Eliminating Biased Length Reliance of Direct Preference Optimization via Down-Sampled KL Divergence
2406.10957
0
0

Abstract
Direct Preference Optimization (DPO) has emerged as a prominent algorithm for the direct and robust alignment of Large Language Models (LLMs) with human preferences, offering a more straightforward alternative to the complex Reinforcement Learning from Human Feedback (RLHF). Despite its promising efficacy, DPO faces a notable drawback: verbosity, a common over-optimization phenomenon also observed in RLHF. While previous studies mainly attributed verbosity to biased labels within the data, we propose that the issue also stems from an inherent algorithmic length reliance in DPO. Specifically, we suggest that the discrepancy between sequence-level Kullback-Leibler (KL) divergences between chosen and rejected sequences, used in DPO, results in overestimated or underestimated rewards due to varying token lengths. Empirically, we utilize datasets with different label lengths to demonstrate the presence of biased rewards. We then introduce an effective downsampling approach, named SamPO, to eliminate potential length reliance. Our experimental evaluations, conducted across three LLMs of varying scales and a diverse array of conditional and open-ended benchmarks, highlight the efficacy of SamPO in mitigating verbosity, achieving improvements of 5% to 12% over DPO through debaised rewards. Our codes can be accessed at: https://github.com/LuJunru/SamPO/.
Create account to get full access
Overview
- This paper addresses a limitation of direct preference optimization (DPO) methods, where the length of the generated text can be biased towards shorter or longer outputs.
- The authors propose a novel approach called "Down-Sampled KL Divergence" (DSKL) to eliminate this biased length reliance in DPO.
- The DSKL method involves subsampling the target text during training to create a distribution of diverse lengths, which helps the model generate more natural-sounding text.
Plain English Explanation
A key challenge in language models is ensuring the generated text has a natural, human-like length. Direct preference optimization (DPO) is a technique that allows language models to optimize for specific qualities, like longer or shorter text. However, this can lead to the model becoming overly biased towards generating text of a particular length, which may not be ideal.
The authors of this paper have developed a new approach called "Down-Sampled KL Divergence" (DSKL) to address this issue. The basic idea is to expose the model to a wider range of text lengths during training, rather than just optimizing for a single target length. This is done by [https://aimodels.fyi/papers/arxiv/iterative-length-regularized-direct-preference-optimization-case]"down-sampling" the target text, meaning that the model sees a variety of text lengths, not just the original target.
By training the model this way, it learns to generate text that is more natural-sounding and not overly biased towards a specific length. This can be particularly useful for applications like [https://aimodels.fyi/papers/arxiv/token-level-direct-preference-optimization]content generation, where you want the output to have a human-like flow and pacing.
The authors demonstrate the effectiveness of their DSKL approach through experiments, showing that it outperforms other DPO methods in terms of reducing length bias while maintaining the desired text qualities. This research contributes to the ongoing efforts to [https://aimodels.fyi/papers/arxiv/mallows-dpo-fine-tune-your-llm-preference]fine-tune large language models to better match user preferences and [https://aimodels.fyi/papers/arxiv/bootstrapping-language-models-dpo-implicit-rewards]generate more coherent and natural-sounding text.
Technical Explanation
The paper proposes a novel approach called "Down-Sampled KL Divergence" (DSKL) to address the biased length reliance issue in direct preference optimization (DPO) methods. DPO techniques allow language models to be optimized for specific qualities, like producing longer or shorter text. However, this can lead to the model becoming overly biased towards generating text of a particular length, which may not be desirable.
The DSKL method works by subsampling the target text during training to create a distribution of diverse lengths. This is achieved by [https://aimodels.fyi/papers/arxiv/iterative-length-regularized-direct-preference-optimization-case]downsampling the target text, where a random subset of the original target is used as the reference distribution. This encourages the model to learn a more balanced distribution of text lengths, rather than optimizing for a single target length.
The authors evaluate the DSKL approach on several [https://aimodels.fyi/papers/arxiv/token-level-direct-preference-optimization]DPO tasks, including text generation and [https://aimodels.fyi/papers/arxiv/mallows-dpo-fine-tune-your-llm-preference]preference fine-tuning. The results show that DSKL effectively reduces the length bias in the generated text while maintaining the desired text qualities.
This research contributes to the broader efforts in the field to [https://aimodels.fyi/papers/arxiv/bootstrapping-language-models-dpo-implicit-rewards]fine-tune large language models and generate more coherent, natural-sounding text that better aligns with user preferences. The [https://aimodels.fyi/papers/arxiv/filtered-direct-preference-optimization]DSKL method provides a promising approach to address the length bias issue in DPO, which is an important consideration for many practical applications of language models.
Critical Analysis
The authors have identified a valid limitation of direct preference optimization (DPO) methods, where the generated text can become biased towards a specific length. The proposed Down-Sampled KL Divergence (DSKL) approach is a novel and promising solution to this problem.
One potential concern is the impact of the downsampling process on the overall quality and coherence of the generated text. While the authors show that DSKL reduces length bias, it's unclear if this comes at the cost of other important text qualities. Further research may be needed to fully understand the trade-offs and ensure the DSKL method maintains high-quality text generation.
Additionally, the paper focuses on evaluating DSKL in the context of specific DPO tasks, such as text generation and preference fine-tuning. It would be interesting to see how the method performs in a wider range of applications and whether the benefits are consistent across different use cases.
Another area for further exploration is the potential to combine the DSKL approach with other techniques, such as [https://aimodels.fyi/papers/arxiv/iterative-length-regularized-direct-preference-optimization-case]length-regularized DPO or [https://aimodels.fyi/papers/arxiv/token-level-direct-preference-optimization]token-level DPO. Integrating DSKL with these or other complementary methods could potentially lead to even more robust and versatile language models.
Overall, the DSKL method presented in this paper is a valuable contribution to the field of language model optimization. The authors have identified an important problem and proposed a novel solution that shows promising results. Continued research and refinement of this approach could further enhance the capabilities of language models and their ability to generate text that is both engaging and natural-sounding.
Conclusion
This paper introduces a novel approach called "Down-Sampled KL Divergence" (DSKL) to address the biased length reliance issue in direct preference optimization (DPO) methods for language models. By exposing the model to a diverse distribution of text lengths during training, DSKL helps eliminate the tendency for the generated text to be overly biased towards a specific length.
The authors demonstrate the effectiveness of DSKL through experiments on various DPO tasks, showing that it outperforms other methods in reducing length bias while maintaining the desired text qualities. This research contributes to the ongoing efforts to fine-tune large language models and generate more coherent, natural-sounding text that better aligns with user preferences.
The DSKL approach provides a promising solution to an important challenge in language model optimization. As language models continue to play a crucial role in a wide range of applications, addressing biases and ensuring the generation of high-quality, human-like text will become increasingly important. The insights and techniques presented in this paper can help pave the way for more robust and versatile language models that can better serve the needs of users and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
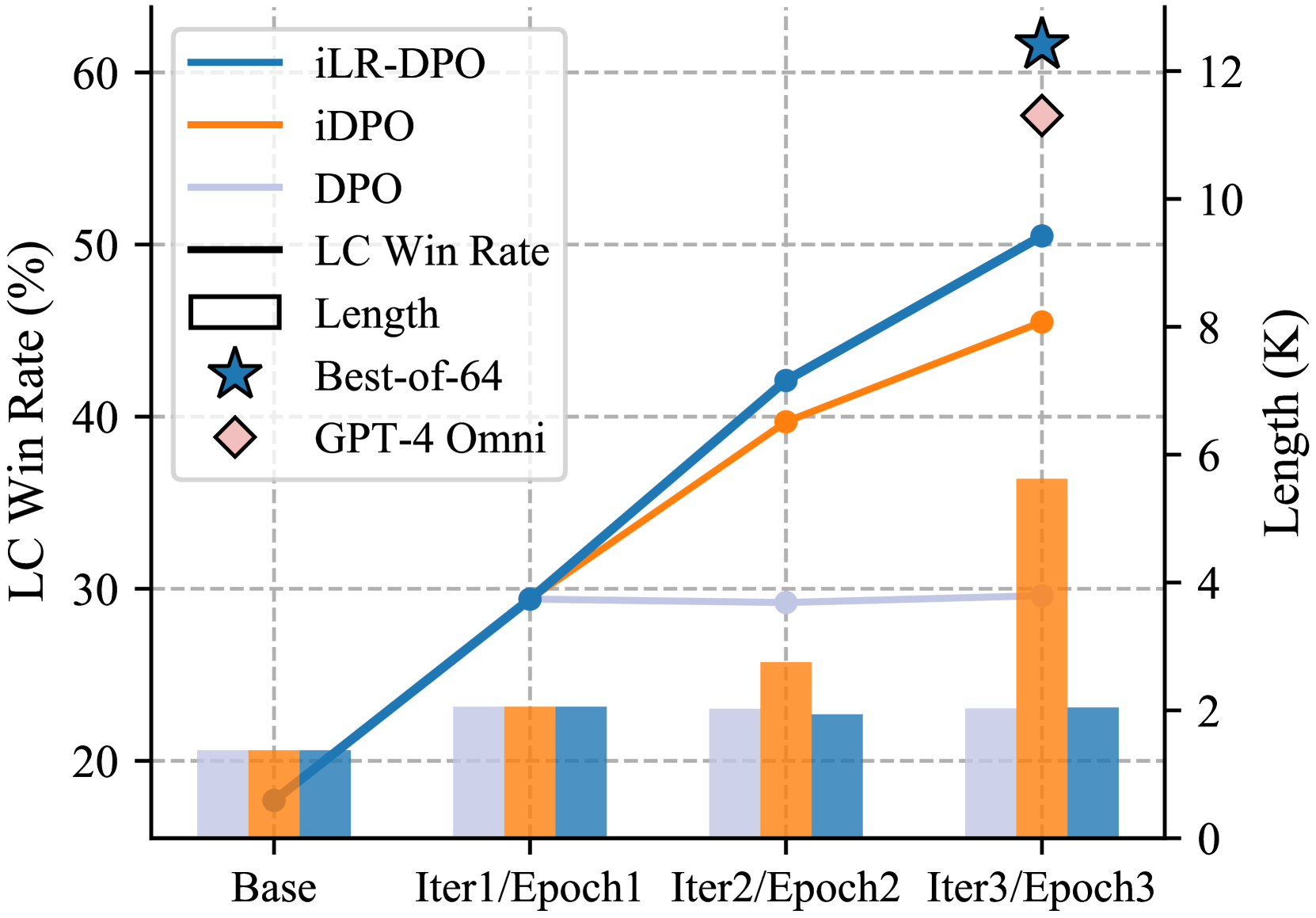
Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level
Jie Liu, Zhanhui Zhou, Jiaheng Liu, Xingyuan Bu, Chao Yang, Han-Sen Zhong, Wanli Ouyang
0
0
Direct Preference Optimization (DPO), a standard method for aligning language models with human preferences, is traditionally applied to offline preferences. Recent studies show that DPO benefits from iterative training with online preferences labeled by a trained reward model. In this work, we identify a pitfall of vanilla iterative DPO - improved response quality can lead to increased verbosity. To address this, we introduce iterative length-regularized DPO (iLR-DPO) to penalize response length. Our empirical results show that iLR-DPO can enhance a 7B model to perform on par with GPT-4 without increasing verbosity. Specifically, our 7B model achieves a $50.5%$ length-controlled win rate against $texttt{GPT-4 Preview}$ on AlpacaEval 2.0, and excels across standard benchmarks including MT-Bench, Arena-Hard and OpenLLM Leaderboard. These results demonstrate the effectiveness of iterative DPO in aligning language models with human feedback.
6/18/2024
Token-level Direct Preference Optimization
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, Jun Wang
0
0
Fine-tuning pre-trained Large Language Models (LLMs) is essential to align them with human values and intentions. This process often utilizes methods like pairwise comparisons and KL divergence against a reference LLM, focusing on the evaluation of full answers generated by the models. However, the generation of these responses occurs in a token level, following a sequential, auto-regressive fashion. In this paper, we introduce Token-level Direct Preference Optimization (TDPO), a novel approach to align LLMs with human preferences by optimizing policy at the token level. Unlike previous methods, which face challenges in divergence efficiency, TDPO incorporates forward KL divergence constraints for each token, improving alignment and diversity. Utilizing the Bradley-Terry model for a token-based reward system, TDPO enhances the regulation of KL divergence, while preserving simplicity without the need for explicit reward modeling. Experimental results across various text tasks demonstrate TDPO's superior performance in balancing alignment with generation diversity. Notably, fine-tuning with TDPO strikes a better balance than DPO in the controlled sentiment generation and single-turn dialogue datasets, and significantly improves the quality of generated responses compared to both DPO and PPO-based RLHF methods. Our code is open-sourced at https://github.com/Vance0124/Token-level-Direct-Preference-Optimization.
6/28/2024
Mallows-DPO: Fine-Tune Your LLM with Preference Dispersions
Haoxian Chen, Hanyang Zhao, Henry Lam, David Yao, Wenpin Tang
0
0
Direct Preference Optimization (DPO) has recently emerged as a popular approach to improve reinforcement learning with human feedback (RLHF), leading to better techniques to fine-tune large language models (LLM). A weakness of DPO, however, lies in its lack of capability to characterize the diversity of human preferences. Inspired by Mallows' theory of preference ranking, we develop in this paper a new approach, the Mallows-DPO. A distinct feature of this approach is a dispersion index, which reflects the dispersion of human preference to prompts. We show that existing DPO models can be reduced to special cases of this dispersion index, thus unified with Mallows-DPO. More importantly, we demonstrate (empirically) how to use this dispersion index to enhance the performance of DPO in a broad array of benchmark tasks, from synthetic bandit selection to controllable generations and dialogues, while maintaining great generalization capabilities.
5/27/2024

Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, Jiaya Jia
0
0
Mathematical reasoning presents a significant challenge for Large Language Models (LLMs) due to the extensive and precise chain of reasoning required for accuracy. Ensuring the correctness of each reasoning step is critical. To address this, we aim to enhance the robustness and factuality of LLMs by learning from human feedback. However, Direct Preference Optimization (DPO) has shown limited benefits for long-chain mathematical reasoning, as models employing DPO struggle to identify detailed errors in incorrect answers. This limitation stems from a lack of fine-grained process supervision. We propose a simple, effective, and data-efficient method called Step-DPO, which treats individual reasoning steps as units for preference optimization rather than evaluating answers holistically. Additionally, we have developed a data construction pipeline for Step-DPO, enabling the creation of a high-quality dataset containing 10K step-wise preference pairs. We also observe that in DPO, self-generated data is more effective than data generated by humans or GPT-4, due to the latter's out-of-distribution nature. Our findings demonstrate that as few as 10K preference data pairs and fewer than 500 Step-DPO training steps can yield a nearly 3% gain in accuracy on MATH for models with over 70B parameters. Notably, Step-DPO, when applied to Qwen2-72B-Instruct, achieves scores of 70.8% and 94.0% on the test sets of MATH and GSM8K, respectively, surpassing a series of closed-source models, including GPT-4-1106, Claude-3-Opus, and Gemini-1.5-Pro. Our code, data, and models are available at https://github.com/dvlab-research/Step-DPO.
6/28/2024