Emergence of a High-Dimensional Abstraction Phase in Language Transformers
2405.15471
0
0
Abstract
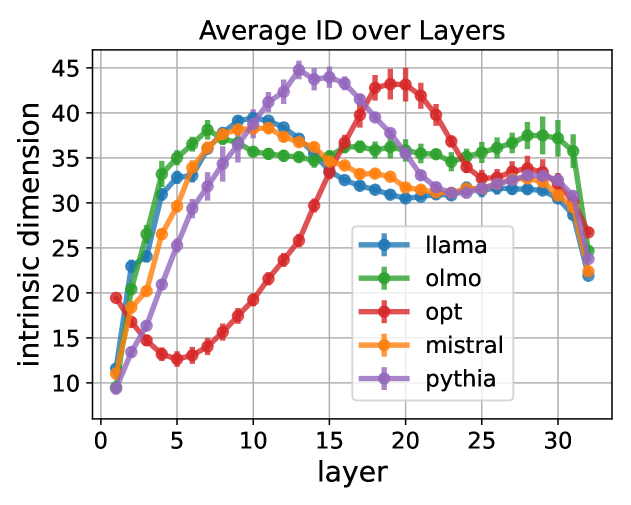
A language model (LM) is a mapping from a linguistic context to an output token. However, much remains to be known about this mapping, including how its geometric properties relate to its function. We take a high-level geometric approach to its analysis, observing, across five pre-trained transformer-based LMs and three input datasets, a distinct phase characterized by high intrinsic dimensionality. During this phase, representations (1) correspond to the first full linguistic abstraction of the input; (2) are the first to viably transfer to downstream tasks; (3) predict each other across different LMs. Moreover, we find that an earlier onset of the phase strongly predicts better language modelling performance. In short, our results suggest that a central high-dimensionality phase underlies core linguistic processing in many common LM architectures.
Create account to get full access
Overview
- This paper explores the emergence of a high-dimensional abstraction phase in large language models (LLMs).
- The researchers investigate how LLMs develop sophisticated representational capabilities as they scale in size and complexity.
- The findings shed light on the inner workings of LLMs and have implications for understanding the nature of language and cognition.
Plain English Explanation
As language models like GPT-3 and BERT continue to grow in size and capability, researchers are becoming increasingly interested in understanding how these models develop their impressive language skills. This paper explores the emergence of a "high-dimensional abstraction phase" in these large language models.
The key idea is that as LLMs become more complex, they start to form abstract, high-level representations of language, going beyond just memorizing and regurgitating text. These abstract representations allow the models to reason about language in more sophisticated ways, drawing connections and generalizing to new contexts.
To study this phenomenon, the researchers analyzed the internal activations of different language models as they processed various linguistic tasks. They found that at a certain model size, there was a distinct shift where the models started to exhibit these high-dimensional, abstract representations, rather than just shallow pattern matching.
This discovery sheds light on the nature of language and cognition, suggesting that as humans and AI systems become more capable at language, they develop a deeper, more abstract understanding of its underlying structure and meaning. It has implications for how we design and interpret these powerful language models.
Technical Explanation
The researchers in this paper set out to investigate the emergence of a "high-dimensional abstraction phase" in large language models (LLMs) as they scale in size and complexity.
They hypothesized that as LLMs become more sophisticated, they would start to develop abstract, high-level representations of language, going beyond just memorizing and regurgitating text. To test this, they analyzed the internal activations of various language models, including GPT-3, BERT, and others, as they processed a range of linguistic tasks.
The key finding was that at a certain model size, there was a distinct shift where the models began to exhibit these high-dimensional, abstract representations, rather than just shallow pattern matching. The researchers quantified this shift using various metrics, such as the intrinsic dimensionality of the activation space and the degree of linear separability of linguistic features.
Interestingly, the researchers found that this abstraction phase emerged at different points for different types of linguistic features, suggesting that the models were developing a hierarchical understanding of language, with some concepts becoming more abstract before others.
These results have important implications for our understanding of how large language models work and their potential as cognitive models. They suggest that as these models become more powerful, they start to form a deeper, more sophisticated representation of language, which could shed light on the nature of human language and cognition.
Critical Analysis
The researchers in this paper provide a compelling account of the emergence of high-dimensional abstraction in large language models. The experimental design and analysis techniques are rigorous, and the findings are well-supported by the data.
However, it's important to note that this research is primarily focused on understanding the internal representations of language models, and does not directly address their real-world performance or capabilities. There are still many open questions about how these abstract representations translate to practical language understanding and generation tasks.
Additionally, the paper does not delve into the potential biases or limitations of these language models, which is an area of growing concern in the field of AI. As these models become more powerful and influential, it will be crucial to carefully examine their shortcomings and potential negative impacts.
Overall, this research represents an important step forward in our understanding of the inner workings of large language models, and its findings have significant implications for the field of artificial intelligence and cognitive science. However, further research is needed to fully explore the practical and ethical implications of these powerful language models.
Conclusion
This paper presents a fascinating exploration of the emergence of high-dimensional abstraction in large language models. The researchers' findings suggest that as these models become more complex, they develop a deeper, more sophisticated understanding of language, going beyond simple pattern matching to form abstract, hierarchical representations.
These insights have important implications for our understanding of language and cognition, both in artificial and human systems. They suggest that as AI systems become more capable at language, they may start to exhibit cognitive capabilities that resemble those of the human mind.
While this research represents an important step forward, there are still many open questions and potential limitations that need to be addressed. As these powerful language models continue to advance, it will be crucial for researchers, policymakers, and the public to carefully consider their impact and work towards responsible development and deployment of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Quantifying Emergence in Large Language Models
Hang Chen, Xinyu Yang, Jiaying Zhu, Wenya Wang
0
0
Emergence, broadly conceptualized as the ``intelligent'' behaviors of LLMs, has recently been studied and proved challenging to quantify due to the lack of a measurable definition. Most commonly, it has been estimated statistically through model performances across extensive datasets and tasks, which consumes significant resources. In addition, such estimation is difficult to interpret and may not accurately reflect the models' intrinsic emergence. In this work, we propose a quantifiable solution for estimating emergence. Inspired by emergentism in dynamics, we quantify the strength of emergence by comparing the entropy reduction of the macroscopic (semantic) level with that of the microscopic (token) level, both of which are derived from the representations within the transformer block. Using a low-cost estimator, our quantification method demonstrates consistent behaviors across a suite of LMs (GPT-2, GEMMA, etc.) under both in-context learning (ICL) and natural sentences. Empirical results show that (1) our method gives consistent measurements which align with existing observations based on performance metrics, validating the effectiveness of our emergence quantification; (2) our proposed metric uncovers novel emergence patterns such as the correlations between the variance of our metric and the number of ``shots'' in ICL, which further suggests a new way of interpreting hallucinations in LLMs; (3) we offer a potential solution towards estimating the emergence of larger and closed-resource LMs via smaller LMs like GPT-2. Our codes are available at: https://github.com/Zodiark-ch/Emergence-of-LLMs/.
5/22/2024
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
0
0
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
6/5/2024
A Survey on Large Language Models from Concept to Implementation
Chen Wang, Jin Zhao, Jiaqi Gong
0
0
Recent advancements in Large Language Models (LLMs), particularly those built on Transformer architectures, have significantly broadened the scope of natural language processing (NLP) applications, transcending their initial use in chatbot technology. This paper investigates the multifaceted applications of these models, with an emphasis on the GPT series. This exploration focuses on the transformative impact of artificial intelligence (AI) driven tools in revolutionizing traditional tasks like coding and problem-solving, while also paving new paths in research and development across diverse industries. From code interpretation and image captioning to facilitating the construction of interactive systems and advancing computational domains, Transformer models exemplify a synergy of deep learning, data analysis, and neural network design. This survey provides an in-depth look at the latest research in Transformer models, highlighting their versatility and the potential they hold for transforming diverse application sectors, thereby offering readers a comprehensive understanding of the current and future landscape of Transformer-based LLMs in practical applications.
5/29/2024

Concept Formation and Alignment in Language Models: Bridging Statistical Patterns in Latent Space to Concept Taxonomy
Mehrdad Khatir, Chandan K. Reddy
0
0
This paper explores the concept formation and alignment within the realm of language models (LMs). We propose a mechanism for identifying concepts and their hierarchical organization within the semantic representations learned by various LMs, encompassing a spectrum from early models like Glove to the transformer-based language models like ALBERT and T5. Our approach leverages the inherent structure present in the semantic embeddings generated by these models to extract a taxonomy of concepts and their hierarchical relationships. This investigation sheds light on how LMs develop conceptual understanding and opens doors to further research to improve their ability to reason and leverage real-world knowledge. We further conducted experiments and observed the possibility of isolating these extracted conceptual representations from the reasoning modules of the transformer-based LMs. The observed concept formation along with the isolation of conceptual representations from the reasoning modules can enable targeted token engineering to open the door for potential applications in knowledge transfer, explainable AI, and the development of more modular and conceptually grounded language models.
6/11/2024