Embracing Unknown Step by Step: Towards Reliable Sparse Training in Real World
2403.20047
0
0
Abstract
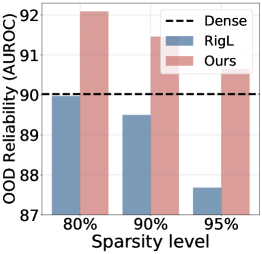
Sparse training has emerged as a promising method for resource-efficient deep neural networks (DNNs) in real-world applications. However, the reliability of sparse models remains a crucial concern, particularly in detecting unknown out-of-distribution (OOD) data. This study addresses the knowledge gap by investigating the reliability of sparse training from an OOD perspective and reveals that sparse training exacerbates OOD unreliability. The lack of unknown information and the sparse constraints hinder the effective exploration of weight space and accurate differentiation between known and unknown knowledge. To tackle these challenges, we propose a new unknown-aware sparse training method, which incorporates a loss modification, auto-tuning strategy, and a voting scheme to guide weight space exploration and mitigate confusion between known and unknown information without incurring significant additional costs or requiring access to additional OOD data. Theoretical insights demonstrate how our method reduces model confidence when faced with OOD samples. Empirical experiments across multiple datasets, model architectures, and sparsity levels validate the effectiveness of our method, with improvements of up to textbf{8.4%} in AUROC while maintaining comparable or higher accuracy and calibration. This research enhances the understanding and readiness of sparse DNNs for deployment in resource-limited applications. Our code is available on: url{https://github.com/StevenBoys/MOON}.
Create account to get full access
Overview
- This paper explores approaches to make sparse training of neural networks more reliable and practical for real-world applications.
- The authors propose a new method called "Embracing Unknown" that gradually increases the sparsity of the neural network during training.
- The goal is to enable sparse models that maintain high performance while being more efficient and deployable on resource-constrained devices.
Plain English Explanation
The paper addresses a key challenge in deploying machine learning models in the real world - balancing model performance and efficiency. Typically, neural networks are trained to be as accurate as possible, but this results in large, complex models that require significant computational resources to run.
The researchers explore a different approach called "sparse training," which aims to prune away unnecessary connections in the neural network to create a more compact and efficient model. However, sparse training can be tricky - if done too aggressively, it can significantly degrade the model's performance.
The new "Embracing Unknown" method takes a gradual, step-by-step approach to increasing the sparsity of the network during training. Instead of trying to find the optimal sparse structure all at once, it slowly explores different sparse configurations, embracing the uncertainty of what the best sparse model will be.
This allows the model to adapt and maintain high accuracy even as it becomes more sparse and efficient. The key insight is that the optimal sparse structure may not be obvious at the start, so it's important to be flexible and explore different options during training.
By taking this adaptive approach, the researchers were able to create sparse neural network models that retained impressive performance while being much smaller and more efficient. This could enable deploying high-quality AI systems on resource-constrained edge devices like smartphones or embedded systems.
Technical Explanation
The paper proposes a new sparse training method called "Embracing Unknown" (EU) that gradually increases the sparsity of a neural network during the training process. Rather than trying to find the optimal sparse configuration all at once, EU systematically explores different sparse structures, embracing the uncertainty about the best final sparse model.
The key components of the EU method are:
- Sparse Initialization: The network starts with a pre-defined sparse structure, with a certain percentage of weights set to zero.
- Iterative Sparsification: During training, the sparsity of the network is increased in an iterative manner, gradually pruning more weights.
- Adaptive Sparse Structure Search: The specific sparse structure (which weights to prune) is not fixed, but adaptively searched for at each iteration to maintain high performance.
The authors conducted experiments on various computer vision and natural language processing tasks, comparing EU to other sparse training techniques. They found that EU was able to achieve high accuracies with much sparser models compared to standard training or other pruning methods.
For example, on the ImageNet classification task, EU was able to reach 75.7% top-1 accuracy with a model that was only 5% the size of the original dense model. This demonstrates the potential of the EU approach to create efficient, deployable AI systems.
Critical Analysis
The "Embracing Unknown" method proposed in this paper represents an interesting and promising advance in the field of sparse neural network training. By taking a gradual, adaptive approach to increasing sparsity, the technique is able to maintain high model performance even as the networks become more compact and efficient.
One potential limitation of the work is that the specific hyperparameters and search strategies used for the adaptive sparse structure search are not fully explored. The paper provides the high-level algorithm, but additional experimentation and analysis may be needed to understand how to best configure these search procedures.
Additionally, the evaluation is primarily focused on standard computer vision and NLP benchmarks. Further research may be needed to understand how well the EU approach generalizes to other domains or real-world deployment scenarios with additional constraints like latency, power consumption, or hardware compatibility.
Nevertheless, the core insight of embracing the unknown and gradually increasing sparsity during training is a clever and impactful contribution. Developing reliable sparse models is a crucial challenge for enabling high-performance AI on resource-constrained edge devices. This work represents an important step forward in that direction.
Conclusion
This paper presents a new sparse training technique called "Embracing Unknown" that takes a step-by-step approach to increasing model sparsity during the training process. By adaptively exploring different sparse configurations rather than trying to find the optimal structure all at once, the method is able to create highly efficient neural network models that maintain impressive performance.
The results demonstrate the potential of this approach to enable the deployment of powerful AI systems on resource-constrained edge devices like smartphones and embedded systems. As the demand for ubiquitous and energy-efficient AI continues to grow, techniques like "Embracing Unknown" will become increasingly important for translating cutting-edge machine learning research into practical real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
0
0
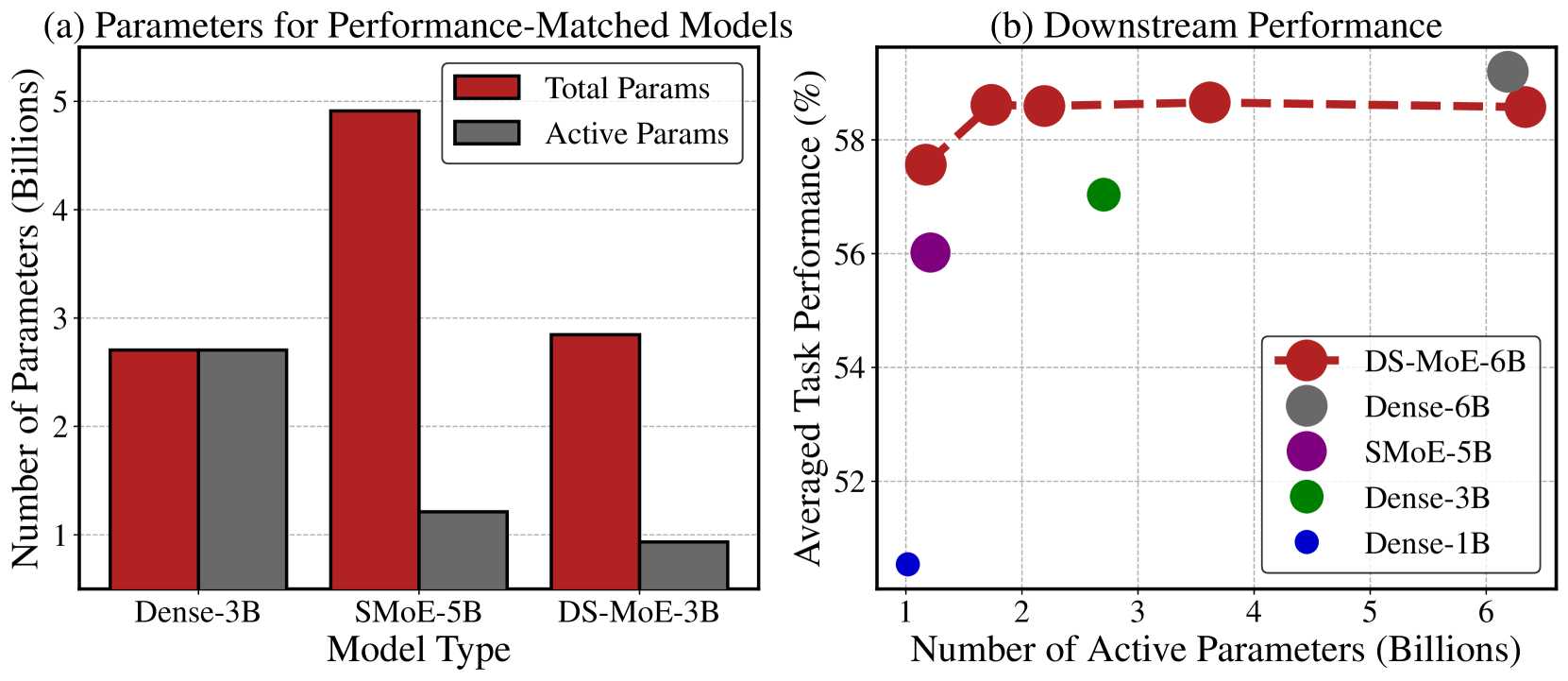
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
4/9/2024

Gradient-Regularized Out-of-Distribution Detection
Sina Sharifi, Taha Entesari, Bardia Safaei, Vishal M. Patel, Mahyar Fazlyab
0
0
One of the challenges for neural networks in real-life applications is the overconfident errors these models make when the data is not from the original training distribution. Addressing this issue is known as Out-of-Distribution (OOD) detection. Many state-of-the-art OOD methods employ an auxiliary dataset as a surrogate for OOD data during training to achieve improved performance. However, these methods fail to fully exploit the local information embedded in the auxiliary dataset. In this work, we propose the idea of leveraging the information embedded in the gradient of the loss function during training to enable the network to not only learn a desired OOD score for each sample but also to exhibit similar behavior in a local neighborhood around each sample. We also develop a novel energy-based sampling method to allow the network to be exposed to more informative OOD samples during the training phase. This is especially important when the auxiliary dataset is large. We demonstrate the effectiveness of our method through extensive experiments on several OOD benchmarks, improving the existing state-of-the-art FPR95 by 4% on our ImageNet experiment. We further provide a theoretical analysis through the lens of certified robustness and Lipschitz analysis to showcase the theoretical foundation of our work. We will publicly release our code after the review process.
4/24/2024
🏋️
TinyTrain: Resource-Aware Task-Adaptive Sparse Training of DNNs at the Data-Scarce Edge
Young D. Kwon, Rui Li, Stylianos I. Venieris, Jagmohan Chauhan, Nicholas D. Lane, Cecilia Mascolo
0
0
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCUs), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss (>10%). In this paper, we propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel to update based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0% in accuracy, while reducing the backward-pass memory and computation cost by up to 1,098x and 7.68x, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5x faster and 3.5x more energy-efficient training over status-quo approaches, and 2.23x smaller memory footprint than SOTA methods, while remaining within the 1 MB memory envelope of MCU-grade platforms.
6/12/2024

Split-Ensemble: Efficient OOD-aware Ensemble via Task and Model Splitting
Anthony Chen, Huanrui Yang, Yulu Gan, Denis A Gudovskiy, Zhen Dong, Haofan Wang, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, Shanghang Zhang
0
0
Uncertainty estimation is crucial for machine learning models to detect out-of-distribution (OOD) inputs. However, the conventional discriminative deep learning classifiers produce uncalibrated closed-set predictions for OOD data. A more robust classifiers with the uncertainty estimation typically require a potentially unavailable OOD dataset for outlier exposure training, or a considerable amount of additional memory and compute to build ensemble models. In this work, we improve on uncertainty estimation without extra OOD data or additional inference costs using an alternative Split-Ensemble method. Specifically, we propose a novel subtask-splitting ensemble training objective, where a common multiclass classification task is split into several complementary subtasks. Then, each subtask's training data can be considered as OOD to the other subtasks. Diverse submodels can therefore be trained on each subtask with OOD-aware objectives. The subtask-splitting objective enables us to share low-level features across submodels to avoid parameter and computational overheads. In particular, we build a tree-like Split-Ensemble architecture by performing iterative splitting and pruning from a shared backbone model, where each branch serves as a submodel corresponding to a subtask. This leads to improved accuracy and uncertainty estimation across submodels under a fixed ensemble computation budget. Empirical study with ResNet-18 backbone shows Split-Ensemble, without additional computation cost, improves accuracy over a single model by 0.8%, 1.8%, and 25.5% on CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively. OOD detection for the same backbone and in-distribution datasets surpasses a single model baseline by, correspondingly, 2.2%, 8.1%, and 29.6% mean AUROC.
5/28/2024