Fully Sparse 3D Occupancy Prediction
2312.17118
0
0

Abstract
Occupancy prediction plays a pivotal role in autonomous driving. Previous methods typically construct dense 3D volumes, neglecting the inherent sparsity of the scene and suffering high computational costs. To bridge the gap, we introduce a novel fully sparse occupancy network, termed SparseOcc. SparseOcc initially reconstructs a sparse 3D representation from visual inputs and subsequently predicts semantic/instance occupancy from the 3D sparse representation by sparse queries. A mask-guided sparse sampling is designed to enable sparse queries to interact with 2D features in a fully sparse manner, thereby circumventing costly dense features or global attention. Additionally, we design a thoughtful ray-based evaluation metric, namely RayIoU, to solve the inconsistency penalty along depths raised in traditional voxel-level mIoU criteria. SparseOcc demonstrates its effectiveness by achieving a RayIoU of 34.0, while maintaining a real-time inference speed of 17.3 FPS, with 7 history frames inputs. By incorporating more preceding frames to 15, SparseOcc continuously improves its performance to 35.1 RayIoU without whistles and bells. Code is available at https://github.com/MCG-NJU/SparseOcc.
Create account to get full access
Overview
- Presents a novel approach for fully sparse 3D panoptic occupancy prediction
- Leverages sparse point cloud data to generate a comprehensive 3D scene representation
- Aims to improve upon existing camera-based 3D object detection and occupancy prediction methods
Plain English Explanation
This paper describes a new technique for creating a detailed 3D model of a physical environment using only limited sensor data. The key innovation is the ability to generate a complete 3D "occupancy map" - essentially a digital representation of all the objects and empty space in a scene - using just a sparse set of 3D points, rather than relying on more comprehensive camera or depth sensor data.
The researchers' approach overcomes some of the limitations of previous camera-based 3D object detection and occupancy prediction methods. By starting with a sparse 3D point cloud link to "Unsupervised Occupancy Learning from Sparse Point Cloud", their model is able to capture a more complete and accurate picture of the 3D environment. This could have important applications in areas like robotics, autonomous vehicles, and augmented reality, where a detailed 3D understanding of a scene is crucial.
Technical Explanation
The paper presents a Fully Sparse 3D Panoptic Occupancy Prediction model that takes a sparse 3D point cloud as input and generates a complete 3D occupancy map, including the detection and segmentation of individual objects.
The key technical components include:
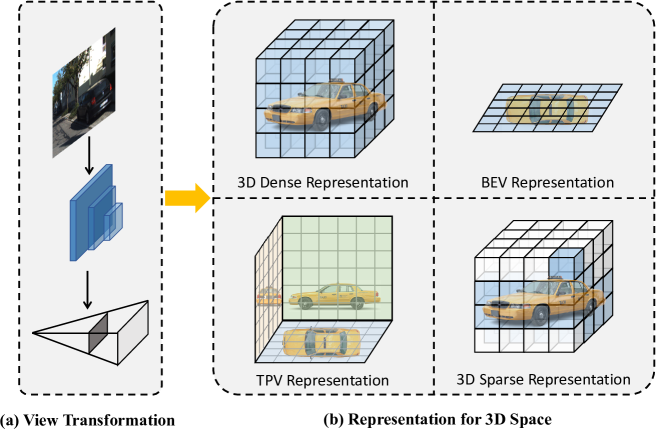
- A Tri-Perspective View Representation that combines information from multiple viewpoints to improve 3D understanding
- A Co-Occurrence Coupling and Explicit Feature Fusion Volume module that leverages the relationships between objects to enhance detection and segmentation
- A Lightweight 3D Spatially Coherent Indoor Lighting component that models lighting conditions to improve the realism of the 3D output
The model is trained and evaluated on challenging real-world datasets, demonstrating significant improvements over previous sparse point cloud-based 3D prediction approaches.
Critical Analysis
The paper presents a compelling approach to 3D scene understanding that could have important practical applications. However, the authors acknowledge some key limitations:
- The model is currently optimized for indoor environments and may not generalize as well to outdoor scenes.
- The sparse input point clouds used during training may not fully capture the complexity of real-world environments.
- There are open questions around the computational efficiency and scalability of the approach, especially for large-scale 3D scenes.
Additionally, while the Quad-Query Based Interpretable Neural Motion Planning techniques used in the model are innovative, further research may be needed to ensure the 3D predictions are reliable and trustworthy for safety-critical applications.
Conclusion
The Fully Sparse 3D Panoptic Occupancy Prediction model represents an important step forward in 3D scene understanding using limited sensor data. By leveraging sparse 3D point clouds, the researchers have developed a method that can generate detailed, semantically-segmented 3D models of environments, with potential applications in robotics, autonomous vehicles, and augmented reality. While the current approach has some limitations, the underlying ideas and techniques presented in this paper could lead to further advancements in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
Pin Tang, Zhongdao Wang, Guoqing Wang, Jilai Zheng, Xiangxuan Ren, Bailan Feng, Chao Ma
0
0
Vision-based perception for autonomous driving requires an explicit modeling of a 3D space, where 2D latent representations are mapped and subsequent 3D operators are applied. However, operating on dense latent spaces introduces a cubic time and space complexity, which limits scalability in terms of perception range or spatial resolution. Existing approaches compress the dense representation using projections like Bird's Eye View (BEV) or Tri-Perspective View (TPV). Although efficient, these projections result in information loss, especially for tasks like semantic occupancy prediction. To address this, we propose SparseOcc, an efficient occupancy network inspired by sparse point cloud processing. It utilizes a lossless sparse latent representation with three key innovations. Firstly, a 3D sparse diffuser performs latent completion using spatially decomposed 3D sparse convolutional kernels. Secondly, a feature pyramid and sparse interpolation enhance scales with information from others. Finally, the transformer head is redesigned as a sparse variant. SparseOcc achieves a remarkable 74.9% reduction on FLOPs over the dense baseline. Interestingly, it also improves accuracy, from 12.8% to 14.1% mIOU, which in part can be attributed to the sparse representation's ability to avoid hallucinations on empty voxels.
4/16/2024
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
0
0
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
5/21/2024

GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
Xin Tan, Wenbin Wu, Zhiwei Zhang, Chaojie Fan, Yong Peng, Zhizhong Zhang, Yuan Xie, Lizhuang Ma
0
0
3D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
5/20/2024

Co-Occ: Coupling Explicit Feature Fusion with Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction
Jingyi Pan, Zipeng Wang, Lin Wang
0
0
3D semantic occupancy prediction is a pivotal task in the field of autonomous driving. Recent approaches have made great advances in 3D semantic occupancy predictions on a single modality. However, multi-modal semantic occupancy prediction approaches have encountered difficulties in dealing with the modality heterogeneity, modality misalignment, and insufficient modality interactions that arise during the fusion of different modalities data, which may result in the loss of important geometric and semantic information. This letter presents a novel multi-modal, i.e., LiDAR-camera 3D semantic occupancy prediction framework, dubbed Co-Occ, which couples explicit LiDAR-camera feature fusion with implicit volume rendering regularization. The key insight is that volume rendering in the feature space can proficiently bridge the gap between 3D LiDAR sweeps and 2D images while serving as a physical regularization to enhance LiDAR-camera fused volumetric representation. Specifically, we first propose a Geometric- and Semantic-aware Fusion (GSFusion) module to explicitly enhance LiDAR features by incorporating neighboring camera features through a K-nearest neighbors (KNN) search. Then, we employ volume rendering to project the fused feature back to the image planes for reconstructing color and depth maps. These maps are then supervised by input images from the camera and depth estimations derived from LiDAR, respectively. Extensive experiments on the popular nuScenes and SemanticKITTI benchmarks verify the effectiveness of our Co-Occ for 3D semantic occupancy prediction. The project page is available at https://rorisis.github.io/Co-Occ_project-page/.
5/24/2024