ElasticAST: An Audio Spectrogram Transformer for All Length and Resolutions

0

Sign in to get full access
Overview
- ElasticAST is a novel audio spectrogram transformer that can handle inputs of any length and resolution.
- It addresses limitations of previous audio transformer models that required fixed input sizes or could only handle certain resolutions.
- ElasticAST introduces several key innovations to enable flexible and efficient audio processing.
Plain English Explanation
The paper introduces a new audio processing model called ElasticAST that can work with audio data of any length or resolution. This is an important advancement over previous transformer-based audio models, which were often limited to fixed input sizes or could only handle certain types of audio data.
ElasticAST achieves this flexibility through a few key innovations. First, it uses a variable-length token representation that can dynamically expand or contract to fit the input data. This allows the model to process audio of any duration, without being constrained to a predetermined length.
Additionally, ElasticAST employs a unique multi-scale encoding scheme that can handle audio spectrograms at different resolutions. This means the model can work with high-quality, high-resolution audio data as well as lower-resolution inputs, without requiring separate models or preprocessing steps.
These advancements make ElasticAST a versatile and powerful tool for a wide range of audio processing tasks, from music analysis to speech recognition. By providing a flexible and efficient way to work with audio data of any format, the model has the potential to unlock new applications and drive progress in the field of audio AI.
Technical Explanation
The paper introduces a novel audio spectrogram transformer model called ElasticAST, which addresses the limitations of previous transformer-based approaches that required fixed input sizes or could only handle certain resolutions.
ElasticAST introduces several key innovations to enable flexible and efficient audio processing. First, it uses a variable-length token representation that can dynamically expand or contract to fit the input data, allowing the model to process audio of any duration.
Additionally, ElasticAST employs a multi-scale encoding scheme that can handle audio spectrograms at different resolutions, enabling the model to work with high-quality, high-resolution audio data as well as lower-resolution inputs without requiring separate models or preprocessing steps.
The paper also introduces a novel Streaming Audio Transformer module that allows ElasticAST to process audio in an online, real-time fashion, further enhancing its practical applications.
Through extensive experiments, the authors demonstrate the superior performance of ElasticAST compared to existing audio transformer models, particularly in scenarios involving variable-length or multi-resolution audio data.
Critical Analysis
The paper presents a compelling solution to the limitations of previous audio transformer models, and the innovations introduced in ElasticAST appear to be well-designed and effectively implemented.
However, the authors do acknowledge some potential limitations and areas for further research. For example, they note that the multi-scale encoding scheme may not be as effective for extremely low-resolution audio data, and suggest that additional techniques may be needed to handle such cases.
Additionally, while the streaming audio processing capabilities of ElasticAST are a significant advantage, the paper does not provide a comprehensive evaluation of the model's performance in real-time or online scenarios. Further research may be needed to fully assess the model's effectiveness in these practical deployment settings.
Overall, the research presented in this paper represents an important advancement in the field of audio AI, and the innovations introduced in ElasticAST have the potential to unlock new applications and drive further progress. Researchers and practitioners should carefully consider the strengths and potential limitations of the model when evaluating its suitability for their particular use cases.
Conclusion
The ElasticAST paper introduces a novel audio spectrogram transformer model that can handle inputs of any length and resolution, addressing key limitations of previous transformer-based approaches. Through innovative techniques like variable-length token representation and multi-scale encoding, ElasticAST demonstrates superior performance on a range of audio processing tasks, particularly in scenarios involving variable-length or multi-resolution data.
These advancements have significant implications for the field of audio AI, as they enable more flexible and efficient processing of audio data. By providing a model that can work with a wide variety of audio formats and resolutions, ElasticAST has the potential to unlock new applications and drive further progress in areas such as music analysis, speech recognition, and beyond.
As with any research, there are some potential limitations and areas for further exploration, but the core innovations presented in this paper represent an important step forward in the development of advanced audio processing technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ElasticAST: An Audio Spectrogram Transformer for All Length and Resolutions
Jiu Feng, Mehmet Hamza Erol, Joon Son Chung, Arda Senocak
Transformers have rapidly overtaken CNN-based architectures as the new standard in audio classification. Transformer-based models, such as the Audio Spectrogram Transformers (AST), also inherit the fixed-size input paradigm from CNNs. However, this leads to performance degradation for ASTs in the inference when input lengths vary from the training. This paper introduces an approach that enables the use of variable-length audio inputs with AST models during both training and inference. By employing sequence packing, our method ElasticAST, accommodates any audio length during training, thereby offering flexibility across all lengths and resolutions at the inference. This flexibility allows ElasticAST to maintain evaluation capabilities at various lengths or resolutions and achieve similar performance to standard ASTs trained at specific lengths or resolutions. Moreover, experiments demonstrate ElasticAST's better performance when trained and evaluated on native-length audio datasets.
Read more7/12/2024

0
Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers
Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti, Mirco Ravanelli
Parameter-efficient transfer learning (PETL) methods have emerged as a solid alternative to the standard full fine-tuning approach. They only train a few extra parameters for each downstream task, without sacrificing performance and dispensing with the issue of storing a copy of the pre-trained model for each task. For audio classification tasks, the Audio Spectrogram Transformer (AST) model shows impressive results. However, surprisingly, how to efficiently adapt it to several downstream tasks has not been tackled before. In this paper, we bridge this gap and present a detailed investigation of common PETL methods for the adaptation of the AST model to audio/speech tasks. Furthermore, we propose a new adapter design that exploits the convolution module of the Conformer model, leading to superior performance over the standard PETL approaches and surpassing or achieving performance parity with full fine-tuning by updating only 0.29% of the parameters. Finally, we provide ablation studies revealing that our proposed adapter: 1) proves to be effective in few-shot efficient transfer learning, 2) attains optimal results regardless of the amount of the allocated parameters, and 3) can be applied to other pre-trained models.
Read more7/16/2024
0
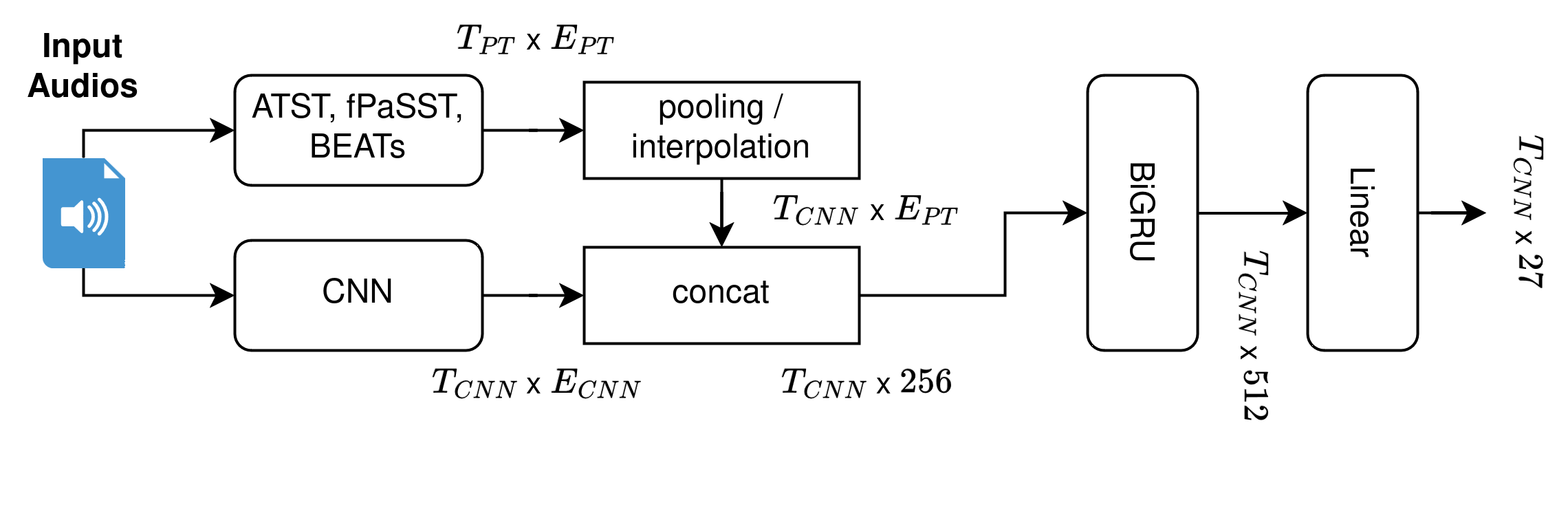
Improving Audio Spectrogram Transformers for Sound Event Detection Through Multi-Stage Training
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, Gerhard Widmer
This technical report describes the CP-JKU team's submission for Task 4 Sound Event Detection with Heterogeneous Training Datasets and Potentially Missing Labels of the DCASE 24 Challenge. We fine-tune three large Audio Spectrogram Transformers, PaSST, BEATs, and ATST, on the joint DESED and MAESTRO datasets in a two-stage training procedure. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the large pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of all three fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, boosting single-model performance substantially. Additionally, we pre-train PaSST and ATST on the subset of AudioSet that comes with strong temporal labels, before fine-tuning them on the Task 4 datasets.
Read more8/6/2024
0
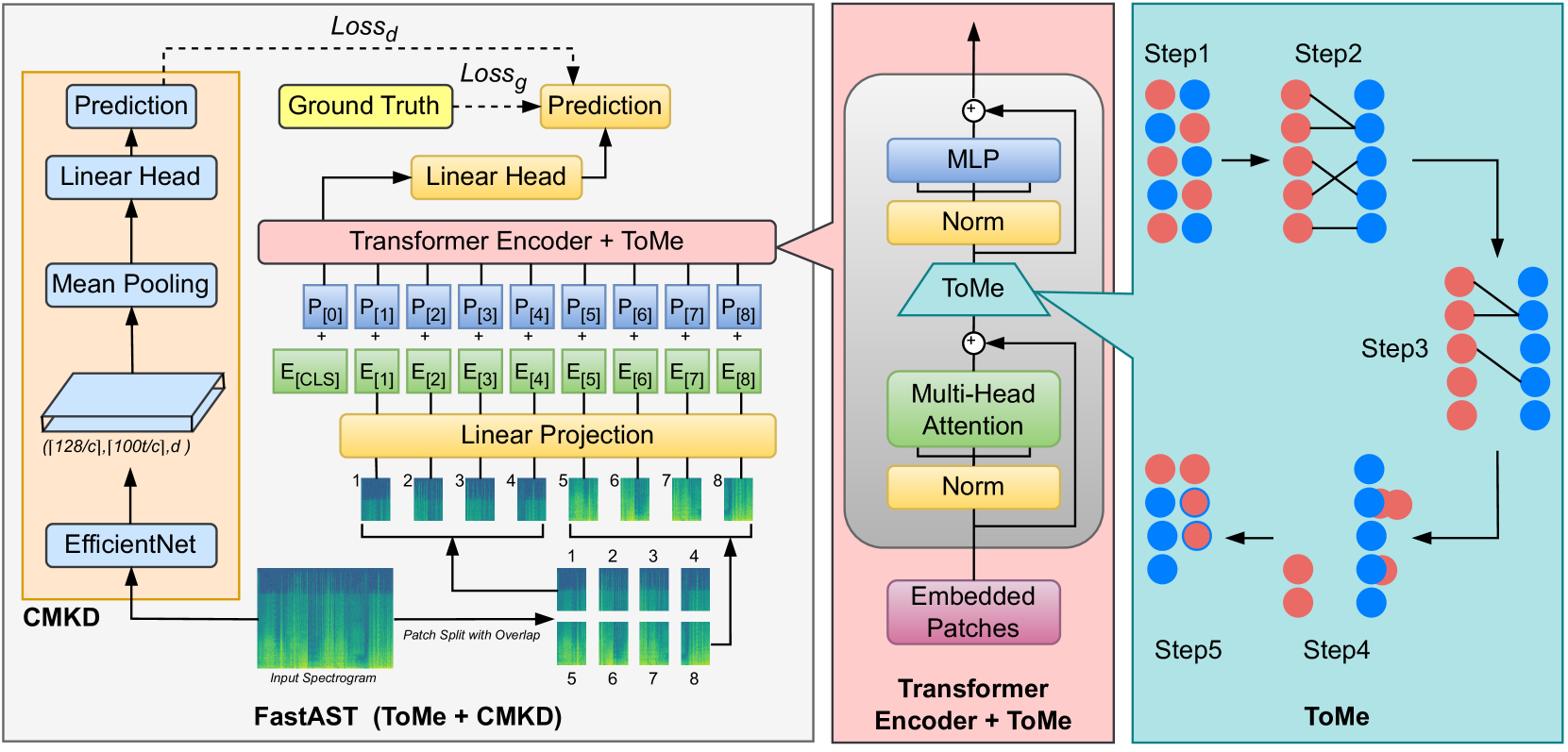
FastAST: Accelerating Audio Spectrogram Transformer via Token Merging and Cross-Model Knowledge Distillation
Swarup Ranjan Behera, Abhishek Dhiman, Karthik Gowda, Aalekhya Satya Narayani
Audio classification models, particularly the Audio Spectrogram Transformer (AST), play a crucial role in efficient audio analysis. However, optimizing their efficiency without compromising accuracy remains a challenge. In this paper, we introduce FastAST, a framework that integrates Token Merging (ToMe) into the AST framework. FastAST enhances inference speed without requiring extensive retraining by merging similar tokens in audio spectrograms. Furthermore, during training, FastAST brings about significant speed improvements. The experiments indicate that FastAST can increase audio classification throughput with minimal impact on accuracy. To mitigate the accuracy impact, we integrate Cross-Model Knowledge Distillation (CMKD) into the FastAST framework. Integrating ToMe and CMKD into AST results in improved accuracy compared to AST while maintaining faster inference speeds. FastAST represents a step towards real-time, resource-efficient audio analysis.
Read more6/13/2024