Gradient-Regularized Out-of-Distribution Detection
2404.12368
0
0

Abstract
One of the challenges for neural networks in real-life applications is the overconfident errors these models make when the data is not from the original training distribution. Addressing this issue is known as Out-of-Distribution (OOD) detection. Many state-of-the-art OOD methods employ an auxiliary dataset as a surrogate for OOD data during training to achieve improved performance. However, these methods fail to fully exploit the local information embedded in the auxiliary dataset. In this work, we propose the idea of leveraging the information embedded in the gradient of the loss function during training to enable the network to not only learn a desired OOD score for each sample but also to exhibit similar behavior in a local neighborhood around each sample. We also develop a novel energy-based sampling method to allow the network to be exposed to more informative OOD samples during the training phase. This is especially important when the auxiliary dataset is large. We demonstrate the effectiveness of our method through extensive experiments on several OOD benchmarks, improving the existing state-of-the-art FPR95 by 4% on our ImageNet experiment. We further provide a theoretical analysis through the lens of certified robustness and Lipschitz analysis to showcase the theoretical foundation of our work. We will publicly release our code after the review process.
Create account to get full access
Overview
- This paper introduces a new method for detecting out-of-distribution (OOD) samples, which are data points that are significantly different from the training data and can cause machine learning models to behave unexpectedly.
- The proposed approach, called Gradient-Regularized Out-of-Distribution Detection (GROOD), uses the gradients of the model's loss function to identify OOD samples.
- GROOD aims to improve upon existing OOD detection methods by providing a more robust and efficient way to identify these problematic data points.
Plain English Explanation
Machine learning models are trained on a specific set of data, but in the real world, they often encounter data that is very different from what they were trained on. These out-of-distribution (OOD) samples can cause the models to make unexpected or even incorrect predictions, which can be a significant problem in many applications.
The Gradient-Regularized Out-of-Distribution Detection (GROOD) method proposed in this paper aims to address this issue by using the gradients of the model's loss function to identify OOD samples. The idea is that when the model is presented with an OOD sample, the gradients of the loss function will behave differently compared to when the model is shown an in-distribution sample.
By monitoring these gradient patterns, the GROOD method can detect OOD samples more effectively than some existing approaches. This can help machine learning systems become more robust and reliable, as they can identify and potentially avoid issues caused by unexpected data.
The paper also discusses related work in the field of OOD detection and how GROOD compares to other methods. Overall, this research represents an important step towards building more reliable and trustworthy machine learning systems that can handle a wider range of real-world data.
Technical Explanation
The key idea behind the Gradient-Regularized Out-of-Distribution Detection (GROOD) method is to use the gradients of the model's loss function to distinguish between in-distribution and out-of-distribution (OOD) samples.
The authors hypothesize that when a model is presented with an OOD sample, the gradients of the loss function will behave differently compared to when the model is shown an in-distribution sample. By monitoring these gradient patterns, GROOD can detect OOD samples more effectively than some existing post-hoc OOD detection approaches.
To implement GROOD, the authors propose a two-stage training process. First, they train the model on the in-distribution data using a standard loss function. Then, they fine-tune the model by adding a gradient regularization term to the loss function, which encourages the model to learn gradients that are more sensitive to OOD samples.
The authors evaluate GROOD on several benchmark OOD detection tasks, including CIFAR-10 vs. SVHN and ImageNet-1K vs. Places365. The results show that GROOD outperforms several state-of-the-art OOD detection methods in terms of accuracy and efficiency.
Critical Analysis
The Gradient-Regularized Out-of-Distribution Detection (GROOD) method proposed in this paper represents an interesting and promising approach to the problem of OOD detection. The core idea of using gradient patterns to identify OOD samples is well-motivated and the experimental results are compelling.
However, the paper does not address some potential limitations or caveats of the GROOD method. For example, it is unclear how GROOD would perform on more challenging OOD detection tasks, such as when the in-distribution and OOD samples are more similar. Additionally, the paper does not explore the computational and memory overhead of the two-stage training process, which could be a practical concern for some applications.
It would also be interesting to see how GROOD compares to more recently proposed OOD detection methods, especially those that leverage additional information (e.g., uncertainty estimates) or take a more holistic approach to the problem.
Overall, the Gradient-Regularized Out-of-Distribution Detection method is a valuable contribution to the field of OOD detection, and the authors have demonstrated its effectiveness on standard benchmarks. However, further research is needed to fully understand the strengths, limitations, and practical implications of this approach.
Conclusion
The Gradient-Regularized Out-of-Distribution Detection (GROOD) method proposed in this paper offers a novel and promising approach to the problem of identifying out-of-distribution (OOD) samples, which can cause significant issues for machine learning models deployed in the real world.
By using the gradients of the model's loss function to detect OOD samples, GROOD aims to provide a more robust and efficient alternative to existing OOD detection methods. The experimental results are encouraging and suggest that GROOD could be a valuable tool for building more reliable and trustworthy machine learning systems that can handle a wider range of real-world data.
While the paper does not address all the potential limitations of the GROOD method, it represents an important step forward in the field of OOD detection. Further research and development of this approach could lead to significant advancements in the robustness and safety of machine learning applications, ultimately benefiting both the technology and the people who rely on it.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
0
0
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
6/5/2024
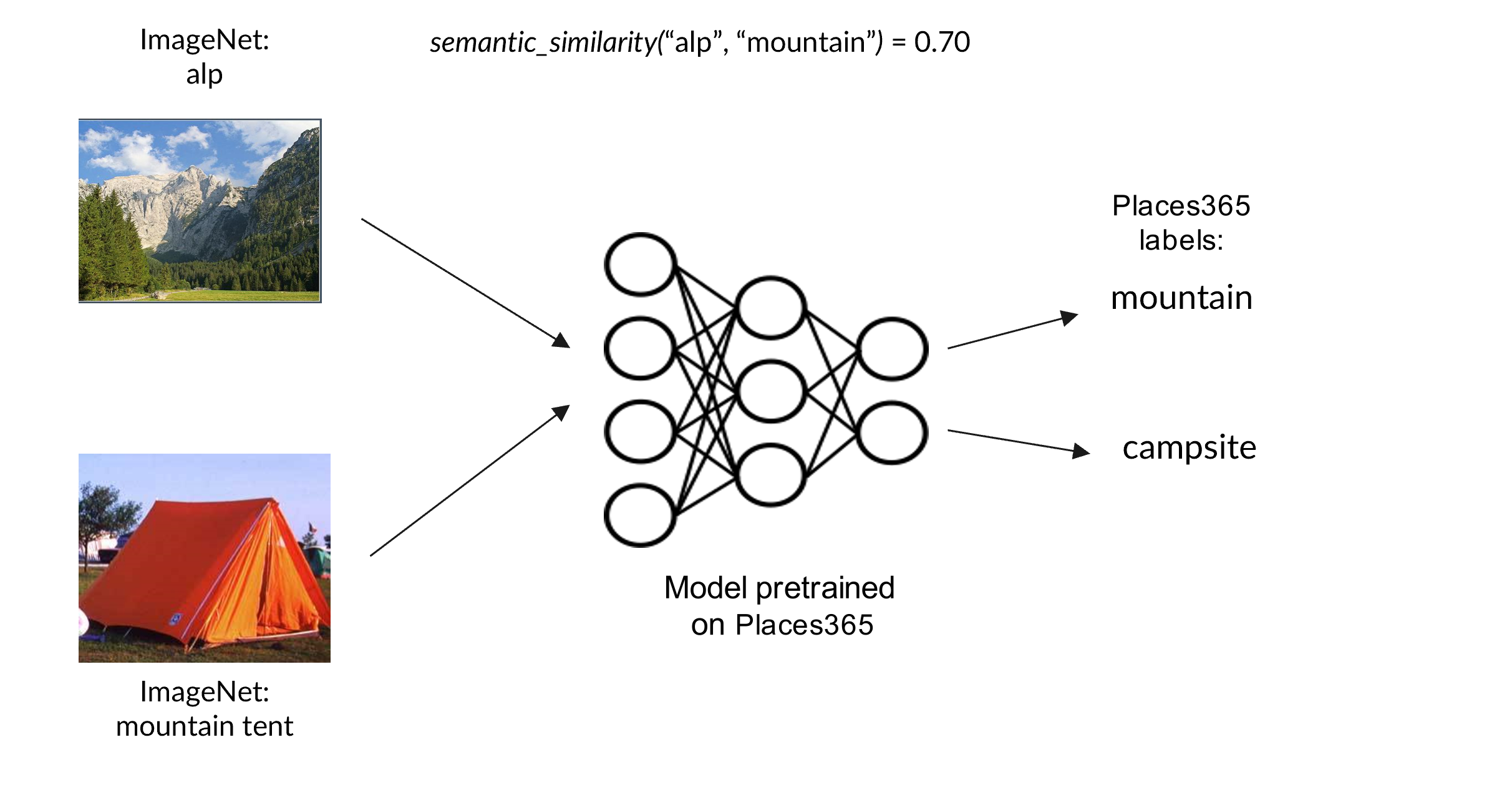
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
0
0
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
4/17/2024

GROD: Enhancing Generalization of Transformer with Out-of-Distribution Detection
Yijin Zhou, Yuguang Wang
0
0
Transformer networks excel in natural language processing (NLP) and computer vision (CV) tasks. However, they face challenges in generalizing to Out-of-Distribution (OOD) datasets, that is, data whose distribution differs from that seen during training. The OOD detection aims to distinguish data that deviates from the expected distribution, while maintaining optimal performance on in-distribution (ID) data. This paper introduces a novel approach based on OOD detection, termed the Generate Rounded OOD Data (GROD) algorithm, which significantly bolsters the generalization performance of transformer networks across various tasks. GROD is motivated by our new OOD detection Probably Approximately Correct (PAC) Theory for transformer. The transformer has learnability in terms of OOD detection that is, when the data is sufficient the outlier can be well represented. By penalizing the misclassification of OOD data within the loss function and generating synthetic outliers, GROD guarantees learnability and refines the decision boundaries between inlier and outlier. This strategy demonstrates robust adaptability and general applicability across different data types. Evaluated across diverse OOD detection tasks in NLP and CV, GROD achieves SOTA regardless of data format. On average, it reduces the SOTA FPR@95 from 21.97% to 0.12%, and improves AUROC from 93.62% to 99.98% on image classification tasks, and the SOTA FPR@95 by 12.89% and AUROC by 2.27% in detecting semantic text outliers. The code is available at https://anonymous.4open.science/r/GROD-OOD-Detection-with-transformers-B70F.
6/21/2024
🔎
Out-of-distribution detection based on subspace projection of high-dimensional features output by the last convolutional layer
Qiuyu Zhu, Yiwei He
0
0
Out-of-distribution (OOD) detection, crucial for reliable pattern classification, discerns whether a sample originates outside the training distribution. This paper concentrates on the high-dimensional features output by the final convolutional layer, which contain rich image features. Our key idea is to project these high-dimensional features into two specific feature subspaces, leveraging the dimensionality reduction capacity of the network's linear layers, trained with Predefined Evenly-Distribution Class Centroids (PEDCC)-Loss. This involves calculating the cosines of three projection angles and the norm values of features, thereby identifying distinctive information for in-distribution (ID) and OOD data, which assists in OOD detection. Building upon this, we have modified the batch normalization (BN) and ReLU layer preceding the fully connected layer, diminishing their impact on the output feature distributions and thereby widening the distribution gap between ID and OOD data features. Our method requires only the training of the classification network model, eschewing any need for input pre-processing or specific OOD data pre-tuning. Extensive experiments on several benchmark datasets demonstrates that our approach delivers state-of-the-art performance. Our code is available at https://github.com/Hewell0/ProjOOD.
5/6/2024