Vidu4D: Single Generated Video to High-Fidelity 4D Reconstruction with Dynamic Gaussian Surfels
2405.16822
0
0

Abstract
Video generative models are receiving particular attention given their ability to generate realistic and imaginative frames. Besides, these models are also observed to exhibit strong 3D consistency, significantly enhancing their potential to act as world simulators. In this work, we present Vidu4D, a novel reconstruction model that excels in accurately reconstructing 4D (i.e., sequential 3D) representations from single generated videos, addressing challenges associated with non-rigidity and frame distortion. This capability is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. At the core of Vidu4D is our proposed Dynamic Gaussian Surfels (DGS) technique. DGS optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. This transformation enables a precise depiction of motion and deformation over time. To preserve the structural integrity of surface-aligned Gaussian surfels, we design the warped-state geometric regularization based on continuous warping fields for estimating normals. Additionally, we learn refinements on rotation and scaling parameters of Gaussian surfels, which greatly alleviates texture flickering during the warping process and enhances the capture of fine-grained appearance details. Vidu4D also contains a novel initialization state that provides a proper start for the warping fields in DGS. Equipping Vidu4D with an existing video generative model, the overall framework demonstrates high-fidelity text-to-4D generation in both appearance and geometry.
Create account to get full access
Overview
- This paper presents Vidu4D, a system that can reconstruct high-fidelity 4D models (3D geometry over time) from a single generated video.
- The key innovation is the use of dynamic Gaussian surfels, which can efficiently represent and update the 3D geometry over time.
- Vidu4D can generate realistic 4D reconstructions from a single video, outperforming previous methods that relied on multiple input views.
Plain English Explanation
Vidu4D is a system that can take a single video and use it to create a detailed 3D model that changes over time. This is called a "4D" model, because it has 3 spatial dimensions plus the dimension of time.
The paper introduces a new way of representing the 3D shapes in the video, using something called "dynamic Gaussian surfels." These are basically little 3D shapes that can change and move around to match the objects in the video. By using this efficient representation, Vidu4D can create high-quality 4D reconstructions from just a single video, without needing multiple camera views like previous methods did.
This is a significant advance, as being able to reconstruct 4D models from a single video has many practical applications, such as in animation, virtual reality, and 3D scanning. The dynamic Gaussian surfels allow Vidu4D to capture the detailed motion and shape changes in the video in a compact and efficient way.
Technical Explanation
The key innovation in Vidu4D is the use of dynamic Gaussian surfels to represent the 3D geometry over time. Unlike previous methods that used rigid 3D meshes, dynamic Gaussian surfels can efficiently capture the deformation and motion of objects in the video.
The Vidu4D system takes a single video as input and outputs a high-fidelity 4D reconstruction, which is a sequence of 3D models that evolve over time. To achieve this, Vidu4D uses a differentiable renderer to optimize the parameters of the dynamic Gaussian surfels, fitting them to the input video.
The surfels are initialized using a video-to-3D reconstruction method, and then their positions, sizes, and other properties are continuously updated to match the motion in the video. This allows Vidu4D to generate highly consistent and realistic 4D reconstructions from a single input video.
Critical Analysis
The Vidu4D paper makes a significant contribution by demonstrating the ability to reconstruct high-fidelity 4D models from a single video input. However, the paper does acknowledge some limitations:
- The method relies on the availability of a high-quality input video, and may struggle with low-resolution or noisy footage.
- The dynamic Gaussian surfels representation, while efficient, may not be able to capture all the nuances of complex, detailed deformations.
- The optimization process used to fit the surfels to the video can be computationally expensive, limiting the scalability of the approach.
Additionally, the paper does not explore the potential biases or failure modes of the system, such as how it might perform on videos depicting underrepresented subjects or scenarios. Further research is needed to better understand the limitations and potential issues with Vidu4D.
Conclusion
Overall, the Vidu4D system represents an important step forward in the field of 4D reconstruction from video. By leveraging dynamic Gaussian surfels, the method can generate high-quality, temporally consistent 4D models from a single input video, without the need for multiple camera views. This has exciting implications for applications like virtual reality, animation, and 3D scanning, where access to detailed 4D data is crucial. While the approach has some limitations, the paper demonstrates the potential of this innovative technique and opens up avenues for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DreamGaussian4D: Generative 4D Gaussian Splatting
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, Ziwei Liu
0
0
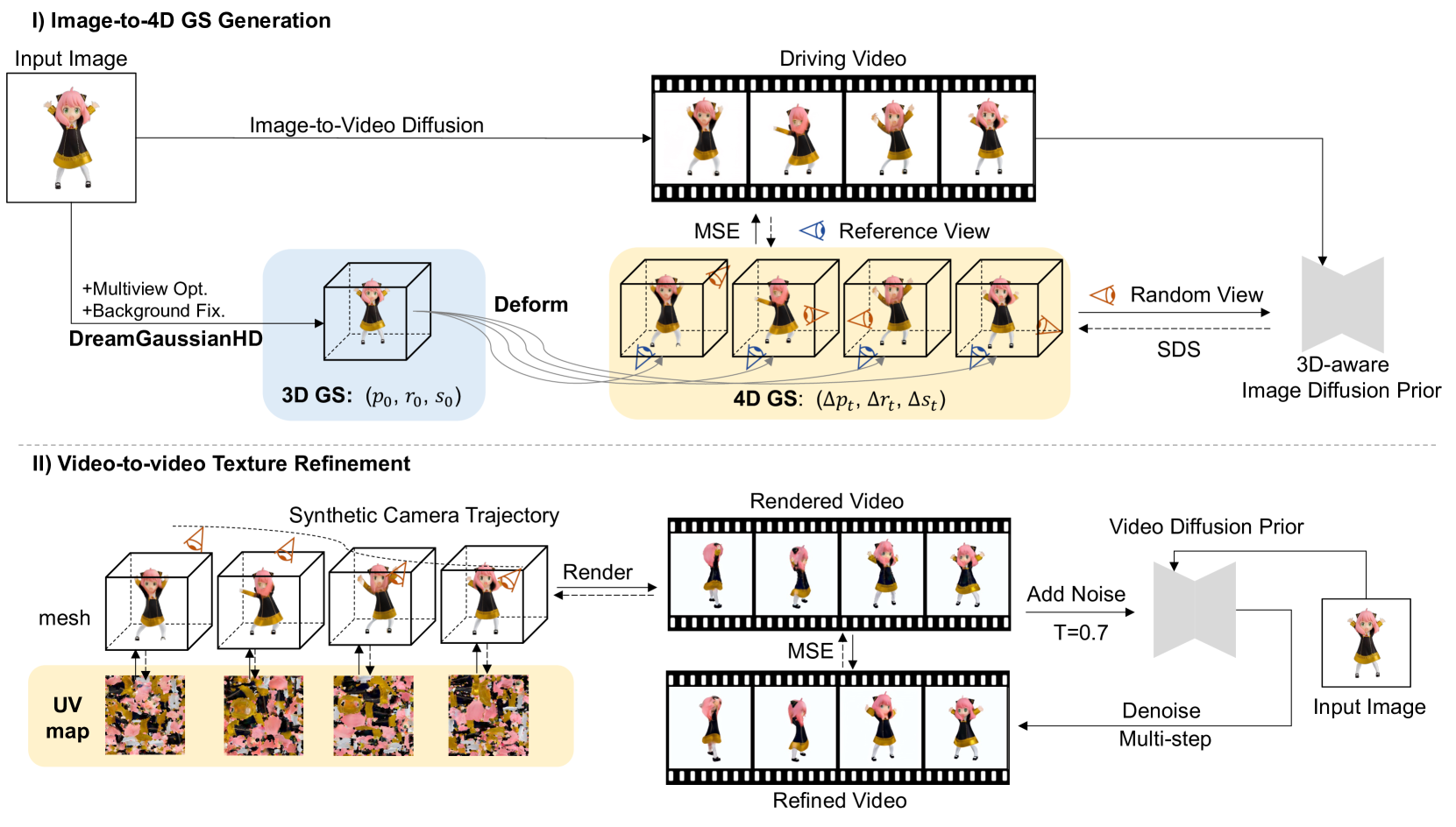
4D content generation has achieved remarkable progress recently. However, existing methods suffer from long optimization times, a lack of motion controllability, and a low quality of details. In this paper, we introduce DreamGaussian4D (DG4D), an efficient 4D generation framework that builds on Gaussian Splatting (GS). Our key insight is that combining explicit modeling of spatial transformations with static GS makes an efficient and powerful representation for 4D generation. Moreover, video generation methods have the potential to offer valuable spatial-temporal priors, enhancing the high-quality 4D generation. Specifically, we propose an integral framework with two major modules: 1) Image-to-4D GS - we initially generate static GS with DreamGaussianHD, followed by HexPlane-based dynamic generation with Gaussian deformation; and 2) Video-to-Video Texture Refinement - we refine the generated UV-space texture maps and meanwhile enhance their temporal consistency by utilizing a pre-trained image-to-video diffusion model. Notably, DG4D reduces the optimization time from several hours to just a few minutes, allows the generated 3D motion to be visually controlled, and produces animated meshes that can be realistically rendered in 3D engines.
6/11/2024
EG4D: Explicit Generation of 4D Object without Score Distillation
Qi Sun, Zhiyang Guo, Ziyu Wan, Jing Nathan Yan, Shengming Yin, Wengang Zhou, Jing Liao, Houqiang Li
0
0
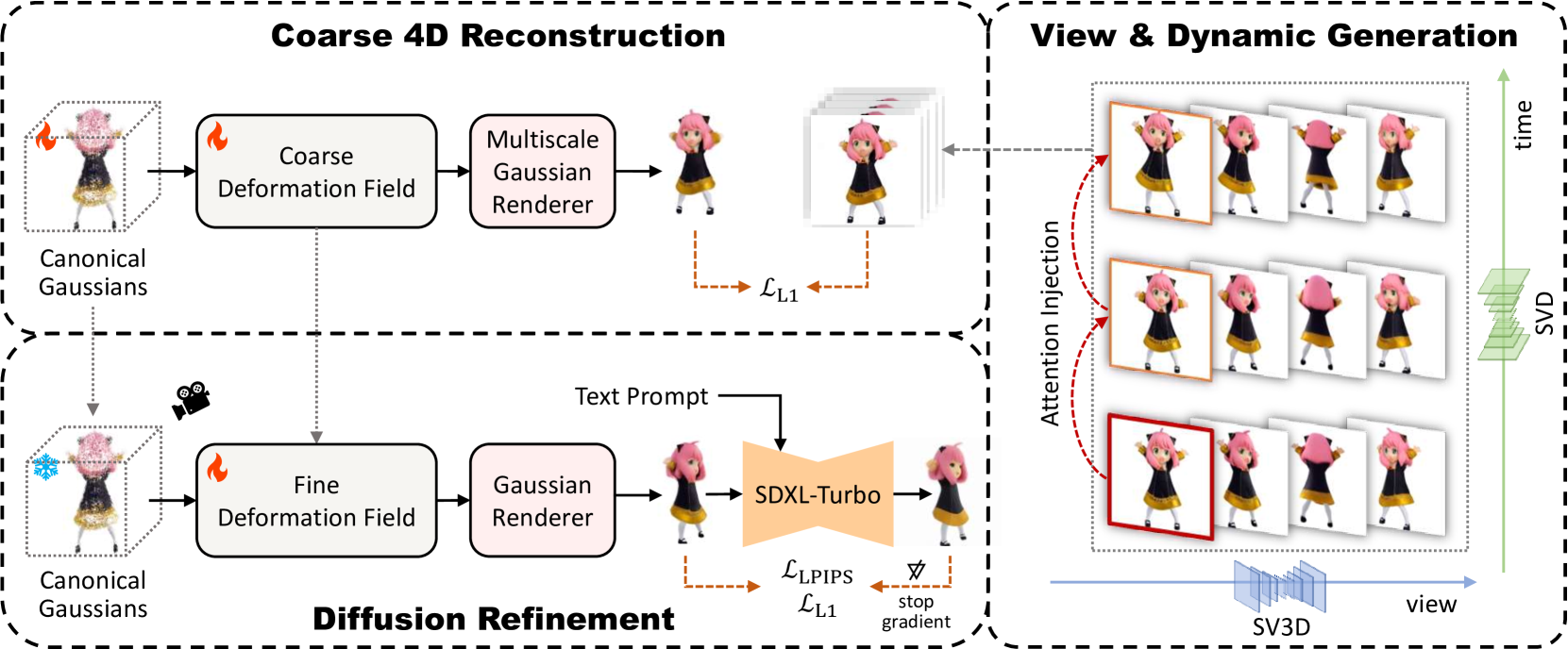
In recent years, the increasing demand for dynamic 3D assets in design and gaming applications has given rise to powerful generative pipelines capable of synthesizing high-quality 4D objects. Previous methods generally rely on score distillation sampling (SDS) algorithm to infer the unseen views and motion of 4D objects, thus leading to unsatisfactory results with defects like over-saturation and Janus problem. Therefore, inspired by recent progress of video diffusion models, we propose to optimize a 4D representation by explicitly generating multi-view videos from one input image. However, it is far from trivial to handle practical challenges faced by such a pipeline, including dramatic temporal inconsistency, inter-frame geometry and texture diversity, and semantic defects brought by video generation results. To address these issues, we propose DG4D, a novel multi-stage framework that generates high-quality and consistent 4D assets without score distillation. Specifically, collaborative techniques and solutions are developed, including an attention injection strategy to synthesize temporal-consistent multi-view videos, a robust and efficient dynamic reconstruction method based on Gaussian Splatting, and a refinement stage with diffusion prior for semantic restoration. The qualitative results and user preference study demonstrate that our framework outperforms the baselines in generation quality by a considerable margin. Code will be released at url{https://github.com/jasongzy/EG4D}.
5/29/2024
🛸
4Real: Towards Photorealistic 4D Scene Generation via Video Diffusion Models
Heng Yu, Chaoyang Wang, Peiye Zhuang, Willi Menapace, Aliaksandr Siarohin, Junli Cao, Laszlo A Jeni, Sergey Tulyakov, Hsin-Ying Lee
0
0
Existing dynamic scene generation methods mostly rely on distilling knowledge from pre-trained 3D generative models, which are typically fine-tuned on synthetic object datasets. As a result, the generated scenes are often object-centric and lack photorealism. To address these limitations, we introduce a novel pipeline designed for photorealistic text-to-4D scene generation, discarding the dependency on multi-view generative models and instead fully utilizing video generative models trained on diverse real-world datasets. Our method begins by generating a reference video using the video generation model. We then learn the canonical 3D representation of the video using a freeze-time video, delicately generated from the reference video. To handle inconsistencies in the freeze-time video, we jointly learn a per-frame deformation to model these imperfections. We then learn the temporal deformation based on the canonical representation to capture dynamic interactions in the reference video. The pipeline facilitates the generation of dynamic scenes with enhanced photorealism and structural integrity, viewable from multiple perspectives, thereby setting a new standard in 4D scene generation.
6/12/2024
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Fan Wang, Xiang Bai
0
0
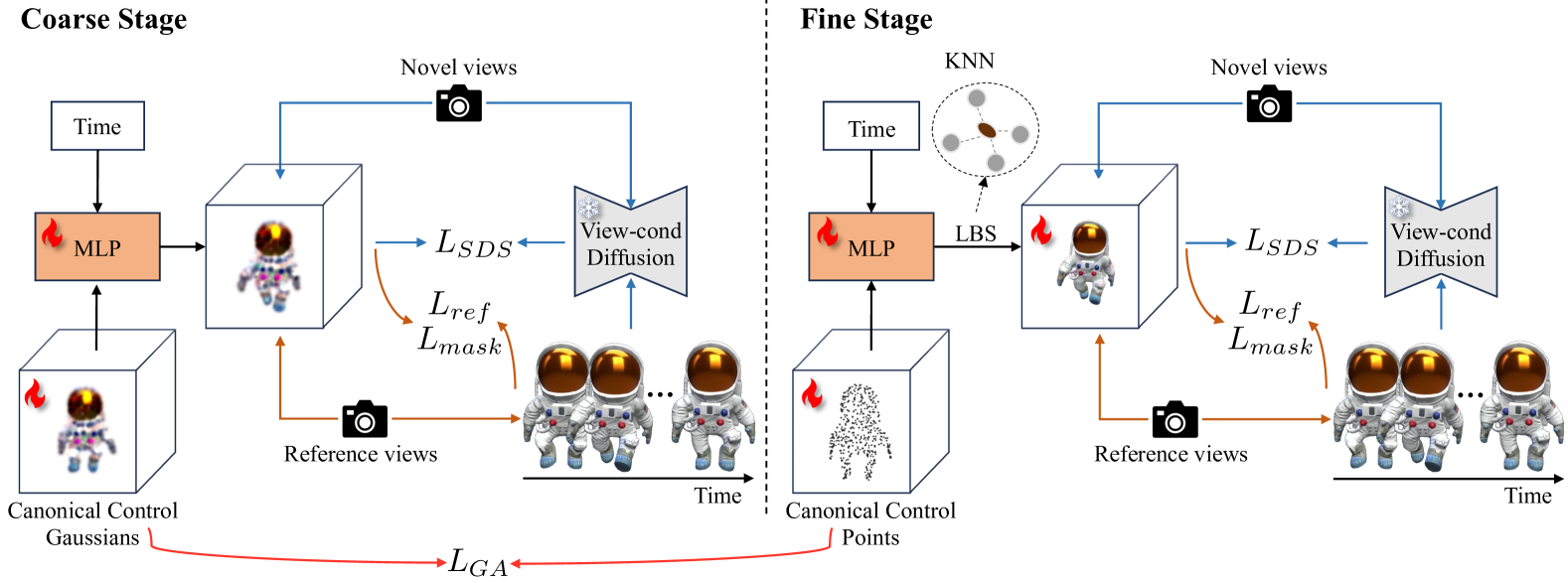
Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
4/8/2024