Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
2406.18629
0
0

Abstract
Mathematical reasoning presents a significant challenge for Large Language Models (LLMs) due to the extensive and precise chain of reasoning required for accuracy. Ensuring the correctness of each reasoning step is critical. To address this, we aim to enhance the robustness and factuality of LLMs by learning from human feedback. However, Direct Preference Optimization (DPO) has shown limited benefits for long-chain mathematical reasoning, as models employing DPO struggle to identify detailed errors in incorrect answers. This limitation stems from a lack of fine-grained process supervision. We propose a simple, effective, and data-efficient method called Step-DPO, which treats individual reasoning steps as units for preference optimization rather than evaluating answers holistically. Additionally, we have developed a data construction pipeline for Step-DPO, enabling the creation of a high-quality dataset containing 10K step-wise preference pairs. We also observe that in DPO, self-generated data is more effective than data generated by humans or GPT-4, due to the latter's out-of-distribution nature. Our findings demonstrate that as few as 10K preference data pairs and fewer than 500 Step-DPO training steps can yield a nearly 3% gain in accuracy on MATH for models with over 70B parameters. Notably, Step-DPO, when applied to Qwen2-72B-Instruct, achieves scores of 70.8% and 94.0% on the test sets of MATH and GSM8K, respectively, surpassing a series of closed-source models, including GPT-4-1106, Claude-3-Opus, and Gemini-1.5-Pro. Our code, data, and models are available at https://github.com/dvlab-research/Step-DPO.
Create account to get full access
Overview
- Presents a novel method called Step-DPO for optimizing the preferences of large language models (LLMs) for long-chain reasoning tasks
- Builds on previous work on direct preference optimization (DPO) and step-level value preference optimization
- Aims to improve the alignment and denoising of LLM preferences during long-chain reasoning
Plain English Explanation
Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs introduces a new technique called "Step-DPO" to help improve the performance of large language models (LLMs) on complex, multi-step reasoning tasks.
The key idea is to break down these long reasoning chains into smaller, more manageable "steps" and then optimize the model's preferences for each of these individual steps. This step-wise approach allows the model to better align its preferences and denoise any irrelevant information during the reasoning process, ultimately leading to more coherent and reliable results.
The authors build on previous work on direct preference optimization (DPO) and step-level value preference optimization, combining these techniques to create the Step-DPO method. They also draw inspiration from other "step-aware" preference optimization approaches, such as Step-AVPO and Triple-PO, to further enhance the model's ability to reason effectively.
By breaking down complex reasoning tasks into smaller, more manageable steps and optimizing the model's preferences for each of these steps, Step-DPO aims to help LLMs overcome the challenges of long-chain reasoning and produce more coherent and reliable outputs.
Technical Explanation
Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs introduces a novel method called "Step-DPO" to improve the performance of large language models (LLMs) on complex, multi-step reasoning tasks.
The authors build on previous work on direct preference optimization (DPO), which aims to directly optimize the preferences of LLMs, and step-level value preference optimization, which focuses on optimizing the preferences for individual steps in a reasoning chain.
The key innovation of Step-DPO is to combine these two approaches, breaking down complex reasoning tasks into smaller, more manageable "steps" and then optimizing the model's preferences for each of these steps. This step-wise approach allows the model to better align its preferences and denoise any irrelevant information during the reasoning process, ultimately leading to more coherent and reliable results.
The authors also draw inspiration from other "step-aware" preference optimization techniques, such as Step-AVPO and Triple-PO, to further enhance the model's ability to reason effectively.
Through extensive experiments, the researchers demonstrate that Step-DPO outperforms traditional DPO and other step-aware preference optimization methods on a range of long-chain reasoning tasks, highlighting the benefits of this step-wise approach to preference optimization.
Critical Analysis
The paper presents a well-designed and comprehensive study on the Step-DPO method, providing a robust evaluation of its performance on various long-chain reasoning tasks. However, the authors acknowledge a few potential limitations and areas for further research.
One key limitation is the reliance on the quality and availability of task-specific datasets for training and evaluating the Step-DPO model. The authors note that the performance of the method may be sensitive to the characteristics of the dataset, and further research is needed to understand how it scales to more diverse and challenging reasoning tasks.
Additionally, the authors do not delve into the interpretability of the Step-DPO model, which is an important consideration for real-world applications. Understanding the internal reasoning process and the factors that influence the model's decisions could help improve transparency and trust in the system.
Further research could also explore ways to integrate Step-DPO with other advanced techniques, such as Mallows-DPO, to enhance the overall performance and robustness of the preference optimization approach.
Conclusion
Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs presents a novel technique for optimizing the preferences of large language models (LLMs) to improve their performance on complex, multi-step reasoning tasks. By breaking down these reasoning chains into smaller, more manageable steps and optimizing the model's preferences for each step, Step-DPO aims to enhance the alignment and denoising of the model's preferences, leading to more coherent and reliable outputs.
The authors have demonstrated the effectiveness of Step-DPO through extensive experiments, showing that it outperforms traditional DPO and other step-aware preference optimization methods. While the paper highlights some potential limitations and areas for further research, the Step-DPO approach represents a significant advancement in the field of preference optimization for long-chain reasoning, with promising implications for the development of more robust and reliable LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Step-level Value Preference Optimization for Mathematical Reasoning
Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan
0
0
Direct Preference Optimization (DPO) using an implicit reward model has proven to be an effective alternative to reinforcement learning from human feedback (RLHF) for fine-tuning preference aligned large language models (LLMs). However, the overall preference annotations of responses do not fully capture the fine-grained quality of model outputs in complex multi-step reasoning tasks, such as mathematical reasoning. To address this limitation, we introduce a novel algorithm called Step-level Value Preference Optimization (SVPO). Our approach employs Monte Carlo Tree Search (MCTS) to automatically annotate step-level preferences for multi-step reasoning. Furthermore, from the perspective of learning-to-rank, we train an explicit value model to replicate the behavior of the implicit reward model, complementing standard preference optimization. This value model enables the LLM to generate higher reward responses with minimal cost during inference. Experimental results demonstrate that our method achieves state-of-the-art performance on both in-domain and out-of-domain mathematical reasoning benchmarks.
6/18/2024
Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level
Jie Liu, Zhanhui Zhou, Jiaheng Liu, Xingyuan Bu, Chao Yang, Han-Sen Zhong, Wanli Ouyang
0
0
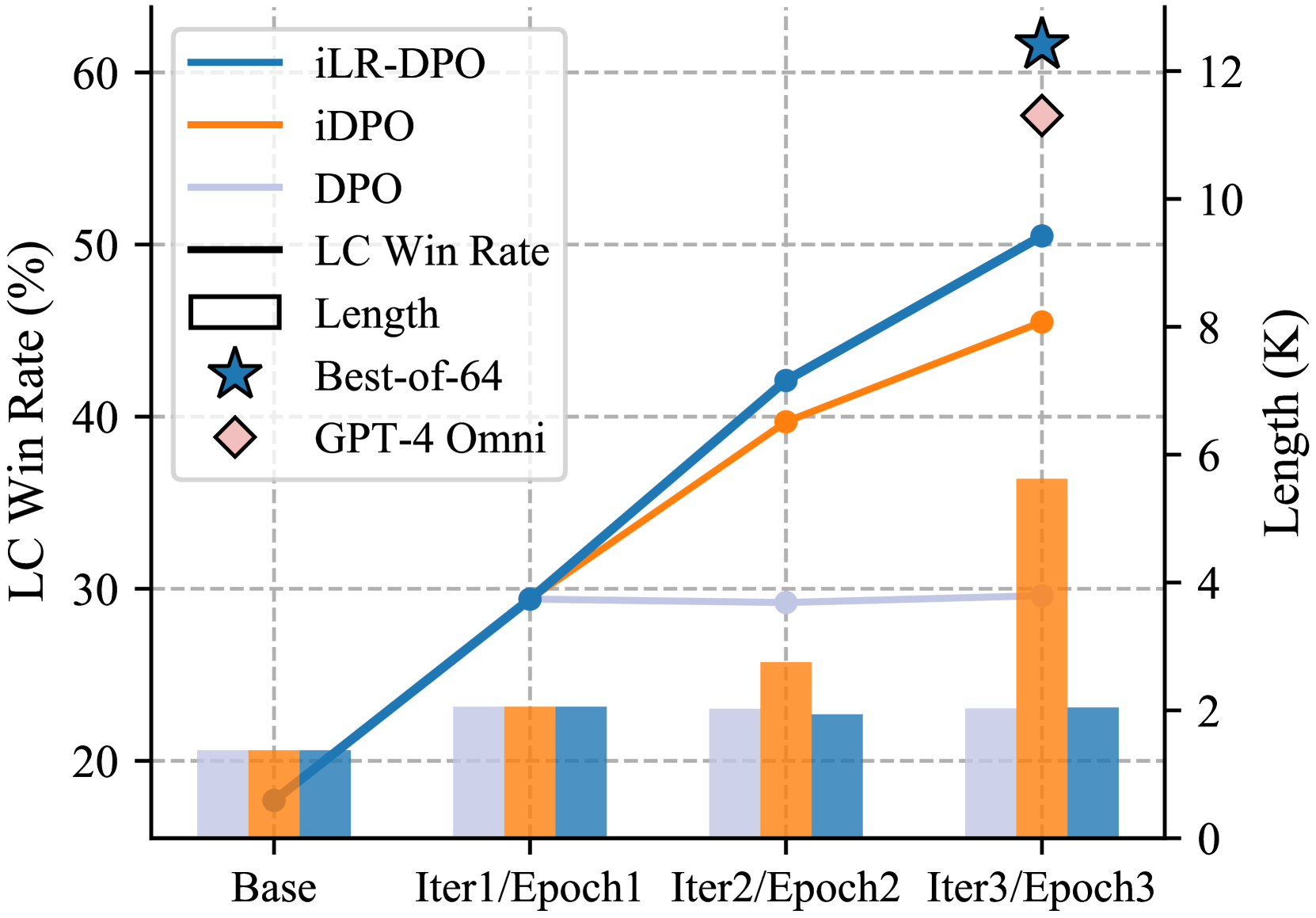
Direct Preference Optimization (DPO), a standard method for aligning language models with human preferences, is traditionally applied to offline preferences. Recent studies show that DPO benefits from iterative training with online preferences labeled by a trained reward model. In this work, we identify a pitfall of vanilla iterative DPO - improved response quality can lead to increased verbosity. To address this, we introduce iterative length-regularized DPO (iLR-DPO) to penalize response length. Our empirical results show that iLR-DPO can enhance a 7B model to perform on par with GPT-4 without increasing verbosity. Specifically, our 7B model achieves a $50.5%$ length-controlled win rate against $texttt{GPT-4 Preview}$ on AlpacaEval 2.0, and excels across standard benchmarks including MT-Bench, Arena-Hard and OpenLLM Leaderboard. These results demonstrate the effectiveness of iterative DPO in aligning language models with human feedback.
6/18/2024

Step-aware Preference Optimization: Aligning Preference with Denoising Performance at Each Step
Zhanhao Liang, Yuhui Yuan, Shuyang Gu, Bohan Chen, Tiankai Hang, Ji Li, Liang Zheng
0
0
Recently, Direct Preference Optimization (DPO) has extended its success from aligning large language models (LLMs) to aligning text-to-image diffusion models with human preferences. Unlike most existing DPO methods that assume all diffusion steps share a consistent preference order with the final generated images, we argue that this assumption neglects step-specific denoising performance and that preference labels should be tailored to each step's contribution. To address this limitation, we propose Step-aware Preference Optimization (SPO), a novel post-training approach that independently evaluates and adjusts the denoising performance at each step, using a step-aware preference model and a step-wise resampler to ensure accurate step-aware supervision. Specifically, at each denoising step, we sample a pool of images, find a suitable win-lose pair, and, most importantly, randomly select a single image from the pool to initialize the next denoising step. This step-wise resampler process ensures the next win-lose image pair comes from the same image, making the win-lose comparison independent of the previous step. To assess the preferences at each step, we train a separate step-aware preference model that can be applied to both noisy and clean images. Our experiments with Stable Diffusion v1.5 and SDXL demonstrate that SPO significantly outperforms the latest Diffusion-DPO in aligning generated images with complex, detailed prompts and enhancing aesthetics, while also achieving more than 20x times faster in training efficiency. Code and model: https://rockeycoss.github.io/spo.github.io/
6/7/2024
Triple Preference Optimization: Achieving Better Alignment with Less Data in a Single Step Optimization
Amir Saeidi, Shivanshu Verma, Aswin RRV, Chitta Baral
0
0
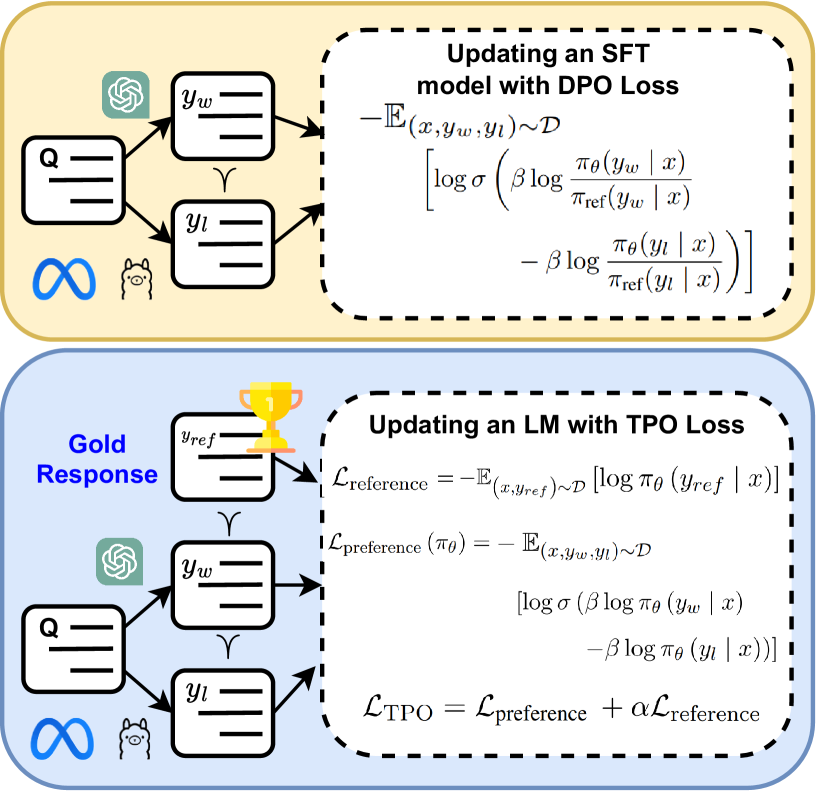
Large Language Models (LLMs) perform well across diverse tasks, but aligning them with human demonstrations is challenging. Recently, Reinforcement Learning (RL)-free methods like Direct Preference Optimization (DPO) have emerged, offering improved stability and scalability while retaining competitive performance relative to RL-based methods. However, while RL-free methods deliver satisfactory performance, they require significant data to develop a robust Supervised Fine-Tuned (SFT) model and an additional step to fine-tune this model on a preference dataset, which constrains their utility and scalability. In this paper, we introduce Triple Preference Optimization (TPO), a new preference learning method designed to align an LLM with three preferences without requiring a separate SFT step and using considerably less data. Through a combination of practical experiments and theoretical analysis, we show the efficacy of TPO as a single-step alignment strategy. Specifically, we fine-tuned the Phi-2 (2.7B) and Mistral (7B) models using TPO directly on the UltraFeedback dataset, achieving superior results compared to models aligned through other methods such as SFT, DPO, KTO, IPO, CPO, and ORPO. Moreover, the performance of TPO without the SFT component led to notable improvements in the MT-Bench score, with increases of +1.27 and +0.63 over SFT and DPO, respectively. Additionally, TPO showed higher average accuracy, surpassing DPO and SFT by 4.2% and 4.97% on the Open LLM Leaderboard benchmarks. Our code is publicly available at https://github.com/sahsaeedi/triple-preference-optimization .
5/28/2024