A Simple and Effective Pruning Approach for Large Language Models
2306.11695
2
0
Abstract
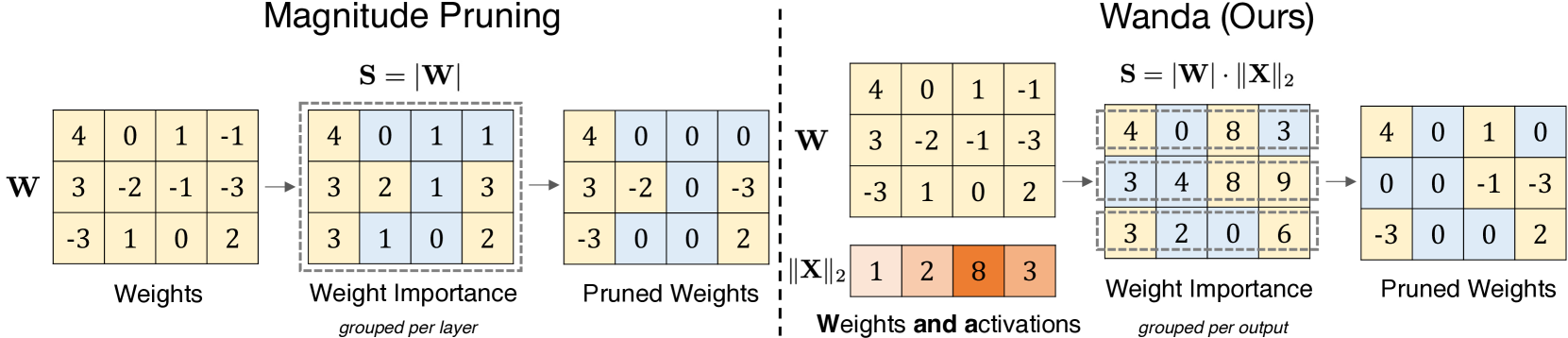
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prunes weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method Wanda on LLaMA and LLaMA-2 across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and performs competitively against recent method involving intensive weight update. Code is available at https://github.com/locuslab/wanda.
Create account to get full access
Overview
- Proposes a simple and effective pruning approach for large language models
- Focuses on balancing model performance and model size reduction
- Demonstrates the effectiveness of the approach on various language models
Plain English Explanation
The paper presents a novel pruning technique for large language models, which are complex AI systems trained on massive amounts of text data to perform tasks like natural language processing and generation. Pruning is the process of removing unnecessary connections or parameters from a trained model to reduce its size and inference time, while maintaining its performance.
The authors' approach is designed to be simple and effective, aiming to strike a balance between model performance and model size reduction. By carefully selecting which connections or parameters to remove, the pruned model can achieve significant size reduction without substantial performance degradation.
The researchers evaluate their pruning method on various popular language models, including BERT, GPT-2, and GLUE. The results demonstrate the effectiveness of their approach in achieving substantial model size reduction while maintaining model performance.
Technical Explanation
The paper proposes a pruning approach that aims to preserve the most important connections or parameters in the language model. The key steps are:
-
Gradient-based Importance Estimation: The method calculates the gradient of the model's output with respect to each parameter, which provides a measure of the parameter's importance in the model's decision-making process.
-
Iterative Pruning: The authors then iteratively remove the least important parameters, as determined by the gradient-based importance estimation, and fine-tune the pruned model to recover any performance degradation.
-
Pruned Model Evaluation: The researchers evaluate the pruned model's performance on various benchmarks, such as the BESA and One-Shot datasets, to ensure the effectiveness of their pruning approach.
The experiments demonstrate that the proposed method can achieve significant model size reduction (up to 90%) without substantial performance degradation, outperforming various baseline pruning techniques.
Critical Analysis
The paper presents a practical and effective pruning approach for large language models, which is an important area of research for improving the efficiency and deployability of these complex AI systems. The authors' focus on balancing model performance and size reduction is well-justified, as it addresses a critical challenge in real-world applications.
However, the paper could have provided more discussion on the potential limitations or caveats of the proposed approach. For example, the authors could have explored the impact of the pruning method on model robustness, transferability, or fairness. Additionally, a deeper analysis of the relationship between the gradient-based importance estimation and the final model performance could shed light on the underlying mechanisms of the pruning technique.
Furthermore, the authors could have compared their approach to other recent advancements in pruning for large language models, such as the work on mixed sparsity pruning or the BESA pruning method, to provide a more comprehensive evaluation of their contribution.
Conclusion
The paper presents a simple and effective pruning approach for large language models that can achieve substantial model size reduction without significant performance degradation. The authors' focus on balancing model performance and size reduction is a crucial consideration for real-world applications of these complex AI systems.
While the paper could have delved deeper into the potential limitations and caveats of the proposed method, the overall contribution is valuable for the field of efficient and deployable language models. The results demonstrate the effectiveness of the authors' approach and provide a foundation for further research and optimization in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models
Rocktim Jyoti Das, Mingjie Sun, Liqun Ma, Zhiqiang Shen
0
0
Large Language Models (LLMs) with billions of parameters are prime targets for network pruning, removing some model weights without hurting performance. Prior approaches such as magnitude pruning, SparseGPT, and Wanda, either concentrated solely on weights or integrated weights with activations for sparsity. However, they overlooked the informative gradients derived from pretrained LLMs. In this paper, we present a novel sparsity-centric pruning method for pretrained LLMs, termed Gradient-based Language Model Pruner (GBLM-Pruner). GBLM-Pruner leverages the first-order term of the Taylor expansion, operating in a training-free manner by harnessing properly normalized gradients from a few calibration samples to determine the pruning metric, and substantially outperforms competitive counterparts like SparseGPT and Wanda in multiple benchmarks. Intriguingly, by incorporating gradients, unstructured pruning with our method tends to reveal some structural patterns, which mirrors the geometric interdependence inherent in the LLMs' parameter structure. Additionally, GBLM-Pruner functions without any subsequent retraining or weight updates to maintain its simplicity as other counterparts. Extensive evaluations on LLaMA-1 and LLaMA-2 across various benchmarks show that GBLM-Pruner surpasses magnitude pruning, Wanda and SparseGPT by significant margins. We further extend our approach on Vision Transformer. Our code and models are available at https://github.com/VILA-Lab/GBLM-Pruner.
4/10/2024

Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
0
0
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
6/18/2024
Large Language Model Pruning
Hanjuan Huang (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hao-Jia Song (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hsing-Kuo Pao (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan)
0
0
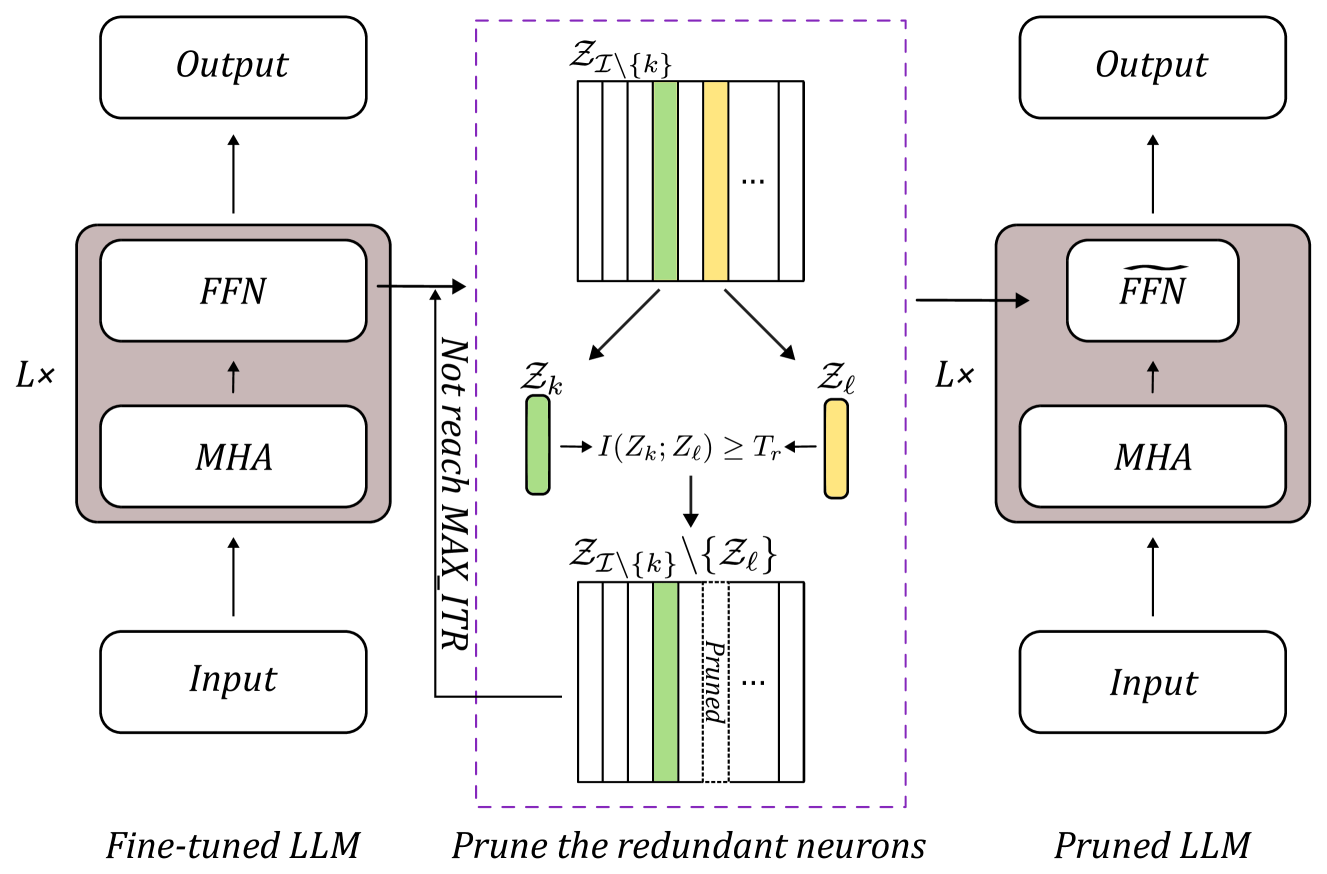
We surely enjoy the larger the better models for their superior performance in the last couple of years when both the hardware and software support the birth of such extremely huge models. The applied fields include text mining and others. In particular, the success of LLMs on text understanding and text generation draws attention from researchers who have worked on NLP and related areas for years or even decades. On the side, LLMs may suffer from problems like model overfitting, hallucination, and device limitation to name a few. In this work, we suggest a model pruning technique specifically focused on LLMs. The proposed methodology emphasizes the explainability of deep learning models. By having the theoretical foundation, we obtain a trustworthy deep model so that huge models with a massive number of model parameters become not quite necessary. A mutual information-based estimation is adopted to find neurons with redundancy to eliminate. Moreover, an estimator with well-tuned parameters helps to find precise estimation to guide the pruning procedure. At the same time, we also explore the difference between pruning on large-scale models vs. pruning on small-scale models. The choice of pruning criteria is sensitive in small models but not for large-scale models. It is a novel finding through this work. Overall, we demonstrate the superiority of the proposed model to the state-of-the-art models.
6/4/2024
💬
Shortened LLaMA: Depth Pruning for Large Language Models with Comparison of Retraining Methods
Bo-Kyeong Kim, Geonmin Kim, Tae-Ho Kim, Thibault Castells, Shinkook Choi, Junho Shin, Hyoung-Kyu Song
0
0
Structured pruning of modern large language models (LLMs) has emerged as a way of decreasing their high computational needs. Width pruning reduces the size of projection weight matrices (e.g., by removing attention heads) while maintaining the number of layers. Depth pruning, in contrast, removes entire layers or blocks, while keeping the size of the remaining weights unchanged. Most current research focuses on either width-only or a blend of width and depth pruning, with little comparative analysis between the two units (width vs. depth) concerning their impact on LLM inference efficiency. In this work, we show that simple depth pruning can effectively compress LLMs while achieving comparable or superior performance to recent width pruning studies. Our pruning method boosts inference speeds, especially under memory-constrained conditions that require limited batch sizes for running LLMs, where width pruning is ineffective. In retraining pruned models for quality recovery, continued pretraining on a large corpus markedly outperforms LoRA-based tuning, particularly at severe pruning ratios. We hope this work can help build compact yet capable LLMs. Code and models can be found at: https://github.com/Nota-NetsPresso/shortened-llm
6/26/2024