LEGENT: Open Platform for Embodied Agents

0
Sign in to get full access
Overview
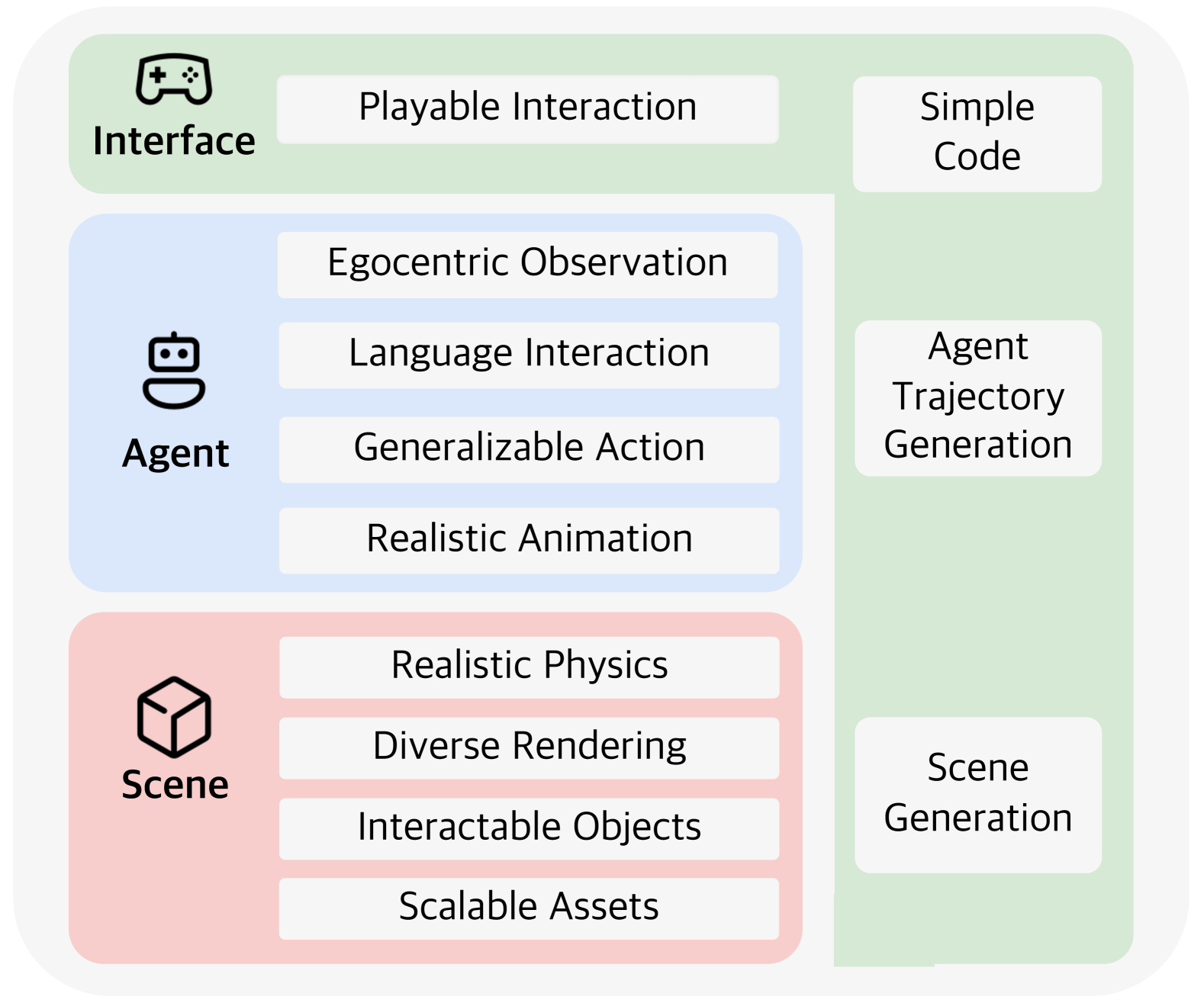
- This paper introduces LEGENT, an open platform for developing embodied agents that can operate in 3D virtual environments.
- LEGENT aims to provide a flexible and scalable infrastructure for training and deploying agents with diverse capabilities, including perception, language understanding, and physical interaction.
- The platform is designed to support research on embodied generalist agents, complex agent systems, and multi-modal agents trained using large language models.
Plain English Explanation
LEGENT is a new platform that allows researchers and developers to create virtual agents that can interact with 3D environments, similar to how robots or virtual assistants might operate in the real world. The platform provides a flexible and scalable infrastructure, meaning it can be used to build agents with a wide range of capabilities, from perception and language understanding to physical manipulation.
The goal of LEGENT is to support research on more advanced and capable virtual agents, sometimes called "embodied generalist agents". These are agents that can perform a variety of tasks in 3D environments, rather than being specialized for a single purpose. The platform also aims to help researchers develop "complex agent systems" and "multi-modal agents trained using large language models".
Technical Explanation
The LEGENT platform is designed to provide a unified infrastructure for training and deploying embodied agents in 3D virtual environments. It includes a flexible neural network architecture that can be customized to support a wide range of agent capabilities, such as perception, language understanding, and physical interaction.
LEGENT leverages large language models, such as GPT-3, to enable agents to engage in natural language communication and reasoning. This allows the agents to understand and respond to human instructions and queries in a more natural and conversational way, rather than being limited to a predefined set of commands.
The platform also includes support for multi-modal learning, allowing agents to integrate information from different sensory modalities, such as vision, audio, and touch. This can be particularly useful for tasks that require a deep understanding of the environment and the ability to reason about complex, real-world situations.
Critical Analysis
The LEGENT platform represents an important step forward in the development of more capable and versatile embodied agents. By providing a flexible and scalable infrastructure, it opens up new possibilities for research on complex agent systems and agents trained using large language models.
However, the paper does not address some of the potential challenges and limitations of this approach. For example, it is unclear how well the agents trained on LEGENT would generalize to real-world environments, which can be much more complex and unpredictable than the virtual worlds used for training.
Additionally, the reliance on large language models raises questions about the interpretability and robustness of the agent's decision-making processes. It may be difficult to understand and debug the agents' behavior, especially in situations where they encounter novel or ambiguous inputs.
Further research is needed to explore these issues and to ensure that the capabilities developed on the LEGENT platform can be effectively translated into practical applications that benefit society.
Conclusion
The LEGENT platform represents an exciting development in the field of embodied AI, providing a flexible and scalable infrastructure for the creation of advanced virtual agents. By leveraging large language models and multi-modal learning, LEGENT enables the development of more capable and versatile embodied agents that can interact with 3D environments in natural and intuitive ways.
While the platform has significant potential, further research is needed to address the challenges and limitations identified in the critical analysis. As the field of embodied AI continues to evolve, platforms like LEGENT will play a crucial role in driving innovation and advancing our understanding of how artificial agents can effectively navigate and engage with the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LEGENT: Open Platform for Embodied Agents
Zhili Cheng, Zhitong Wang, Jinyi Hu, Shengding Hu, An Liu, Yuge Tu, Pengkai Li, Lei Shi, Zhiyuan Liu, Maosong Sun
Despite advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), their integration into language-grounded, human-like embodied agents remains incomplete, hindering complex real-life task performance in physical environments. Existing integrations often feature limited open sourcing, challenging collective progress in this field. We introduce LEGENT, an open, scalable platform for developing embodied agents using LLMs and LMMs. LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale. In our experiments, an embryonic vision-language-action model trained on LEGENT-generated data surpasses GPT-4V in embodied tasks, showcasing promising generalization capabilities.
Read more8/20/2024

0
LangSuitE: Planning, Controlling and Interacting with Large Language Models in Embodied Text Environments
Zixia Jia, Mengmeng Wang, Baichen Tong, Song-Chun Zhu, Zilong Zheng
Recent advances in Large Language Models (LLMs) have shown inspiring achievements in constructing autonomous agents that rely on language descriptions as inputs. However, it remains unclear how well LLMs can function as few-shot or zero-shot embodied agents in dynamic interactive environments. To address this gap, we introduce LangSuitE, a versatile and simulation-free testbed featuring 6 representative embodied tasks in textual embodied worlds. Compared with previous LLM-based testbeds, LangSuitE (i) offers adaptability to diverse environments without multiple simulation engines, (ii) evaluates agents' capacity to develop ``internalized world knowledge'' with embodied observations, and (iii) allows easy customization of communication and action strategies. To address the embodiment challenge, we devise a novel chain-of-thought (CoT) schema, EmMem, which summarizes embodied states w.r.t. history information. Comprehensive benchmark results illustrate challenges and insights of embodied planning. LangSuitE represents a significant step toward building embodied generalists in the context of language models.
Read more6/26/2024
⛏️
0
An Embodied Generalist Agent in 3D World
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, Siyuan Huang
Leveraging massive knowledge from large language models (LLMs), recent machine learning models show notable successes in general-purpose task solving in diverse domains such as computer vision and robotics. However, several significant challenges remain: (i) most of these models rely on 2D images yet exhibit a limited capacity for 3D input; (ii) these models rarely explore the tasks inherently defined in 3D world, e.g., 3D grounding, embodied reasoning and acting. We argue these limitations significantly hinder current models from performing real-world tasks and approaching general intelligence. To this end, we introduce LEO, an embodied multi-modal generalist agent that excels in perceiving, grounding, reasoning, planning, and acting in the 3D world. LEO is trained with a unified task interface, model architecture, and objective in two stages: (i) 3D vision-language (VL) alignment and (ii) 3D vision-language-action (VLA) instruction tuning. We collect large-scale datasets comprising diverse object-level and scene-level tasks, which require considerable understanding of and interaction with the 3D world. Moreover, we meticulously design an LLM-assisted pipeline to produce high-quality 3D VL data. Through extensive experiments, we demonstrate LEO's remarkable proficiency across a wide spectrum of tasks, including 3D captioning, question answering, embodied reasoning, navigation and manipulation. Our ablative studies and scaling analyses further provide valuable insights for developing future embodied generalist agents. Code and data are available on project page.
Read more5/10/2024

0
Do We Really Need a Complex Agent System? Distill Embodied Agent into a Single Model
Zhonghan Zhao, Ke Ma, Wenhao Chai, Xuan Wang, Kewei Chen, Dongxu Guo, Yanting Zhang, Hongwei Wang, Gaoang Wang
With the power of large language models (LLMs), open-ended embodied agents can flexibly understand human instructions, generate interpretable guidance strategies, and output executable actions. Nowadays, Multi-modal Language Models~(MLMs) integrate multi-modal signals into LLMs, further bringing richer perception to entity agents and allowing embodied agents to perceive world-understanding tasks more delicately. However, existing works: 1) operate independently by agents, each containing multiple LLMs, from perception to action, resulting in gaps between complex tasks and execution; 2) train MLMs on static data, struggling with dynamics in open-ended scenarios; 3) input prior knowledge directly as prompts, suppressing application flexibility. We propose STEVE-2, a hierarchical knowledge distillation framework for open-ended embodied tasks, characterized by 1) a hierarchical system for multi-granular task division, 2) a mirrored distillation method for parallel simulation data, and 3) an extra expert model for bringing additional knowledge into parallel simulation. After distillation, embodied agents can complete complex, open-ended tasks without additional expert guidance, utilizing the performance and knowledge of a versatile MLM. Extensive evaluations on navigation and creation tasks highlight the superior performance of STEVE-2 in open-ended tasks, with $1.4 times$ - $7.3 times$ in performance.
Read more4/9/2024