STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment

0

Sign in to get full access
Overview
- The paper presents a new model called STA-V2A for generating audio from video.
- It uses a latent diffusion approach to align the video and audio representations semantically and temporally.
- The model is evaluated on various video-to-audio generation tasks and shows improved performance compared to previous methods.
Plain English Explanation
The researchers have developed a new model called STA-V2A that can generate audio from video. This is a challenging task because video and audio information are very different - video contains visual information while audio contains sound information.
The key innovation in STA-V2A is how it aligns the video and audio representations. It uses a latent diffusion approach to map both the video and audio into a shared latent space. This allows the model to understand the semantic (meaning) and temporal (timing) connections between the visual and auditory information.
For example, when you see someone playing a guitar in a video, the model learns to associate that visual information with the corresponding guitar sounds. By aligning the video and audio in this way, the model can then generate realistic audio that matches the video content.
The researchers evaluated STA-V2A on several video-to-audio generation tasks and found that it outperformed previous methods. This suggests the model is effectively learning the relationship between visual and auditory information, which is an important step towards more natural and immersive video experiences.
Technical Explanation
The key technical innovation in STA-V2A is the use of a latent diffusion model to align the video and audio representations. Specifically:
- The model takes in a video clip and learns to generate the corresponding audio waveform.
- It does this by first encoding the video and audio into compact latent representations using convolutional and transformer-based encoders.
- These latent representations are then passed through a diffusion model, which learns to gradually transform the video latent into the audio latent in a semantically and temporally aligned fashion.
- The final audio waveform is generated from the aligned latent representation using a vocoder module.
The researchers designed extensive experiments to evaluate STA-V2A on various video-to-audio generation tasks, including generating audio for silent videos, generating sounds for objects/actions, and cross-modal retrieval. The results showed that STA-V2A outperformed previous state-of-the-art methods, demonstrating the effectiveness of the latent diffusion approach for aligning video and audio.
Critical Analysis
The paper presents a novel and promising approach for video-to-audio generation, but there are a few potential limitations and areas for further research:
- The model was primarily evaluated on relatively short video clips (a few seconds). It's unclear how well it would scale to longer, more complex videos.
- The audio quality generated by STA-V2A, while improved over prior methods, is still not at the level of human-recorded audio. Further work is needed to enhance the fidelity of the generated audio.
- The paper does not provide much analysis on the types of audio that the model struggles to generate. Understanding the limitations and failure cases could help guide future improvements.
- Incorporating more advanced audio processing techniques, such as semantic-aware audio generation or masked audio transformers, could further enhance the model's capabilities.
Overall, the STA-V2A model represents an interesting step forward in the field of video-to-audio generation, with potential applications in areas like virtual/augmented reality, animation, and interactive media.
Conclusion
The STA-V2A model presents a novel approach to the challenge of generating audio from video. By using a latent diffusion model to semantically and temporally align the video and audio representations, the researchers have demonstrated improved performance on various video-to-audio generation tasks compared to previous methods.
While there are still some limitations to address, this work represents an important advance in the field and could lead to more immersive and natural video experiences in the future. As the quality and fidelity of generated audio continue to improve, the potential applications of this technology in areas like virtual/augmented reality, animation, and interactive media will only grow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment
Yong Ren, Chenxing Li, Manjie Xu, Wei Liang, Yu Gu, Rilin Chen, Dong Yu
Visual and auditory perception are two crucial ways humans experience the world. Text-to-video generation has made remarkable progress over the past year, but the absence of harmonious audio in generated video limits its broader applications. In this paper, we propose Semantic and Temporal Aligned Video-to-Audio (STA-V2A), an approach that enhances audio generation from videos by extracting both local temporal and global semantic video features and combining these refined video features with text as cross-modal guidance. To address the issue of information redundancy in videos, we propose an onset prediction pretext task for local temporal feature extraction and an attentive pooling module for global semantic feature extraction. To supplement the insufficient semantic information in videos, we propose a Latent Diffusion Model with Text-to-Audio priors initialization and cross-modal guidance. We also introduce Audio-Audio Align, a new metric to assess audio-temporal alignment. Subjective and objective metrics demonstrate that our method surpasses existing Video-to-Audio models in generating audio with better quality, semantic consistency, and temporal alignment. The ablation experiment validated the effectiveness of each module. Audio samples are available at https://y-ren16.github.io/STAV2A.
Read more9/16/2024
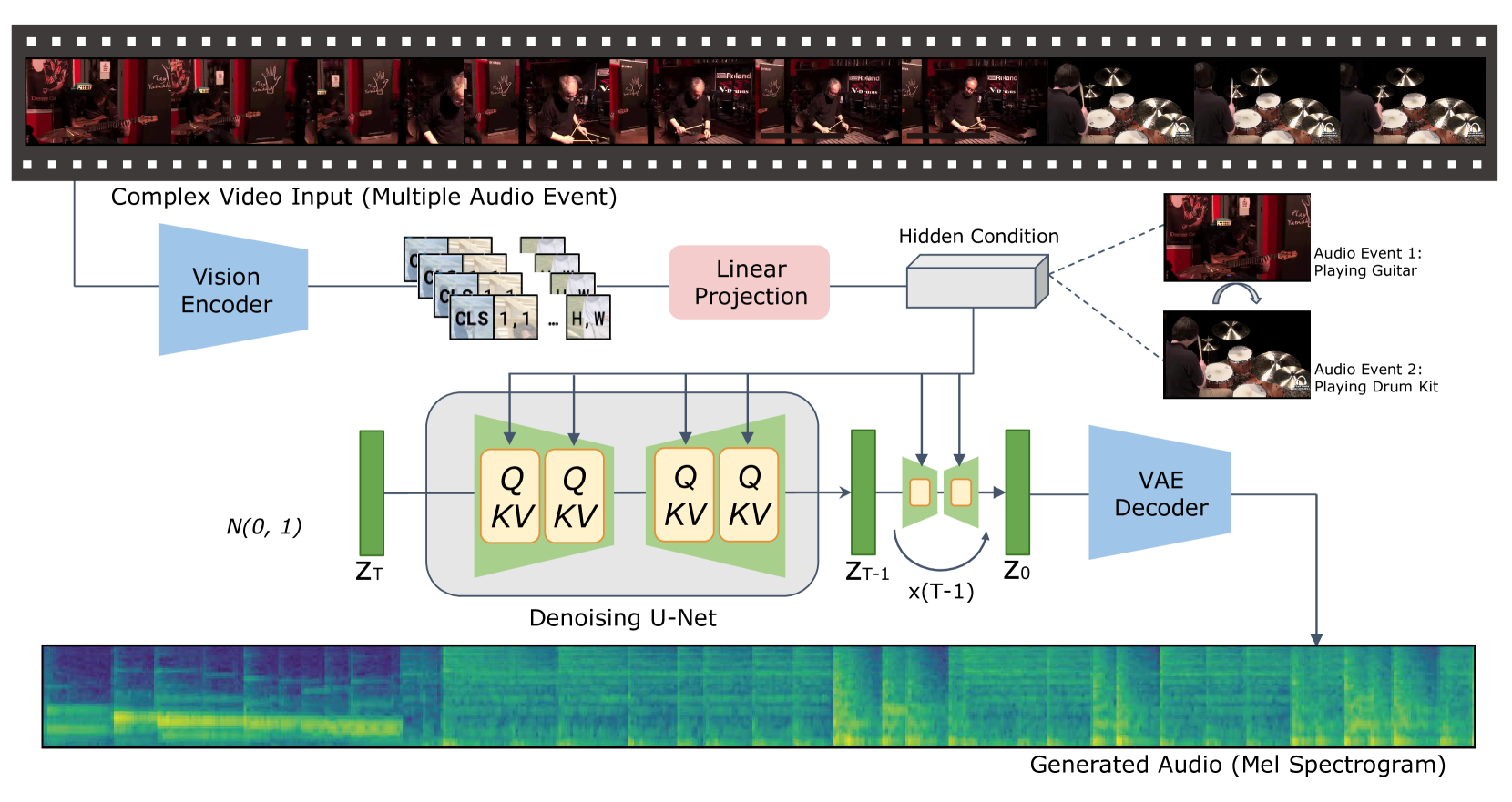
0
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024

0
Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity
Santiago Pascual, Chunghsin Yeh, Ioannis Tsiamas, Joan Serr`a
Video-to-audio (V2A) generation leverages visual-only video features to render plausible sounds that match the scene. Importantly, the generated sound onsets should match the visual actions that are aligned with them, otherwise unnatural synchronization artifacts arise. Recent works have explored the progression of conditioning sound generators on still images and then video features, focusing on quality and semantic matching while ignoring synchronization, or by sacrificing some amount of quality to focus on improving synchronization only. In this work, we propose a V2A generative model, named MaskVAT, that interconnects a full-band high-quality general audio codec with a sequence-to-sequence masked generative model. This combination allows modeling both high audio quality, semantic matching, and temporal synchronicity at the same time. Our results show that, by combining a high-quality codec with the proper pre-trained audio-visual features and a sequence-to-sequence parallel structure, we are able to yield highly synchronized results on one hand, whilst being competitive with the state of the art of non-codec generative audio models. Sample videos and generated audios are available at https://maskvat.github.io .
Read more7/16/2024
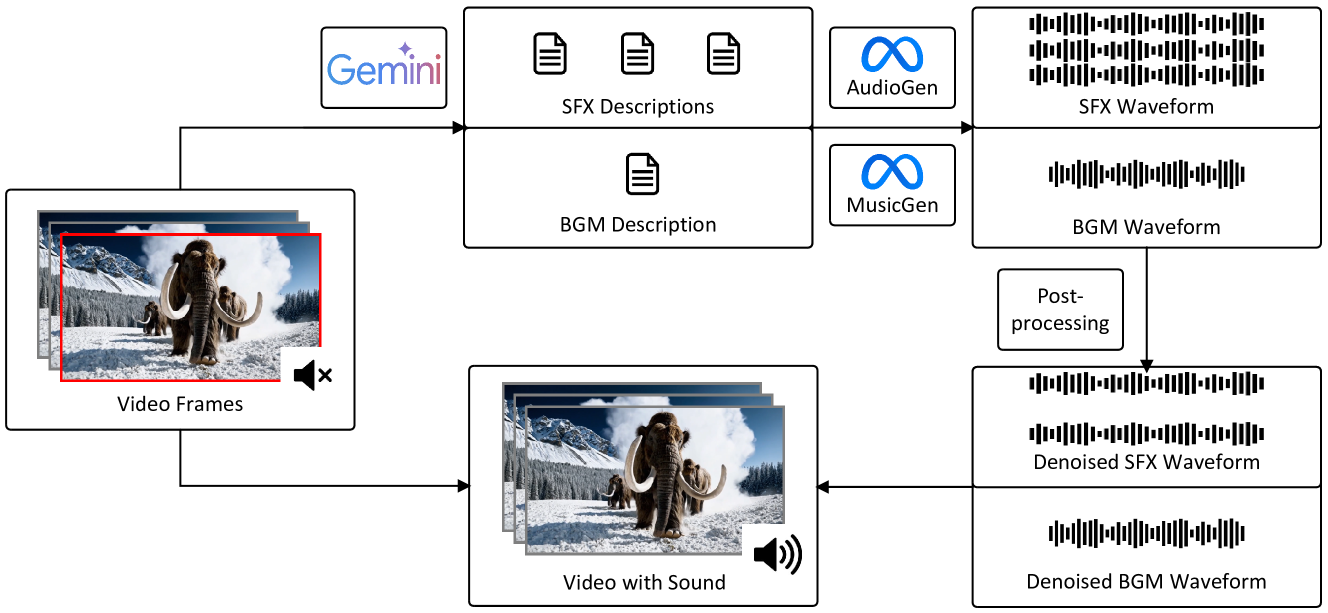
0
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
Read more4/29/2024