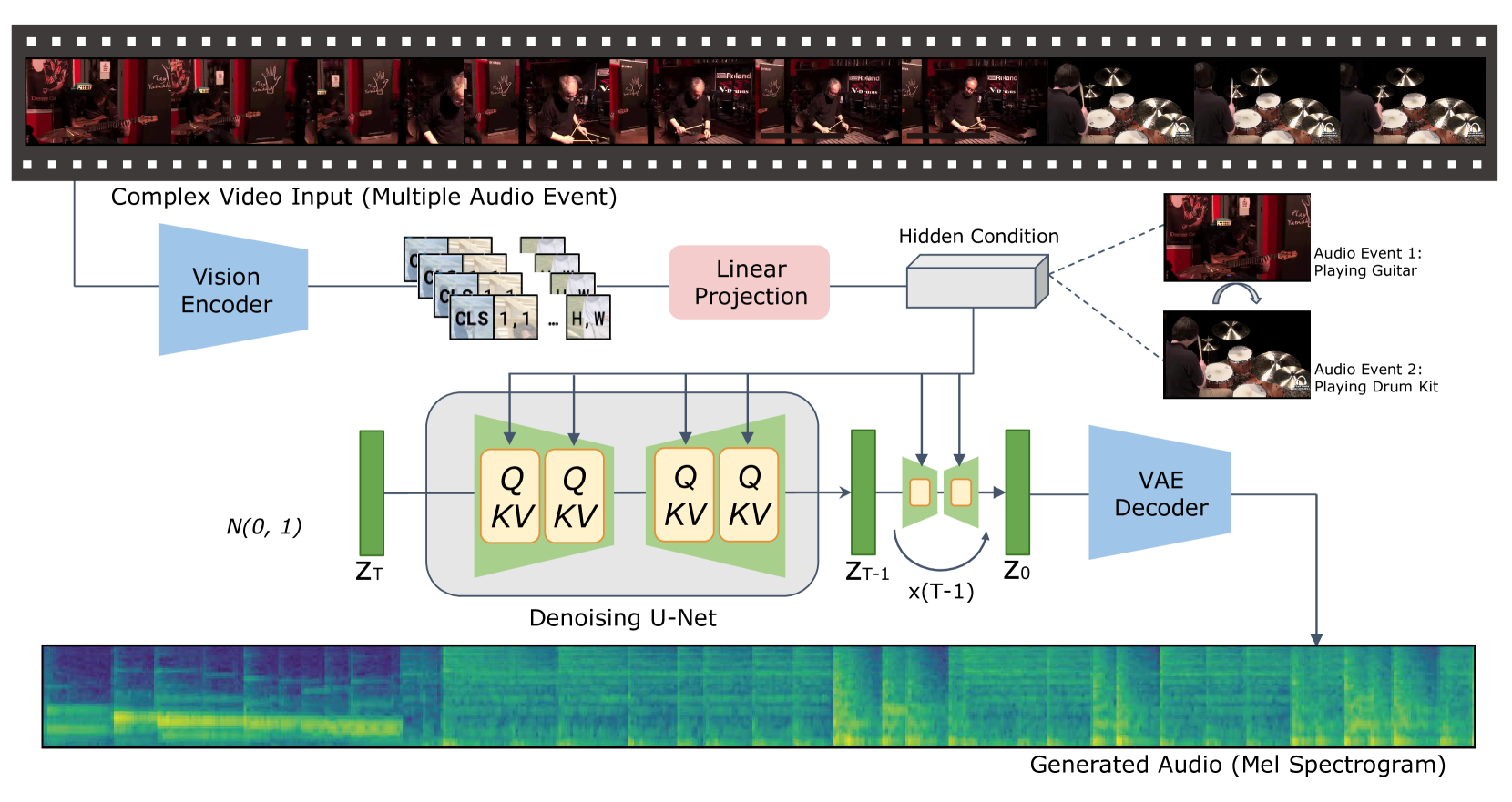
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024
0
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
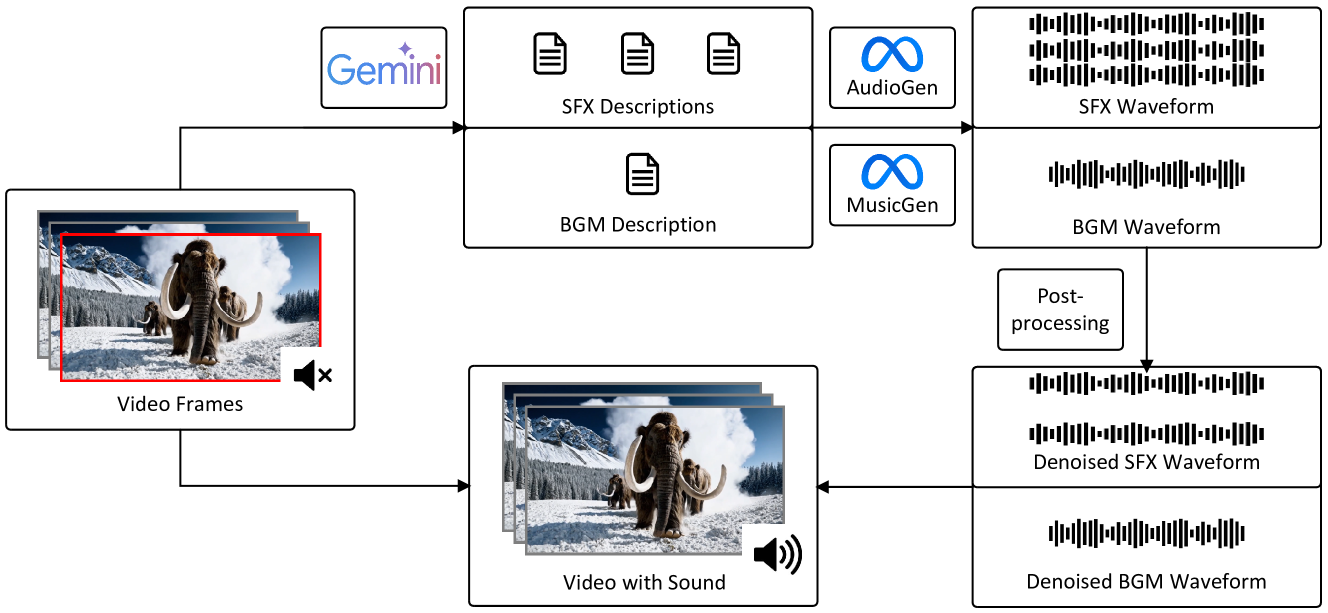
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
Read more4/29/2024

0
STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment
Yong Ren, Chenxing Li, Manjie Xu, Wei Liang, Yu Gu, Rilin Chen, Dong Yu
Visual and auditory perception are two crucial ways humans experience the world. Text-to-video generation has made remarkable progress over the past year, but the absence of harmonious audio in generated video limits its broader applications. In this paper, we propose Semantic and Temporal Aligned Video-to-Audio (STA-V2A), an approach that enhances audio generation from videos by extracting both local temporal and global semantic video features and combining these refined video features with text as cross-modal guidance. To address the issue of information redundancy in videos, we propose an onset prediction pretext task for local temporal feature extraction and an attentive pooling module for global semantic feature extraction. To supplement the insufficient semantic information in videos, we propose a Latent Diffusion Model with Text-to-Audio priors initialization and cross-modal guidance. We also introduce Audio-Audio Align, a new metric to assess audio-temporal alignment. Subjective and objective metrics demonstrate that our method surpasses existing Video-to-Audio models in generating audio with better quality, semantic consistency, and temporal alignment. The ablation experiment validated the effectiveness of each module. Audio samples are available at https://y-ren16.github.io/STAV2A.
Read more9/16/2024