Eigenpruning
2404.03147
0
0

Abstract
We introduce eigenpruning, a method that removes singular values from weight matrices in an LLM to improve its performance in a particular task. This method is inspired by interpretability methods designed to automatically find subnetworks of a model which solve a specific task. In our tests, the pruned model outperforms the original model by a large margin, while only requiring minimal computation to prune the weight matrices. In the case of a small synthetic task in integer multiplication, the Phi-2 model can improve its accuracy in the test set from 13.75% to 97.50%. Interestingly, these results seem to indicate the existence of a computation path that can solve the task very effectively, but it was not being used by the original model. Finally, we publicly release our implementation.
Create account to get full access
Overview
- Eigenpruning is a novel technique for efficiently pruning neural networks by leveraging the eigenstructure of the weight matrices.
- The method aims to remove redundant parameters while preserving the network's performance, leading to more compact and efficient models.
- It involves analyzing the eigenvalues and eigenvectors of the weight matrices to identify unimportant parameters that can be safely removed.
- The approach is demonstrated on various neural network architectures and tasks, showing significant reductions in model size and computational requirements without substantial accuracy loss.
Plain English Explanation
Eigenpruning is a clever way to make machine learning models smaller and faster, without losing their performance. Neural networks, which are the foundation of many modern AI systems, can often have a lot of unnecessary parameters that don't contribute much to the final results. Eigenpruning looks at the internal structure of these networks - the eigenvalues and eigenvectors of the weight matrices - to identify which parts of the model are the most important and which ones can be safely removed.
Imagine a neural network as a complicated machine with many gears and cogs. Eigenpruning is like finding the essential gears that are doing most of the work, and removing the extra ones that aren't contributing much. This makes the machine smaller, lighter, and more efficient, without changing its core functionality.
By applying this technique, researchers have been able to significantly reduce the size and computational requirements of various neural network models, while still maintaining their accuracy on different tasks. This is particularly important for deploying AI systems on resource-constrained devices, like smartphones or embedded systems, where efficiency and compactness are crucial.
Technical Explanation
The paper introduces Eigenpruning, a novel approach for pruning neural networks by leveraging the eigenstructure of the weight matrices. The key idea is to identify and remove the parameters that contribute the least to the network's performance, based on an analysis of the eigenvalues and eigenvectors.
The method works as follows:
- For each layer in the neural network, the weight matrix is decomposed into its eigenvalues and eigenvectors.
- The eigenvectors corresponding to the smallest eigenvalues are considered to be the least important and are used to identify the parameters that can be pruned.
- The pruned network is then fine-tuned to recover any potential performance loss.
The authors evaluate Eigenpruning on various neural network architectures, including convolutional networks for image classification and transformer-based models for natural language processing. The results demonstrate significant reductions in model size and computational requirements, often exceeding 50% pruning rates, with negligible accuracy degradation.
The paper also provides theoretical insights into the connection between the eigenstructure and the network's performance, showing that the eigenvectors with the smallest eigenvalues correspond to the most redundant parameters.
Critical Analysis
The Eigenpruning technique presented in the paper is a promising approach for efficient neural network compression. By leveraging the eigenstructure of the weight matrices, the method can effectively identify and remove redundant parameters without substantially impacting the model's performance.
One potential limitation is that the paper focuses primarily on feedforward neural networks and convolutional architectures. It would be interesting to see how Eigenpruning performs on more complex models, such as recurrent neural networks or graph neural networks, which may have different eigenstructure characteristics.
Additionally, the paper does not provide a detailed analysis of the computational complexity of the Eigenpruning algorithm, which could be an important consideration for real-world deployment, especially on resource-constrained devices.
While the results are promising, further research could explore ways to refine the Eigenpruning approach, such as developing more sophisticated parameter selection criteria or investigating the impact of different fine-tuning strategies. Exploring the interplay between Eigenpruning and other compression techniques, like quantization or distillation, could also yield interesting insights.
Overall, the Eigenpruning technique represents a valuable contribution to the field of neural network compression, and the insights presented in the paper could inspire future research in this area.
Conclusion
Eigenpruning is a novel and effective technique for compressing neural networks by leveraging the eigenstructure of the weight matrices. By identifying and removing the least important parameters, the method can significantly reduce the size and computational requirements of various neural network architectures without substantially compromising their performance.
This advancement in neural network compression has important implications for the deployment of AI systems, particularly in resource-constrained environments like mobile devices or embedded systems, where efficiency and compactness are crucial. The insights and techniques presented in this paper could also spur further research and development in the field of model optimization, ultimately leading to more robust and accessible AI solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Subspace Node Pruning
Joshua Offergeld, Marcel van Gerven, Nasir Ahmad
0
0
A significant increase in the commercial use of deep neural network models increases the need for efficient AI. Node pruning is the art of removing computational units such as neurons, filters, attention heads, or even entire layers while keeping network performance at a maximum. This can significantly reduce the inference time of a deep network and thus enhance its efficiency. Few of the previous works have exploited the ability to recover performance by reorganizing network parameters while pruning. In this work, we propose to create a subspace from unit activations which enables node pruning while recovering maximum accuracy. We identify that for effective node pruning, a subspace can be created using a triangular transformation matrix, which we show to be equivalent to Gram-Schmidt orthogonalization, which automates this procedure. We further improve this method by reorganizing the network prior to subspace formation. Finally, we leverage the orthogonal subspaces to identify layer-wise pruning ratios appropriate to retain a significant amount of the layer-wise information. We show that this measure outperforms existing pruning methods on VGG networks. We further show that our method can be extended to other network architectures such as residual networks.
5/29/2024
↗️
Pruning is Optimal for Learning Sparse Features in High-Dimensions
Nuri Mert Vural, Murat A. Erdogdu
0
0
While it is commonly observed in practice that pruning networks to a certain level of sparsity can improve the quality of the features, a theoretical explanation of this phenomenon remains elusive. In this work, we investigate this by demonstrating that a broad class of statistical models can be optimally learned using pruned neural networks trained with gradient descent, in high-dimensions. We consider learning both single-index and multi-index models of the form $y = sigma^*(boldsymbol{V}^{top} boldsymbol{x}) + epsilon$, where $sigma^*$ is a degree-$p$ polynomial, and $boldsymbol{V} in mathbbm{R}^{d times r}$ with $r ll d$, is the matrix containing relevant model directions. We assume that $boldsymbol{V}$ satisfies a certain $ell_q$-sparsity condition for matrices and show that pruning neural networks proportional to the sparsity level of $boldsymbol{V}$ improves their sample complexity compared to unpruned networks. Furthermore, we establish Correlational Statistical Query (CSQ) lower bounds in this setting, which take the sparsity level of $boldsymbol{V}$ into account. We show that if the sparsity level of $boldsymbol{V}$ exceeds a certain threshold, training pruned networks with a gradient descent algorithm achieves the sample complexity suggested by the CSQ lower bound. In the same scenario, however, our results imply that basis-independent methods such as models trained via standard gradient descent initialized with rotationally invariant random weights can provably achieve only suboptimal sample complexity.
6/14/2024
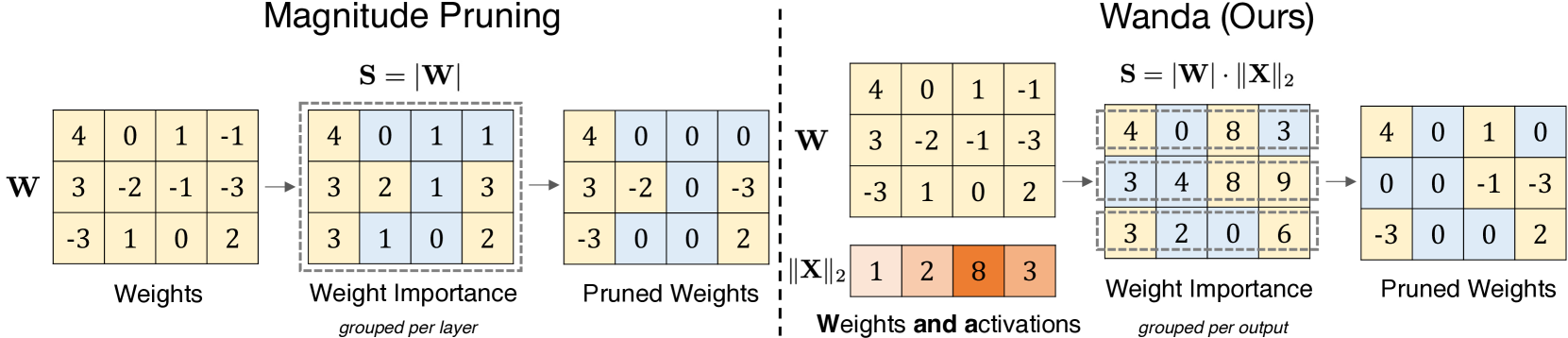
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter
0
0
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prunes weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method Wanda on LLaMA and LLaMA-2 across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and performs competitively against recent method involving intensive weight update. Code is available at https://github.com/locuslab/wanda.
5/7/2024

Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
0
0
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
6/18/2024