SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
2404.09502
0
0
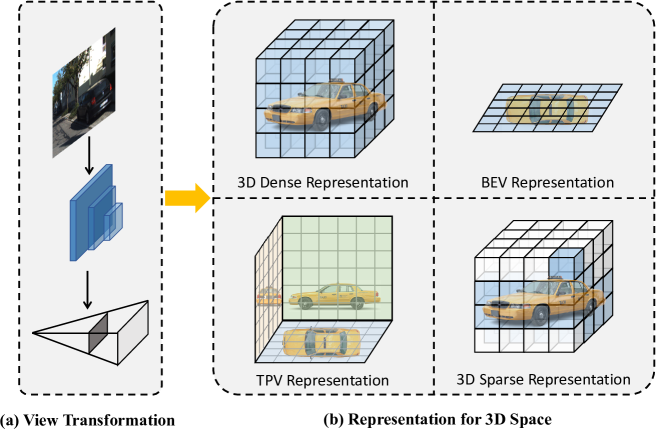
Abstract
Vision-based perception for autonomous driving requires an explicit modeling of a 3D space, where 2D latent representations are mapped and subsequent 3D operators are applied. However, operating on dense latent spaces introduces a cubic time and space complexity, which limits scalability in terms of perception range or spatial resolution. Existing approaches compress the dense representation using projections like Bird's Eye View (BEV) or Tri-Perspective View (TPV). Although efficient, these projections result in information loss, especially for tasks like semantic occupancy prediction. To address this, we propose SparseOcc, an efficient occupancy network inspired by sparse point cloud processing. It utilizes a lossless sparse latent representation with three key innovations. Firstly, a 3D sparse diffuser performs latent completion using spatially decomposed 3D sparse convolutional kernels. Secondly, a feature pyramid and sparse interpolation enhance scales with information from others. Finally, the transformer head is redesigned as a sparse variant. SparseOcc achieves a remarkable 74.9% reduction on FLOPs over the dense baseline. Interestingly, it also improves accuracy, from 12.8% to 14.1% mIOU, which in part can be attributed to the sparse representation's ability to avoid hallucinations on empty voxels.
Create account to get full access
Overview
- The paper proposes a novel approach called "SparseOcc" for vision-based semantic occupancy prediction in 3D scenes.
- The key idea is to leverage a sparse latent representation to efficiently capture the structure and semantics of the environment.
- The authors claim that SparseOcc outperforms existing methods in terms of accuracy and computational efficiency.
Plain English Explanation
The paper introduces a new technique called SparseOcc that aims to improve the way computers understand and represent 3D environments. When you look around a room, you can easily identify different objects, their shapes, and how they are arranged. Computers, on the other hand, need to be trained to perceive and understand these 3D scenes.
The core idea behind SparseOcc is to use a sparse latent representation to capture the structure and semantics of the 3D environment. This means that instead of trying to represent every single detail, the system focuses on the most important, or "sparse," features that are essential for understanding the scene. This approach is more efficient than traditional methods, which often struggle to handle the complexity of 3D data.
The authors claim that SparseOcc outperforms existing techniques in terms of both accuracy and computational efficiency. This means that it can more accurately predict the occupancy and semantic information of a 3D scene, while also being faster and requiring less computational resources than other approaches.
Technical Explanation
The paper proposes a novel method called SparseOcc for vision-based semantic occupancy prediction in 3D scenes. The key innovation is the use of a sparse latent representation to efficiently capture the structure and semantics of the environment.
The authors argue that existing approaches to 3D scene understanding often struggle to handle the complexity of the data, leading to suboptimal performance and high computational costs. In contrast, SparseOcc leverages a sparse latent representation that focuses on the most important features, rather than trying to represent every detail.
The SparseOcc architecture consists of a perception module that encodes the input RGB-D data into a sparse latent representation, and a prediction module that uses this representation to predict the occupancy and semantic labels of the 3D scene. The authors demonstrate that this approach outperforms state-of-the-art methods, such as Fully Sparse 3D Occupancy Prediction, COTR: Compact Occupancy Transformer, and Unified Spatio-Temporal Tri-Perspective View Representation, in terms of both accuracy and computational efficiency.
Critical Analysis
The paper presents a compelling approach to 3D scene understanding, but there are a few potential limitations and areas for further research:
-
Generalization Capabilities: While the authors demonstrate the effectiveness of SparseOcc on various datasets, it would be interesting to see how the model performs on more diverse and challenging 3D scenes, such as those encountered in real-world applications.
-
Interpretability: The paper does not provide much insight into the internal workings of the sparse latent representation and how it captures the structure and semantics of the 3D environment. Improving the interpretability of the model could help users better understand its decision-making process.
-
Integration with Downstream Tasks: The authors focus on the occupancy and semantic prediction tasks, but it would be valuable to explore how SparseOcc could be integrated with other 3D understanding tasks, such as object detection, instance segmentation, or scene reconstruction, as mentioned in related works like CO-OCC: Coupling Explicit Feature Fusion Volume and Unsupervised Occupancy Learning from Sparse Point Cloud.
Conclusion
The SparseOcc approach presented in this paper offers a promising solution for efficient and accurate vision-based 3D scene understanding. By leveraging a sparse latent representation, the authors demonstrate significant improvements over existing methods, opening up new possibilities for applications ranging from robotics and autonomous navigation to augmented reality and smart home systems. While the paper highlights several compelling aspects of the technique, further research is needed to address potential limitations and explore its integration with a wider range of 3D understanding tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fully Sparse 3D Occupancy Prediction
Haisong Liu, Yang Chen, Haiguang Wang, Zetong Yang, Tianyu Li, Jia Zeng, Li Chen, Hongyang Li, Limin Wang
0
0
Occupancy prediction plays a pivotal role in autonomous driving. Previous methods typically construct dense 3D volumes, neglecting the inherent sparsity of the scene and suffering high computational costs. To bridge the gap, we introduce a novel fully sparse occupancy network, termed SparseOcc. SparseOcc initially reconstructs a sparse 3D representation from visual inputs and subsequently predicts semantic/instance occupancy from the 3D sparse representation by sparse queries. A mask-guided sparse sampling is designed to enable sparse queries to interact with 2D features in a fully sparse manner, thereby circumventing costly dense features or global attention. Additionally, we design a thoughtful ray-based evaluation metric, namely RayIoU, to solve the inconsistency penalty along depths raised in traditional voxel-level mIoU criteria. SparseOcc demonstrates its effectiveness by achieving a RayIoU of 34.0, while maintaining a real-time inference speed of 17.3 FPS, with 7 history frames inputs. By incorporating more preceding frames to 15, SparseOcc continuously improves its performance to 35.1 RayIoU without whistles and bells. Code is available at https://github.com/MCG-NJU/SparseOcc.
4/9/2024
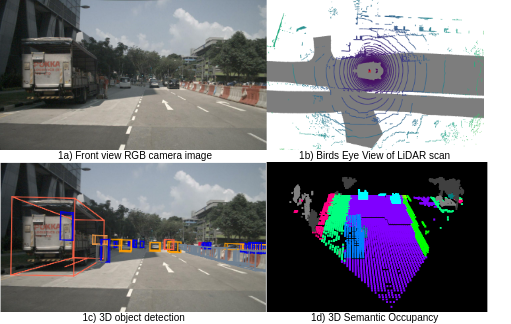
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
0
0
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
5/21/2024

COTR: Compact Occupancy TRansformer for Vision-based 3D Occupancy Prediction
Qihang Ma, Xin Tan, Yanyun Qu, Lizhuang Ma, Zhizhong Zhang, Yuan Xie
0
0
The autonomous driving community has shown significant interest in 3D occupancy prediction, driven by its exceptional geometric perception and general object recognition capabilities. To achieve this, current works try to construct a Tri-Perspective View (TPV) or Occupancy (OCC) representation extending from the Bird-Eye-View perception. However, compressed views like TPV representation lose 3D geometry information while raw and sparse OCC representation requires heavy but redundant computational costs. To address the above limitations, we propose Compact Occupancy TRansformer (COTR), with a geometry-aware occupancy encoder and a semantic-aware group decoder to reconstruct a compact 3D OCC representation. The occupancy encoder first generates a compact geometrical OCC feature through efficient explicit-implicit view transformation. Then, the occupancy decoder further enhances the semantic discriminability of the compact OCC representation by a coarse-to-fine semantic grouping strategy. Empirical experiments show that there are evident performance gains across multiple baselines, e.g., COTR outperforms baselines with a relative improvement of 8%-15%, demonstrating the superiority of our method.
4/12/2024

Unified Spatio-Temporal Tri-Perspective View Representation for 3D Semantic Occupancy Prediction
Sathira Silva, Savindu Bhashitha Wannigama, Gihan Jayatilaka, Muhammad Haris Khan, Roshan Ragel
0
0
Holistic understanding and reasoning in 3D scenes play a vital role in the success of autonomous driving systems. The evolution of 3D semantic occupancy prediction as a pretraining task for autonomous driving and robotic downstream tasks capture finer 3D details compared to methods like 3D detection. Existing approaches predominantly focus on spatial cues such as tri-perspective view embeddings (TPV), often overlooking temporal cues. This study introduces a spatiotemporal transformer architecture S2TPVFormer for temporally coherent 3D semantic occupancy prediction. We enrich the prior process by including temporal cues using a novel temporal cross-view hybrid attention mechanism (TCVHA) and generate spatiotemporal TPV embeddings (i.e. S2TPV embeddings). Experimental evaluations on the nuScenes dataset demonstrate a substantial 4.1% improvement in mean Intersection over Union (mIoU) for 3D Semantic Occupancy compared to TPVFormer, confirming the effectiveness of the proposed S2TPVFormer in enhancing 3D scene perception.
4/5/2024