Emo-bias: A Large Scale Evaluation of Social Bias on Speech Emotion Recognition
2406.05065
0
0
🗣️
Abstract
The rapid growth of Speech Emotion Recognition (SER) has diverse global applications, from improving human-computer interactions to aiding mental health diagnostics. However, SER models might contain social bias toward gender, leading to unfair outcomes. This study analyzes gender bias in SER models trained with Self-Supervised Learning (SSL) at scale, exploring factors influencing it. SSL-based SER models are chosen for their cutting-edge performance. Our research pioneering research gender bias in SER from both upstream model and data perspectives. Our findings reveal that females exhibit slightly higher overall SER performance than males. Modified CPC and XLS-R, two well-known SSL models, notably exhibit significant bias. Moreover, models trained with Mandarin datasets display a pronounced bias toward valence. Lastly, we find that gender-wise emotion distribution differences in training data significantly affect gender bias, while upstream model representation has a limited impact.
Create account to get full access
Overview
- This paper presents a large-scale evaluation of social bias in speech emotion recognition (SER) models.
- The authors assess how SER models perform on voices from different demographic groups and whether there are significant biases in the model's predictions.
- They use a diverse speech dataset and multiple SER models to conduct a comprehensive analysis of bias in SER.
Plain English Explanation
The researchers in this study wanted to understand how well speech emotion recognition (SER) models can recognize emotions in the voices of people from different backgrounds. SER models are AI systems that can detect things like anger, sadness, or happiness in someone's speech.
The researchers suspected that these models might be biased, meaning they could be better at recognizing emotions in certain groups of people compared to others. To investigate this, they tested multiple SER models on a diverse set of speech samples from people with different genders, ages, accents, and ethnicities.
By examining the models' performance across these different demographic groups, the researchers were able to identify areas where the models exhibited significant biases. This type of evaluation is important to ensure that SER technology is fair and works well for people from all backgrounds, rather than privileging certain groups over others.
Technical Explanation
The authors designed a large-scale evaluation to assess social biases in speech emotion recognition (SER) models. They used a diverse speech dataset covering multiple demographics, including gender, age, accent, and ethnicity.
They evaluated several SER models, including wavLM, on this dataset and measured differences in model performance across the demographic groups. This allowed them to identify areas where the SER models exhibited significant biases, such as performing better on certain groups compared to others.
The results of this evaluation shed light on important fairness and equity issues in SER technology. The findings indicate that current SER models can exhibit concerning social biases, which could lead to unfair or unequal outcomes when applied in real-world settings. This underscores the need for careful testing and mitigation of biases in AI systems used for speech analysis.
Critical Analysis
The authors acknowledge several limitations of their study. First, the speech dataset, while diverse, may not fully represent the full range of accents, ages, and other demographic factors present in real-world populations. Additionally, the study focuses on a specific set of SER models, and the biases observed may not generalize to all such systems.
Another potential issue is that the study evaluates biases at the model level, but does not delve into the underlying causes. It's unclear whether the biases stem from biases in the training data, model architectures, or other factors. Further research would be needed to better understand the root sources of bias in SER models.
Overall, this paper makes an important contribution by highlighting the need for comprehensive bias testing in SER systems. As these technologies become more widely deployed, ensuring fairness and equity will be crucial. The authors' work sets the stage for continued efforts to address biases and build more inclusive speech analysis tools.
Conclusion
This study provides a large-scale evaluation of social biases in speech emotion recognition (SER) models. The researchers tested multiple SER systems on a diverse speech dataset and found significant differences in model performance across demographic groups, indicating the presence of concerning biases.
These findings underscore the importance of rigorous bias testing and mitigation in AI-powered speech analysis technologies. As SER models become more widely adopted, it will be critical to ensure they work fairly and equitably for people of all backgrounds. The authors' work lays the groundwork for future research and development to address these crucial issues of fairness and inclusion in speech recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
On the social bias of speech self-supervised models
Yi-Cheng Lin, Tzu-Quan Lin, Hsi-Che Lin, Andy T. Liu, Hung-yi Lee
0
0
Self-supervised learning (SSL) speech models have achieved remarkable performance in various tasks, yet the biased outcomes, especially affecting marginalized groups, raise significant concerns. Social bias refers to the phenomenon where algorithms potentially amplify disparate properties between social groups present in the data used for training. Bias in SSL models can perpetuate injustice by automating discriminatory patterns and reinforcing inequitable systems. This work reveals that prevalent SSL models inadvertently acquire biased associations. We probe how various factors, such as model architecture, size, and training methodologies, influence the propagation of social bias within these models. Finally, we explore the efficacy of debiasing SSL models through regularization techniques, specifically via model compression. Our findings reveal that employing techniques such as row-pruning and training wider, shallower models can effectively mitigate social bias within SSL model.
6/10/2024
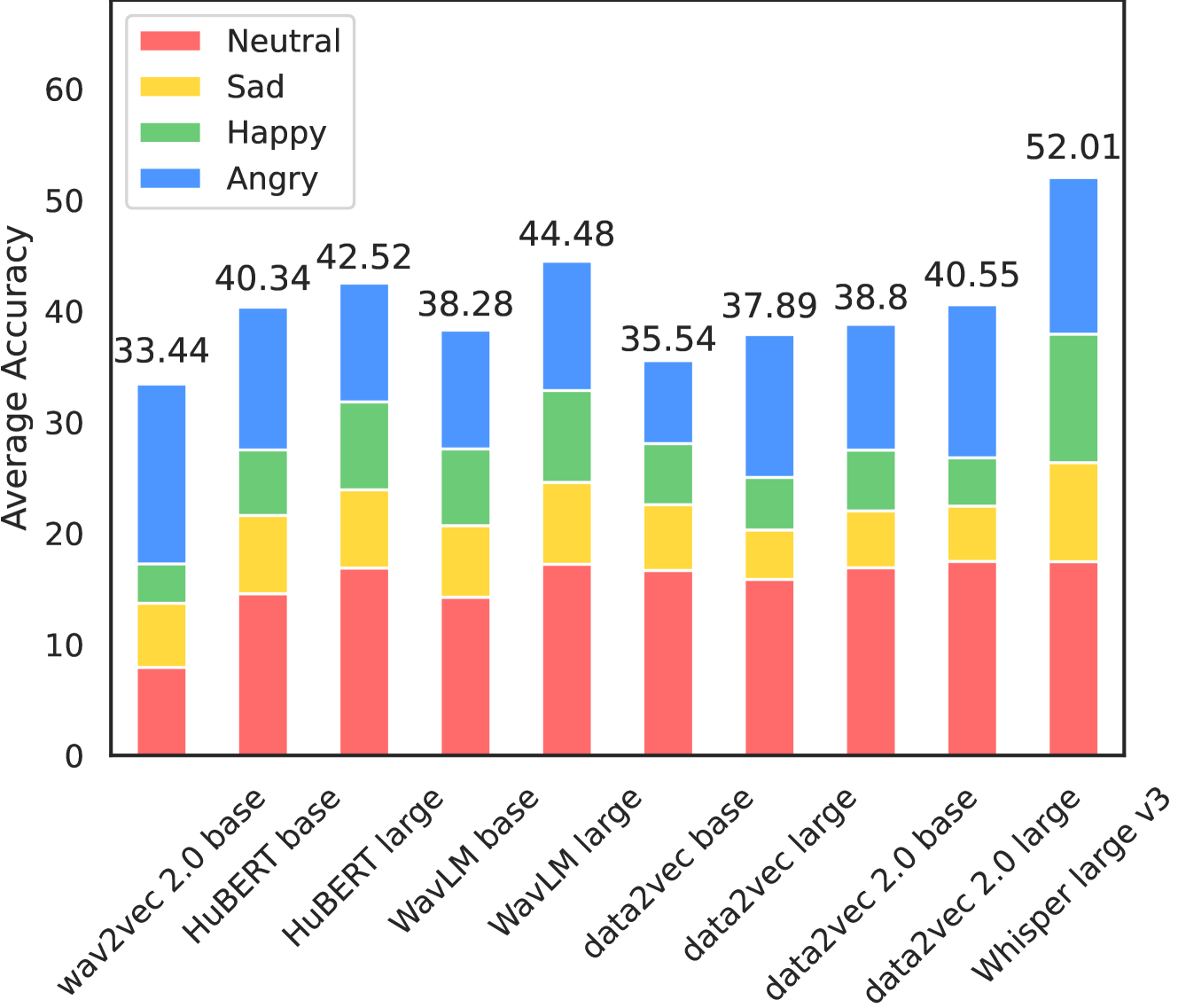
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Ziyang Ma, Mingjie Chen, Hezhao Zhang, Zhisheng Zheng, Wenxi Chen, Xiquan Li, Jiaxin Ye, Xie Chen, Thomas Hain
0
0
Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
6/12/2024

Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
0
0
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
6/13/2024
A Systematic Evaluation of Adversarial Attacks against Speech Emotion Recognition Models
Nicolas Facchinetti, Federico Simonetta, Stavros Ntalampiras
0
0
Speech emotion recognition (SER) is constantly gaining attention in recent years due to its potential applications in diverse fields and thanks to the possibility offered by deep learning technologies. However, recent studies have shown that deep learning models can be vulnerable to adversarial attacks. In this paper, we systematically assess this problem by examining the impact of various adversarial white-box and black-box attacks on different languages and genders within the context of SER. We first propose a suitable methodology for audio data processing, feature extraction, and CNN-LSTM architecture. The observed outcomes highlighted the significant vulnerability of CNN-LSTM models to adversarial examples (AEs). In fact, all the considered adversarial attacks are able to significantly reduce the performance of the constructed models. Furthermore, when assessing the efficacy of the attacks, minor differences were noted between the languages analyzed as well as between male and female speech. In summary, this work contributes to the understanding of the robustness of CNN-LSTM models, particularly in SER scenarios, and the impact of AEs. Interestingly, our findings serve as a baseline for a) developing more robust algorithms for SER, b) designing more effective attacks, c) investigating possible defenses, d) improved understanding of the vocal differences between different languages and genders, and e) overall, enhancing our comprehension of the SER task.
4/30/2024