Streaming Audio Transformers for Online Audio Tagging

0
➖
Sign in to get full access
Overview
- Transformers have shown impressive performance on audio tagging (AT) tasks, but often come with high memory usage, slow inference speed, and model delay.
- This study introduces "streaming audio transformers" (SAT), which combine the vision transformer (ViT) architecture with Transformer-XL-like chunk processing to enable efficient processing of long-range audio signals.
- The proposed SAT model achieves significant improvements in mean average precision (mAP) at low delays, while also exhibiting lower memory usage and computational overhead compared to other transformer-based state-of-the-art methods.
Plain English Explanation
The paper discusses a new type of "transformers" - a popular machine learning model - that is designed to work well with audio data, such as for tasks like audio tagging. Transformers have shown great performance on these audio tasks, but they often have some downsides - they use a lot of computer memory, they can be slow at making predictions, and there is a delay between when the audio is heard and when the model makes its prediction.
To address these issues, the researchers created a new type of transformer called "streaming audio transformers" (SAT). SAT combines ideas from two different types of transformers - the "vision transformer" (ViT) and the "Transformer-XL" model. This allows SAT to efficiently process long audio signals without using too much memory or taking too much time to make predictions.
When tested, the SAT model was able to outperform other state-of-the-art transformer models on an audio tagging benchmark, while also using less memory and being faster. The researchers have made the trained SAT model publicly available for others to use and build upon.
Technical Explanation
The paper introduces "streaming audio transformers" (SAT), a novel transformer-based architecture designed for efficient audio tagging (AT) tasks. SAT combines the vision transformer (ViT) architecture with Transformer-XL-like chunk processing to enable the effective processing of long-range audio signals.
The key innovations of the SAT model include:
- Adapting the ViT architecture to work with 1D audio signals by using "audio patches" instead of image patches.
- Incorporating Transformer-XL-style chunk processing to handle long audio sequences without excessive memory usage or latency.
- Leveraging sub-token embedding techniques to further improve the model's efficiency.
The SAT model is benchmarked against other state-of-the-art transformer-based methods on the Audioset dataset, a widely-used benchmark for audio tagging. The results show that SAT achieves significant improvements in mean average precision (mAP) at low delays (2 seconds and 1 second), while also exhibiting lower memory usage and computational overhead compared to the other models.
Critical Analysis
The paper presents a compelling solution to the challenges faced by transformer models in real-world audio tagging applications. By incorporating the ViT architecture and Transformer-XL-inspired chunk processing, the researchers have been able to address the high memory usage, slow inference speed, and model delay that often plague transformer-based approaches.
One potential limitation of the SAT model is that it may not be as expressive or powerful as the largest transformer models, which can leverage vast amounts of data and compute to achieve state-of-the-art performance. The paper does not provide a direct comparison to these larger models, so it's unclear how SAT's performance might scale as the task complexity or dataset size increases.
Additionally, the paper does not delve into the potential trade-offs or performance implications of the sub-token embedding techniques used in SAT. While these techniques are cited to improve efficiency, their impact on the model's accuracy or generalization capabilities is not thoroughly explored.
Overall, the SAT model represents an innovative and pragmatic approach to making transformer-based audio tagging more practical for real-world deployment. The researchers' efforts to balance performance, memory usage, and latency are commendable and could have far-reaching implications for speech-to-text, text-to-speech, and other audio-based applications.
Conclusion
The streaming audio transformers (SAT) introduced in this paper offer a promising solution to the challenges faced by transformer models in audio tagging tasks. By combining the strengths of the vision transformer and Transformer-XL architectures, the researchers have developed a model that can efficiently process long-range audio signals while maintaining state-of-the-art performance, low latency, and reduced memory and computational requirements.
The public release of the SAT model checkpoints and the clear documentation of the key innovations in the paper make this work highly valuable for researchers and practitioners working in the field of audio understanding and processing. The ideas and techniques presented in this study could inspire further advancements in areas like speech recognition, audio event detection, and other audio-centric applications of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Streaming Audio Transformers for Online Audio Tagging
Heinrich Dinkel, Zhiyong Yan, Yongqing Wang, Junbo Zhang, Yujun Wang, Bin Wang
Transformers have emerged as a prominent model framework for audio tagging (AT), boasting state-of-the-art (SOTA) performance on the widely-used Audioset dataset. However, their impressive performance often comes at the cost of high memory usage, slow inference speed, and considerable model delay, rendering them impractical for real-world AT applications. In this study, we introduce streaming audio transformers (SAT) that combine the vision transformer (ViT) architecture with Transformer-Xl-like chunk processing, enabling efficient processing of long-range audio signals. Our proposed SAT is benchmarked against other transformer-based SOTA methods, achieving significant improvements in terms of mean average precision (mAP) at a delay of 2s and 1s, while also exhibiting significantly lower memory usage and computational overhead. Checkpoints are publicly available https://github.com/RicherMans/SAT.
Read more6/11/2024
🌀
0
ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
Huadai Liu, Rongjie Huang, Xuan Lin, Wenqiang Xu, Maozong Zheng, Hong Chen, Jinzheng He, Zhou Zhao
Text-to-speech(TTS) has undergone remarkable improvements in performance, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs). However, the perceived quality of audio depends not solely on its content, pitch, rhythm, and energy, but also on the physical environment. In this work, we propose ViT-TTS, the first visual TTS model with scalable diffusion transformers. ViT-TTS complement the phoneme sequence with the visual information to generate high-perceived audio, opening up new avenues for practical applications of AR and VR to allow a more immersive and realistic audio experience. To mitigate the data scarcity in learning visual acoustic information, we 1) introduce a self-supervised learning framework to enhance both the visual-text encoder and denoiser decoder; 2) leverage the diffusion transformer scalable in terms of parameters and capacity to learn visual scene information. Experimental results demonstrate that ViT-TTS achieves new state-of-the-art results, outperforming cascaded systems and other baselines regardless of the visibility of the scene. With low-resource data (1h, 2h, 5h), ViT-TTS achieves comparative results with rich-resource baselines.~footnote{Audio samples are available at url{https://ViT-TTS.github.io/.}}
Read more4/23/2024

0
New!EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
Jiarui Hai, Yong Xu, Hao Zhang, Chenxing Li, Helin Wang, Mounya Elhilali, Dong Yu
Latent diffusion models have shown promising results in text-to-audio (T2A) generation tasks, yet previous models have encountered difficulties in generation quality, computational cost, diffusion sampling, and data preparation. In this paper, we introduce EzAudio, a transformer-based T2A diffusion model, to handle these challenges. Our approach includes several key innovations: (1) We build the T2A model on the latent space of a 1D waveform Variational Autoencoder (VAE), avoiding the complexities of handling 2D spectrogram representations and using an additional neural vocoder. (2) We design an optimized diffusion transformer architecture specifically tailored for audio latent representations and diffusion modeling, which enhances convergence speed, training stability, and memory usage, making the training process easier and more efficient. (3) To tackle data scarcity, we adopt a data-efficient training strategy that leverages unlabeled data for learning acoustic dependencies, audio caption data annotated by audio-language models for text-to-audio alignment learning, and human-labeled data for fine-tuning. (4) We introduce a classifier-free guidance (CFG) rescaling method that simplifies EzAudio by achieving strong prompt alignment while preserving great audio quality when using larger CFG scores, eliminating the need to struggle with finding the optimal CFG score to balance this trade-off. EzAudio surpasses existing open-source models in both objective metrics and subjective evaluations, delivering realistic listening experiences while maintaining a streamlined model structure, low training costs, and an easy-to-follow training pipeline. Code, data, and pre-trained models are released at: https://haidog-yaqub.github.io/EzAudio-Page/.
Read more9/18/2024
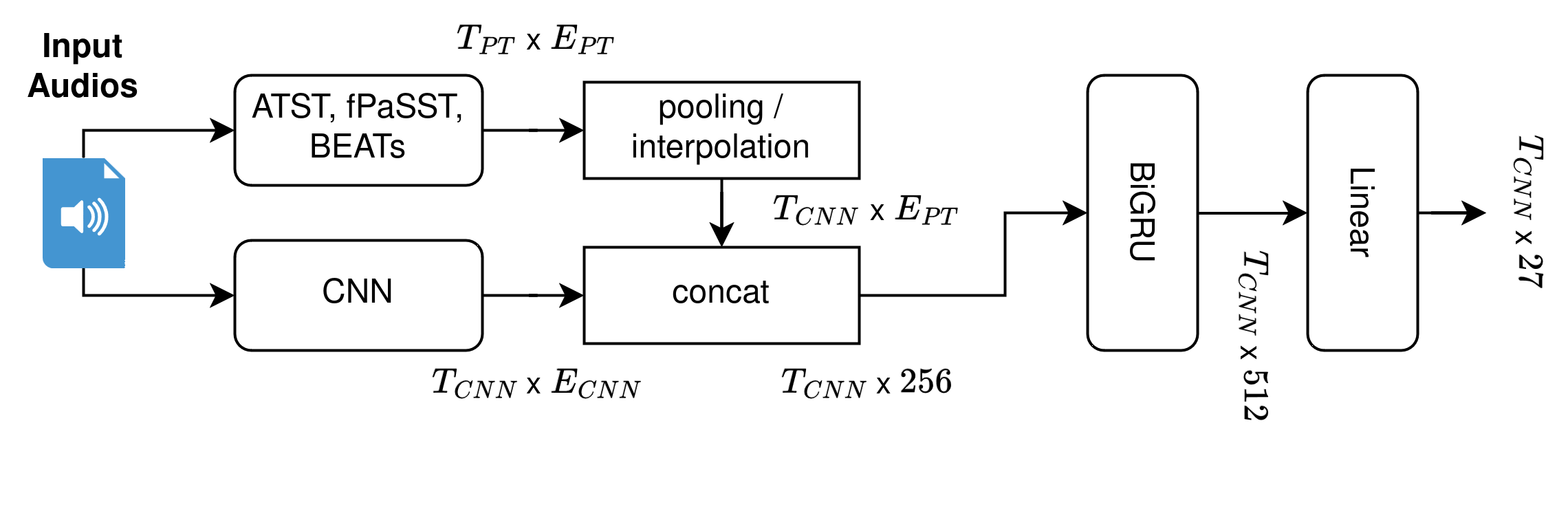
0
Improving Audio Spectrogram Transformers for Sound Event Detection Through Multi-Stage Training
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, Gerhard Widmer
This technical report describes the CP-JKU team's submission for Task 4 Sound Event Detection with Heterogeneous Training Datasets and Potentially Missing Labels of the DCASE 24 Challenge. We fine-tune three large Audio Spectrogram Transformers, PaSST, BEATs, and ATST, on the joint DESED and MAESTRO datasets in a two-stage training procedure. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the large pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of all three fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, boosting single-model performance substantially. Additionally, we pre-train PaSST and ATST on the subset of AudioSet that comes with strong temporal labels, before fine-tuning them on the Task 4 datasets.
Read more8/6/2024