Loki: Low-Rank Keys for Efficient Sparse Attention

0
Sign in to get full access
Overview
- Introduces a new attention mechanism called Loki, which uses low-rank keys for efficient sparse attention
- Loki aims to improve the efficiency and scalability of attention mechanisms in large language models
- Key ideas include using low-rank key representations and sparse attention patterns to reduce computational and memory costs
Plain English Explanation
Attention is a crucial component of many advanced AI models, including large language models that can generate human-like text. However, the attention mechanism can be computationally expensive, especially as models grow larger. Loki: Low-Rank Keys for Efficient Sparse Attention proposes a new attention mechanism called Loki that aims to improve the efficiency and scalability of attention.
The key idea behind Loki is to use low-rank representations for the attention keys. This means compressing the information in the keys down to a smaller number of dimensions, which can reduce the computational and memory costs of the attention calculations. Loki also uses a sparse attention pattern, where each query only attends to a subset of the keys, further improving efficiency.
By using these techniques, Loki is able to maintain the performance of standard attention mechanisms while significantly reducing the computational resources required. This could enable the use of larger and more capable language models, which often have high computational demands, on a wider range of hardware. Loki's efficiency improvements build on related work in efficient attention mechanisms and attention reuse.
Technical Explanation
Loki: Low-Rank Keys for Efficient Sparse Attention proposes a new attention mechanism that aims to improve the efficiency and scalability of attention in large language models. The key innovations include:
- Low-rank key representations: The attention keys are compressed to a lower-dimensional representation, reducing the computational and memory costs of the attention calculations.
- Sparse attention patterns: Each query only attends to a sparse subset of the keys, further improving efficiency by reducing the number of attention computations required.
The paper evaluates Loki on a range of language modeling tasks, including machine translation and question answering. Compared to standard attention mechanisms, Loki is able to achieve similar performance while using significantly less computational resources, such as memory and FLOPs.
The efficiency gains of Loki build on related work in efficient attention mechanisms and attention reuse. By improving the efficiency of attention, Loki could enable the use of larger and more capable language models on a wider range of hardware platforms.
Critical Analysis
The Loki paper presents a promising approach for improving the efficiency of attention mechanisms in large language models. The use of low-rank key representations and sparse attention patterns are well-motivated techniques that have been explored in related work, such as Easy Attention and Self-Selected Attention Span.
One potential limitation of the Loki approach is that the performance trade-offs may not be suitable for all applications. While the paper demonstrates that Loki can achieve similar performance to standard attention on some tasks, the performance impact may be more significant in other domains or for more specialized language models. Further research would be needed to understand the broader applicability and limitations of the Loki approach.
Additionally, the paper does not provide a deep analysis of the mechanisms underlying the efficiency improvements of Loki. A more detailed exploration of the factors contributing to the computational and memory savings could help researchers better understand the advantages and potential drawbacks of the approach.
Overall, the Loki paper presents a compelling technique for improving the efficiency of attention mechanisms, which could have significant implications for the development of larger and more capable language models. However, continued research and evaluation will be necessary to fully understand the strengths, weaknesses, and broader applicability of this approach.
Conclusion
Loki: Low-Rank Keys for Efficient Sparse Attention introduces a new attention mechanism that uses low-rank key representations and sparse attention patterns to improve the efficiency and scalability of attention in large language models. By reducing the computational and memory costs of attention, Loki could enable the use of larger and more capable language models on a wider range of hardware platforms. This work builds on and complements related research in efficient attention mechanisms and attention reuse. Further research is needed to fully understand the strengths, weaknesses, and broader applicability of the Loki approach, but the paper presents a promising step forward in improving the efficiency of attention in advanced AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Loki: Low-Rank Keys for Efficient Sparse Attention
Prajwal Singhania, Siddharth Singh, Shwai He, Soheil Feizi, Abhinav Bhatele
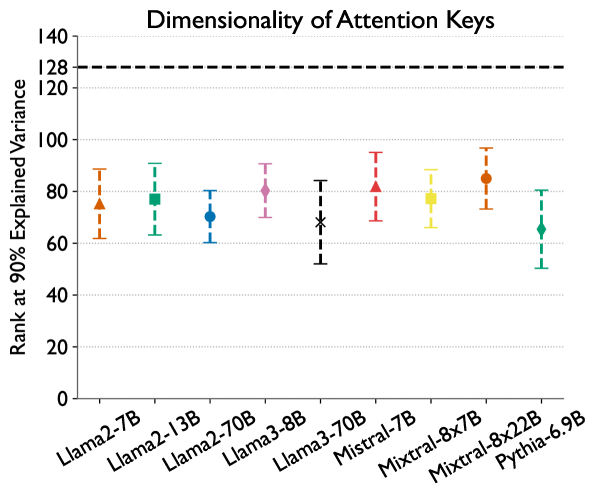
Inference on large language models can be expensive in terms of the compute and memory costs involved, especially when long sequence lengths are used. In particular, the self-attention mechanism used in such models contributes significantly to these costs, which has resulted in several recent works that propose sparse attention approximations for inference. In this work, we propose to approximate the self-attention computation by focusing on the dimensionality of key vectors computed in the attention block. Our analysis reveals that the key vectors lie in a significantly lower-dimensional space, consistently across several datasets and models. Exploiting this observation, we propose Loki, a novel sparse attention method that ranks and selects tokens in the KV-cache based on attention scores computed in low-dimensional space. Our evaluations show that Loki is able to maintain the efficacy of the models better than other popular approximation methods, while speeding up the attention computation due to reduced data movement (load/store) and compute costs.
Read more6/5/2024

0
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Utkarsh Saxena, Gobinda Saha, Sakshi Choudhary, Kaushik Roy
Large language models (LLMs) represent a groundbreaking advancement in the domain of natural language processing due to their impressive reasoning abilities. Recently, there has been considerable interest in increasing the context lengths for these models to enhance their applicability to complex tasks. However, at long context lengths and large batch sizes, the key-value (KV) cache, which stores the attention keys and values, emerges as the new bottleneck in memory usage during inference. To address this, we propose Eigen Attention, which performs the attention operation in a low-rank space, thereby reducing the KV cache memory overhead. Our proposed approach is orthogonal to existing KV cache compression techniques and can be used synergistically with them. Through extensive experiments over OPT, MPT, and Llama model families, we demonstrate that Eigen Attention results in up to 40% reduction in KV cache sizes and up to 60% reduction in attention operation latency with minimal drop in performance.
Read more8/13/2024

0
Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers
Chao Lou, Zixia Jia, Zilong Zheng, Kewei Tu
Accommodating long sequences efficiently in autoregressive Transformers, especially within an extended context window, poses significant challenges due to the quadratic computational complexity and substantial KV memory requirements inherent in self-attention mechanisms. In this work, we introduce SPARSEK Attention, a novel sparse attention mechanism designed to overcome these computational and memory obstacles while maintaining performance. Our approach integrates a scoring network and a differentiable top-k mask operator, SPARSEK, to select a constant number of KV pairs for each query, thereby enabling gradient-based optimization. As a result, SPARSEK Attention offers linear time complexity and constant memory footprint during generation. Experimental results reveal that SPARSEK Attention outperforms previous sparse attention methods and provides significant speed improvements during both training and inference, particularly in language modeling and downstream tasks. Furthermore, our method can be seamlessly integrated into pre-trained Large Language Models (LLMs) with minimal fine-tuning, offering a practical solution for effectively managing long-range dependencies in diverse applications.
Read more6/26/2024

0
Post-Training Sparse Attention with Double Sparsity
Shuo Yang, Ying Sheng, Joseph E. Gonzalez, Ion Stoica, Lianmin Zheng
The inference process for large language models is slow and memory-intensive, with one of the most critical bottlenecks being excessive Key-Value (KV) cache accesses. This paper introduces Double Sparsity, a novel post-training sparse attention technique designed to alleviate this bottleneck by reducing KV cache access. Double Sparsity combines token sparsity, which focuses on utilizing only the important tokens for computing self-attention, with channel sparsity, an approach that uses important feature channels for identifying important tokens. Our key insight is that the pattern of channel sparsity is relatively static, allowing us to use offline calibration to make it efficient at runtime, thereby enabling accurate and efficient identification of important tokens. Moreover, this method can be combined with offloading to achieve significant memory usage reduction. Experimental results demonstrate that Double Sparsity can achieve $frac{1}{16}$ token and channel sparsity with minimal impact on accuracy across various tasks, including wiki-2 perplexity, key-value retrieval, and long context benchmarks with models including Llama-2-7B, Llama-2-70B, and Mixtral-8x7B. It brings up to a 14.1$times$ acceleration in attention operations and a 1.9$times$ improvement in end-to-end inference on GPUs. With offloading, it achieves a decoding speed acceleration of 16.3$times$ compared to state-of-the-art solutions at a sequence length of 256K. Our code is publicly available at https://github.com/andy-yang-1/DoubleSparse.
Read more8/20/2024