An Embodied Generalist Agent in 3D World
2311.12871
0
0
⛏️
Abstract
Leveraging massive knowledge from large language models (LLMs), recent machine learning models show notable successes in general-purpose task solving in diverse domains such as computer vision and robotics. However, several significant challenges remain: (i) most of these models rely on 2D images yet exhibit a limited capacity for 3D input; (ii) these models rarely explore the tasks inherently defined in 3D world, e.g., 3D grounding, embodied reasoning and acting. We argue these limitations significantly hinder current models from performing real-world tasks and approaching general intelligence. To this end, we introduce LEO, an embodied multi-modal generalist agent that excels in perceiving, grounding, reasoning, planning, and acting in the 3D world. LEO is trained with a unified task interface, model architecture, and objective in two stages: (i) 3D vision-language (VL) alignment and (ii) 3D vision-language-action (VLA) instruction tuning. We collect large-scale datasets comprising diverse object-level and scene-level tasks, which require considerable understanding of and interaction with the 3D world. Moreover, we meticulously design an LLM-assisted pipeline to produce high-quality 3D VL data. Through extensive experiments, we demonstrate LEO's remarkable proficiency across a wide spectrum of tasks, including 3D captioning, question answering, embodied reasoning, navigation and manipulation. Our ablative studies and scaling analyses further provide valuable insights for developing future embodied generalist agents. Code and data are available on project page.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Recent machine learning models have shown notable success in building generalist agents that can perform a wide range of tasks, including natural language processing, computer vision, and robotics.
- However, these models still struggle with understanding and interacting with the 3D world, which significantly limits their ability to perform real-world tasks and achieve general intelligence.
- The researchers introduce an embodied multi-modal and multi-task generalist agent called LEO, which is trained to excel in perceiving, grounding, reasoning, planning, and acting in the 3D world.
Plain English Explanation
The researchers have developed a new type of artificial intelligence (AI) agent that can perform a wide variety of tasks, such as understanding natural language, analyzing images, and controlling robots. This agent, called LEO, is trained using a large language model (LLM) - a powerful AI system that has learned a lot of information from the internet.
Unlike previous AI agents, LEO is designed to work in the 3D world, not just on a computer screen. It can see and interact with 3D objects and environments, which allows it to do more realistic and practical tasks. For example, LEO could be used to control a robot arm to pick up and move objects, or to navigate through a 3D virtual environment.
To train LEO, the researchers created a huge dataset of 3D objects, scenes, and tasks that the agent needs to learn. This dataset includes things like 3D images, text descriptions, and instructions for how to perform various actions. By training on this diverse dataset, LEO learns to understand and interact with the 3D world in a way that previous AI agents could not.
The researchers' experiments show that LEO is remarkably good at a wide range of 3D-related tasks, such as describing 3D scenes, answering questions about 3D environments, navigating through 3D spaces, and controlling robotic manipulators. This suggests that LEO is a significant step towards achieving general intelligence - the ability to perform any task that a human can, without being specifically trained for it.
Technical Explanation
The researchers introduce a novel embodied multi-modal and multi-task generalist agent called LEO, which is trained in two stages:
- 3D Vision-Language Alignment: LEO is trained to align its understanding of 3D visual information with natural language descriptions of that information.
- 3D Vision-Language-Action Instruction Tuning: LEO is then further trained on a large dataset of 3D tasks, where it must learn to perceive, reason about, and take actions in the 3D world based on natural language instructions.
The researchers curate an extensive dataset of object-level and scene-level multi-modal tasks with high levels of scale and complexity to facilitate LEO's training. This dataset requires LEO to develop a deep understanding of and the ability to interact with the 3D world.
Through rigorous experiments, the researchers demonstrate that LEO exhibits remarkable proficiency across a wide range of 3D-related tasks, including 3D captioning, question answering, embodied reasoning, embodied navigation, and robotic manipulation. The researchers also provide valuable insights into the development of future embodied generalist agents through their ablation studies.
Critical Analysis
The researchers have made a significant contribution to the field of embodied AI by developing LEO, a generalist agent that can excel at a wide range of 3D-related tasks. However, the paper also highlights some potential limitations and areas for further research:
- While LEO demonstrates impressive capabilities, the researchers acknowledge that there is still room for improvement, particularly in terms of the agent's ability to understand and reason about the 3D world at a deeper level.
- The dataset used to train LEO, while extensive, may not be comprehensive enough to cover all the potential real-world tasks and environments that the agent would need to handle.
- The researchers note that the training process for LEO is computationally intensive and may not be scalable to even larger and more complex datasets.
Further research could explore ways to enhance the efficiency and scalability of the training process, as well as ways to improve the agent's understanding and reasoning capabilities in the 3D world. Additionally, it would be interesting to see how LEO's performance compares to other state-of-the-art embodied AI agents and to explore the potential real-world applications of this technology.
Conclusion
The researchers have developed a remarkable embodied multi-modal and multi-task generalist agent called LEO, which demonstrates a significant advancement in the field of embodied AI. LEO's ability to perceive, reason about, and act in the 3D world opens up new possibilities for the development of intelligent systems that can perform a wide range of practical, real-world tasks.
While the researchers have made an important contribution, there is still room for further improvement and research in this area. By continuing to push the boundaries of embodied AI, researchers can work towards the ultimate goal of achieving general intelligence – the ability of artificial systems to match and even exceed human-level performance across a diverse range of tasks and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Do We Really Need a Complex Agent System? Distill Embodied Agent into a Single Model
Zhonghan Zhao, Ke Ma, Wenhao Chai, Xuan Wang, Kewei Chen, Dongxu Guo, Yanting Zhang, Hongwei Wang, Gaoang Wang
0
0
With the power of large language models (LLMs), open-ended embodied agents can flexibly understand human instructions, generate interpretable guidance strategies, and output executable actions. Nowadays, Multi-modal Language Models~(MLMs) integrate multi-modal signals into LLMs, further bringing richer perception to entity agents and allowing embodied agents to perceive world-understanding tasks more delicately. However, existing works: 1) operate independently by agents, each containing multiple LLMs, from perception to action, resulting in gaps between complex tasks and execution; 2) train MLMs on static data, struggling with dynamics in open-ended scenarios; 3) input prior knowledge directly as prompts, suppressing application flexibility. We propose STEVE-2, a hierarchical knowledge distillation framework for open-ended embodied tasks, characterized by 1) a hierarchical system for multi-granular task division, 2) a mirrored distillation method for parallel simulation data, and 3) an extra expert model for bringing additional knowledge into parallel simulation. After distillation, embodied agents can complete complex, open-ended tasks without additional expert guidance, utilizing the performance and knowledge of a versatile MLM. Extensive evaluations on navigation and creation tasks highlight the superior performance of STEVE-2 in open-ended tasks, with $1.4 times$ - $7.3 times$ in performance.
4/9/2024
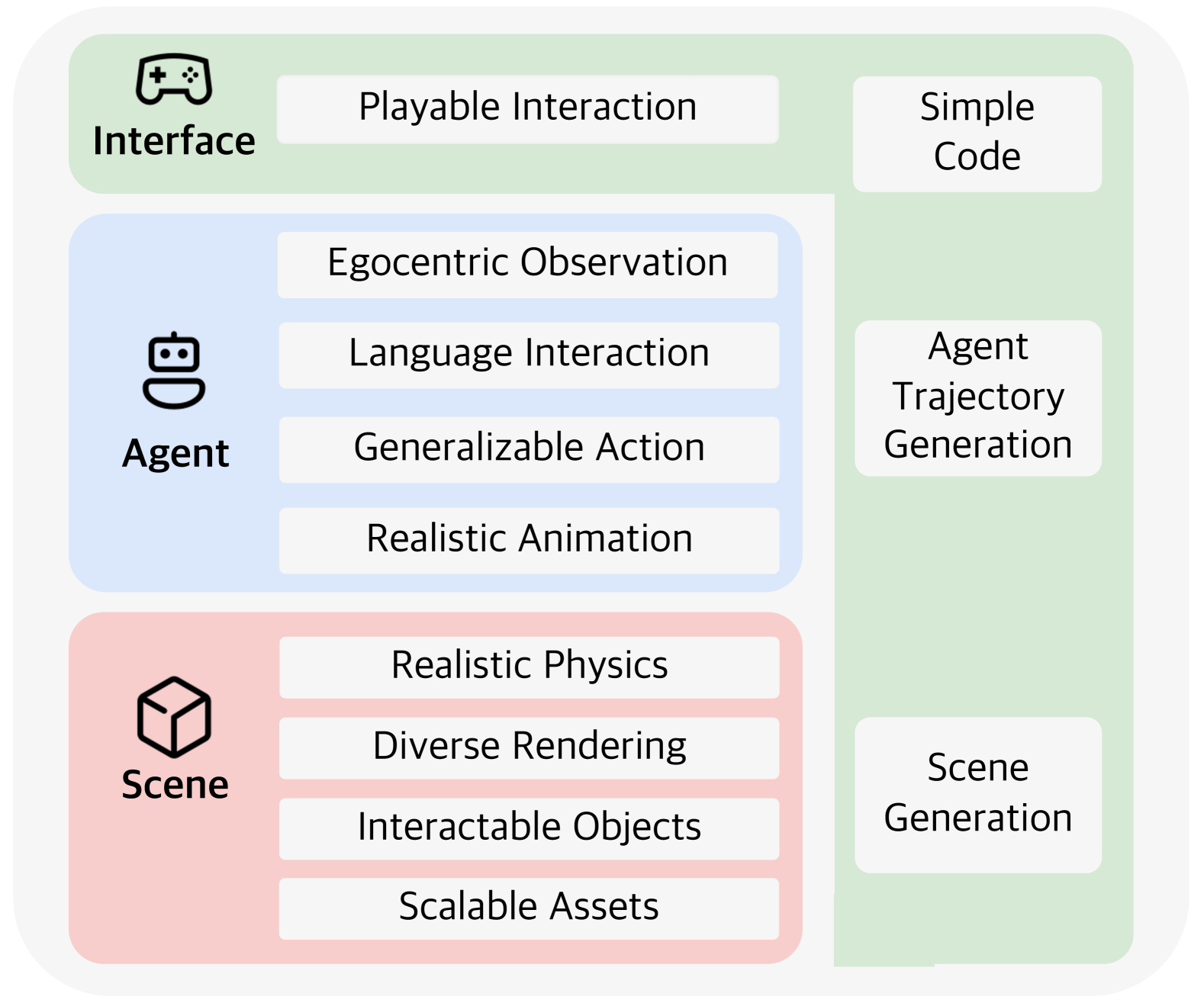
LEGENT: Open Platform for Embodied Agents
Zhili Cheng, Zhitong Wang, Jinyi Hu, Shengding Hu, An Liu, Yuge Tu, Pengkai Li, Lei Shi, Zhiyuan Liu, Maosong Sun
0
0
Despite advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), their integration into language-grounded, human-like embodied agents remains incomplete, hindering complex real-life task performance in physical environments. Existing integrations often feature limited open sourcing, challenging collective progress in this field. We introduce LEGENT, an open, scalable platform for developing embodied agents using LLMs and LMMs. LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale. In our experiments, an embryonic vision-language-action model trained on LEGENT-generated data surpasses GPT-4V in embodied tasks, showcasing promising generalization capabilities.
4/30/2024
🔄
Embodied Agents for Efficient Exploration and Smart Scene Description
Roberto Bigazzi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara
0
0
The development of embodied agents that can communicate with humans in natural language has gained increasing interest over the last years, as it facilitates the diffusion of robotic platforms in human-populated environments. As a step towards this objective, in this work, we tackle a setting for visual navigation in which an autonomous agent needs to explore and map an unseen indoor environment while portraying interesting scenes with natural language descriptions. To this end, we propose and evaluate an approach that combines recent advances in visual robotic exploration and image captioning on images generated through agent-environment interaction. Our approach can generate smart scene descriptions that maximize semantic knowledge of the environment and avoid repetitions. Further, such descriptions offer user-understandable insights into the robot's representation of the environment by highlighting the prominent objects and the correlation between them as encountered during the exploration. To quantitatively assess the performance of the proposed approach, we also devise a specific score that takes into account both exploration and description skills. The experiments carried out on both photorealistic simulated environments and real-world ones demonstrate that our approach can effectively describe the robot's point of view during exploration, improving the human-friendly interpretability of its observations.
4/16/2024
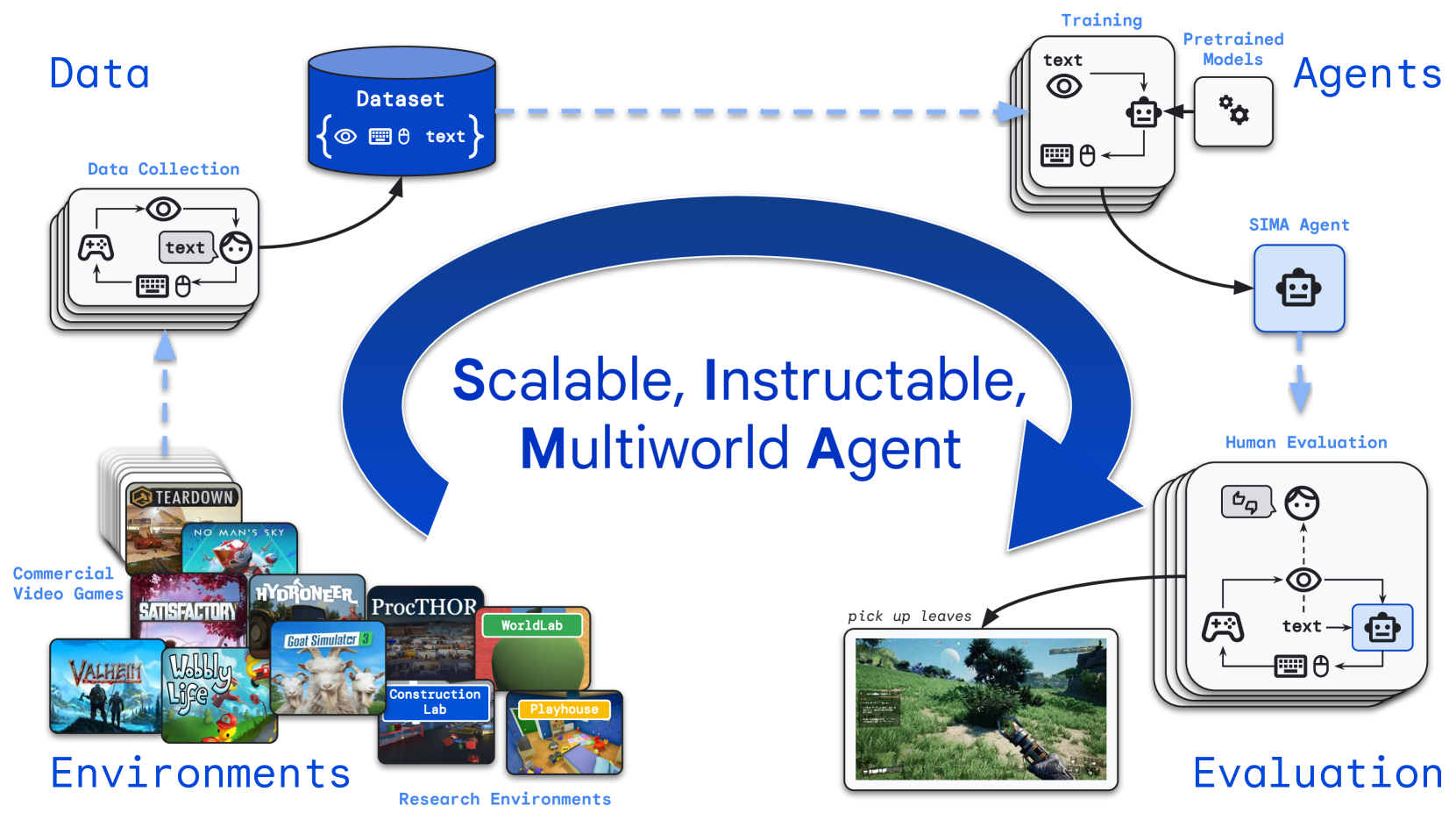
Scaling Instructable Agents Across Many Simulated Worlds
SIMA Team, Maria Abi Raad, Arun Ahuja, Catarina Barros, Frederic Besse, Andrew Bolt, Adrian Bolton, Bethanie Brownfield, Gavin Buttimore, Max Cant, Sarah Chakera, Stephanie C. Y. Chan, Jeff Clune, Adrian Collister, Vikki Copeman, Alex Cullum, Ishita Dasgupta, Dario de Cesare, Julia Di Trapani, Yani Donchev, Emma Dunleavy, Martin Engelcke, Ryan Faulkner, Frankie Garcia, Charles Gbadamosi, Zhitao Gong, Lucy Gonzales, Karol Gregor, Arne Olav Hallingstad, Tim Harley, Sam Haves, Felix Hill, Ed Hirst, Drew A. Hudson, Steph Hughes-Fitt, Danilo J. Rezende, Mimi Jasarevic, Laura Kampis, Rosemary Ke, Thomas Keck, Junkyung Kim, Oscar Knagg, Kavya Kopparapu, Andrew Lampinen, Shane Legg, Alexander Lerchner, Marjorie Limont, Yulan Liu, Maria Loks-Thompson, Joseph Marino, Kathryn Martin Cussons, Loic Matthey, Siobhan Mcloughlin, Piermaria Mendolicchio, Hamza Merzic, Anna Mitenkova, Alexandre Moufarek, Valeria Oliveira, Yanko Oliveira, Hannah Openshaw, Renke Pan, Aneesh Pappu, Alex Platonov, Ollie Purkiss, David Reichert, John Reid, Pierre Harvey Richemond, Tyson Roberts, Giles Ruscoe, Jaume Sanchez Elias, Tasha Sandars, Daniel P. Sawyer, Tim Scholtes, Guy Simmons, Daniel Slater, Hubert Soyer, Heiko Strathmann, Peter Stys, Allison C. Tam, Denis Teplyashin, Tayfun Terzi, Davide Vercelli, Bojan Vujatovic, Marcus Wainwright, Jane X. Wang, Zhengdong Wang, Daan Wierstra, Duncan Williams, Nathaniel Wong, Sarah York, Nick Young
0
0
Building embodied AI systems that can follow arbitrary language instructions in any 3D environment is a key challenge for creating general AI. Accomplishing this goal requires learning to ground language in perception and embodied actions, in order to accomplish complex tasks. The Scalable, Instructable, Multiworld Agent (SIMA) project tackles this by training agents to follow free-form instructions across a diverse range of virtual 3D environments, including curated research environments as well as open-ended, commercial video games. Our goal is to develop an instructable agent that can accomplish anything a human can do in any simulated 3D environment. Our approach focuses on language-driven generality while imposing minimal assumptions. Our agents interact with environments in real-time using a generic, human-like interface: the inputs are image observations and language instructions and the outputs are keyboard-and-mouse actions. This general approach is challenging, but it allows agents to ground language across many visually complex and semantically rich environments while also allowing us to readily run agents in new environments. In this paper we describe our motivation and goal, the initial progress we have made, and promising preliminary results on several diverse research environments and a variety of commercial video games.
4/17/2024