EFFOcc: A Minimal Baseline for EFficient Fusion-based 3D Occupancy Network
2406.07042
0
0

Abstract
3D occupancy prediction (Occ) is a rapidly rising challenging perception task in the field of autonomous driving which represents the driving scene as uniformly partitioned 3D voxel grids with semantics. Compared to 3D object detection, grid perception has great advantage of better recognizing irregularly shaped, unknown category, or partially occluded general objects. However, existing 3D occupancy networks (occnets) are both computationally heavy and label-hungry. In terms of model complexity, occnets are commonly composed of heavy Conv3D modules or transformers on the voxel level. In terms of label annotations requirements, occnets are supervised with large-scale expensive dense voxel labels. Model and data inefficiency, caused by excessive network parameters and label annotations requirement, severely hinder the onboard deployment of occnets. This paper proposes an efficient 3d occupancy network (EFFOcc), that targets the minimal network complexity and label requirement while achieving state-of-the-art accuracy. EFFOcc only uses simple 2D operators, and improves Occ accuracy to the state-of-the-art on multiple large-scale benchmarks: Occ3D-nuScenes, Occ3D-Waymo, and OpenOccupancy-nuScenes. On Occ3D-nuScenes benchmark, EFFOcc has only 18.4M parameters, and achieves 50.46 in terms of mean IoU (mIoU), to our knowledge, it is the occnet with minimal parameters compared with related occnets. Moreover, we propose a two-stage active learning strategy to reduce the requirements of labelled data. Active EFFOcc trained with 6% labelled voxels achieves 47.19 mIoU, which is 95.7% fully supervised performance. The proposed EFFOcc also supports improved vision-only occupancy prediction with the aid of region-decomposed distillation. Code and demo videos will be available at https://github.com/synsin0/EFFOcc.
Create account to get full access
Overview
- This paper introduces EFFOcc, a novel 3D occupancy prediction network that leverages multi-sensor fusion and knowledge distillation techniques to achieve efficient and accurate 3D occupancy mapping.
- The key contributions of the paper include a simple yet effective fusion-based architecture, a knowledge distillation approach to improve the model's performance, and a comprehensive evaluation on diverse autonomous driving datasets.
Plain English Explanation
The paper presents a new method called EFFOcc (Efficient Fusion-based 3D Occupancy Network) for predicting 3D occupancy maps, which are essential for autonomous driving applications. 3D occupancy maps represent the physical space around a vehicle, allowing self-driving cars to navigate safely and avoid obstacles.
EFFOcc takes advantage of data from multiple sensors, such as cameras and depth sensors, to create a more accurate and efficient occupancy prediction model. By fusing the information from these sensors, the model can make better decisions about the layout of the environment compared to using a single sensor alone.
Additionally, the researchers use a technique called "knowledge distillation" to further improve the model's performance. This involves training a smaller, more efficient model to mimic the behavior of a larger, more complex model, allowing the smaller model to achieve similar accuracy with fewer computational resources.
The paper evaluates the EFFOcc model on various autonomous driving datasets and demonstrates its advantages over other state-of-the-art 3D occupancy prediction approaches, in terms of both accuracy and efficiency.
Technical Explanation
The paper introduces the EFFOcc (Efficient Fusion-based 3D Occupancy Network) architecture, which combines data from multiple sensors to predict 3D occupancy maps. The model takes in 2D image data from cameras and depth information from other sensors, and fuses these inputs using a lightweight encoder-decoder network.
The authors also propose a knowledge distillation strategy, where a smaller "student" model is trained to mimic the behavior of a larger "teacher" model. This allows the smaller model to achieve similar performance to the larger model, but with reduced computational requirements, making it more suitable for deployment on embedded systems in autonomous vehicles.
The EFFOcc model is evaluated on several autonomous driving datasets, including GeOcc, OccFusion, Fully Sparse 3D Occupancy Prediction, SparseOcc, and CO-OCC. The results demonstrate that EFFOcc outperforms these state-of-the-art approaches in terms of both accuracy and inference speed, making it a promising solution for real-time 3D occupancy mapping in autonomous driving applications.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the EFFOcc model, considering various benchmarks and datasets. However, the authors do not extensively discuss potential limitations or caveats of their approach.
One aspect that could be further explored is the model's robustness to different environmental conditions, such as varying weather, lighting, or sensor failures. Additionally, the paper does not delve into the potential ethical implications or societal impact of deploying such 3D occupancy prediction models in autonomous vehicles.
Further research could also investigate the transferability of the EFFOcc model to other domains beyond autonomous driving, or explore ways to make the knowledge distillation process more adaptive and flexible to accommodate changes in the target deployment environment.
Conclusion
The EFFOcc paper presents a promising approach to 3D occupancy prediction for autonomous driving applications. By leveraging multi-sensor fusion and knowledge distillation techniques, the authors have developed an efficient and accurate model that outperforms existing state-of-the-art methods.
The successful deployment of EFFOcc in real-world autonomous driving scenarios could contribute to improving the safety and reliability of self-driving cars, ultimately enhancing the overall transportation experience for the general public. The paper's findings also suggest that the integration of multiple sensor modalities and the use of knowledge distillation can be valuable strategies for developing efficient and robust perception systems for autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
Xin Tan, Wenbin Wu, Zhiwei Zhang, Chaojie Fan, Yong Peng, Zhizhong Zhang, Yuan Xie, Lizhuang Ma
0
0
3D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
5/20/2024

OccFusion: A Straightforward and Effective Multi-Sensor Fusion Framework for 3D Occupancy Prediction
Zhenxing Ming, Julie Stephany Berrio, Mao Shan, Stewart Worrall
0
0
A comprehensive understanding of 3D scenes is crucial in autonomous vehicles (AVs), and recent models for 3D semantic occupancy prediction have successfully addressed the challenge of describing real-world objects with varied shapes and classes. However, existing methods for 3D occupancy prediction heavily rely on surround-view camera images, making them susceptible to changes in lighting and weather conditions. This paper introduces OccFusion, a novel sensor fusion framework for predicting 3D occupancy. By integrating features from additional sensors, such as lidar and surround view radars, our framework enhances the accuracy and robustness of occupancy prediction, resulting in top-tier performance on the nuScenes benchmark. Furthermore, extensive experiments conducted on the nuScenes and semanticKITTI dataset, including challenging night and rainy scenarios, confirm the superior performance of our sensor fusion strategy across various perception ranges. The code for this framework will be made available at https://github.com/DanielMing123/OccFusion.
5/10/2024

Fully Sparse 3D Occupancy Prediction
Haisong Liu, Yang Chen, Haiguang Wang, Zetong Yang, Tianyu Li, Jia Zeng, Li Chen, Hongyang Li, Limin Wang
0
0
Occupancy prediction plays a pivotal role in autonomous driving. Previous methods typically construct dense 3D volumes, neglecting the inherent sparsity of the scene and suffering high computational costs. To bridge the gap, we introduce a novel fully sparse occupancy network, termed SparseOcc. SparseOcc initially reconstructs a sparse 3D representation from visual inputs and subsequently predicts semantic/instance occupancy from the 3D sparse representation by sparse queries. A mask-guided sparse sampling is designed to enable sparse queries to interact with 2D features in a fully sparse manner, thereby circumventing costly dense features or global attention. Additionally, we design a thoughtful ray-based evaluation metric, namely RayIoU, to solve the inconsistency penalty along depths raised in traditional voxel-level mIoU criteria. SparseOcc demonstrates its effectiveness by achieving a RayIoU of 34.0, while maintaining a real-time inference speed of 17.3 FPS, with 7 history frames inputs. By incorporating more preceding frames to 15, SparseOcc continuously improves its performance to 35.1 RayIoU without whistles and bells. Code is available at https://github.com/MCG-NJU/SparseOcc.
4/9/2024
SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
Pin Tang, Zhongdao Wang, Guoqing Wang, Jilai Zheng, Xiangxuan Ren, Bailan Feng, Chao Ma
0
0
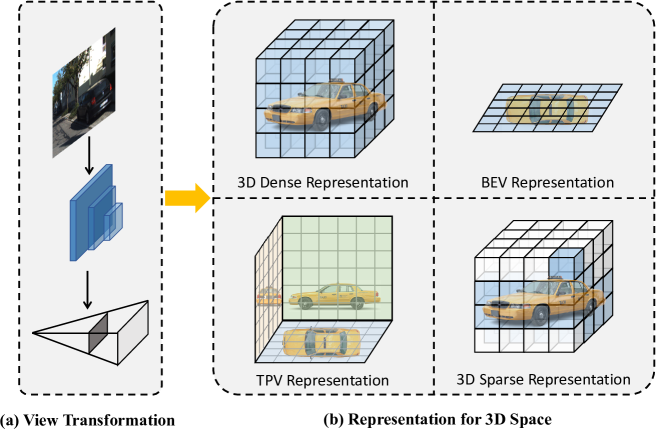
Vision-based perception for autonomous driving requires an explicit modeling of a 3D space, where 2D latent representations are mapped and subsequent 3D operators are applied. However, operating on dense latent spaces introduces a cubic time and space complexity, which limits scalability in terms of perception range or spatial resolution. Existing approaches compress the dense representation using projections like Bird's Eye View (BEV) or Tri-Perspective View (TPV). Although efficient, these projections result in information loss, especially for tasks like semantic occupancy prediction. To address this, we propose SparseOcc, an efficient occupancy network inspired by sparse point cloud processing. It utilizes a lossless sparse latent representation with three key innovations. Firstly, a 3D sparse diffuser performs latent completion using spatially decomposed 3D sparse convolutional kernels. Secondly, a feature pyramid and sparse interpolation enhance scales with information from others. Finally, the transformer head is redesigned as a sparse variant. SparseOcc achieves a remarkable 74.9% reduction on FLOPs over the dense baseline. Interestingly, it also improves accuracy, from 12.8% to 14.1% mIOU, which in part can be attributed to the sparse representation's ability to avoid hallucinations on empty voxels.
4/16/2024