Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
2406.07900
0
0

Abstract
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
Create account to get full access
Overview
• This paper explores the use of self-supervised multi-view contrastive learning to improve speech emotion recognition (SER) performance when training data is limited.
• The authors propose a novel self-supervised learning framework that leverages multiple acoustic and linguistic views of speech data to learn robust and discriminative representations.
• The framework is evaluated on several standard SER datasets, showing significant improvements over supervised baselines and other self-supervised approaches, especially in low-resource settings.
Plain English Explanation
Recognizing emotions in speech is an important task, with applications in areas like digital assistants, mental health monitoring, and customer service. However, building accurate speech emotion recognition (SER) models often requires large amounts of labeled training data, which can be costly and time-consuming to collect.
To address this challenge, the researchers in this paper investigated using a technique called self-supervised learning. In self-supervised learning, the model learns useful representations of the data by solving pretext tasks, without needing labeled data for the final task (in this case, emotion recognition). The key idea is to leverage the inherent structure and relationships within the speech data to learn features that are useful for the downstream SER task.
Specifically, the researchers proposed a multi-view contrastive learning approach. This means the model learned representations by "contrasting" different views or perspectives of the same speech data, such as the acoustic features and the linguistic content. By learning to distinguish between positive example pairs (different views of the same speech) and negative example pairs (views of different speech), the model can acquire robust and discriminative features for emotion recognition.
The authors evaluated their approach on several standard SER datasets and found that it outperformed supervised baselines and other self-supervised methods, especially when the amount of labeled training data was limited. This suggests that self-supervised multi-view contrastive learning can be a powerful technique for improving SER performance in scenarios where labeled data is scarce.
Technical Explanation
The authors' proposed framework, called Multi-View Contrastive Learning (MVCL), consists of two main components: a multi-view encoder and a contrastive learning objective.
The multi-view encoder takes two different views of the speech data as input, such as acoustic features and linguistic features. It then learns a shared representation that captures the common information across the views, as well as view-specific features that are unique to each modality.
The contrastive learning objective encourages the model to learn representations that are similar for positive example pairs (different views of the same speech) and dissimilar for negative example pairs (views of different speech). This is achieved by maximizing the similarity between the representations of positive pairs and minimizing the similarity of negative pairs.
The authors experiment with various acoustic and linguistic views, including mel-frequency cepstral coefficients (MFCCs), prosodic features, and text-based features derived from automatic speech recognition (ASR). They also explore different contrastive learning strategies, such as using in-batch negatives and memory banks to improve the quality of the negative samples.
The MVCL framework is evaluated on several standard SER datasets, including IEMOCAP, MSP-Podcast, and CREMA-D. The results show that MVCL consistently outperforms supervised baselines and other self-supervised approaches, especially in low-resource settings where the amount of labeled data is limited. For example, on the IEMOCAP dataset, MVCL achieves an accuracy of 72.1%, compared to 67.3% for the supervised baseline and 69.7% for a state-of-the-art self-supervised method.
Critical Analysis
The authors have provided a well-designed and comprehensive study on the use of self-supervised multi-view contrastive learning for speech emotion recognition. The proposed MVCL framework is theoretically grounded and the experimental evaluation is thorough, covering multiple datasets and configurations.
One potential limitation of the study is that it focuses on a relatively narrow set of acoustic and linguistic features. While the chosen features are well-established in the SER literature, it would be interesting to see how the framework performs with a wider range of input modalities, such as video or physiological signals. Additionally, the authors do not provide a detailed analysis of the learned representations and how they differ from supervised or other self-supervised approaches.
Another area for further research could be exploring the transferability of the learned representations to other speech-related tasks, such as speaker verification or expressive speech synthesis. Investigating the potential for SSL-enhanced or emotion-aware self-supervised representations to benefit these related tasks could further showcase the versatility and significance of the proposed approach.
Conclusion
This paper presents a compelling exploration of self-supervised multi-view contrastive learning for improving speech emotion recognition, particularly in low-resource settings. The proposed MVCL framework leverages the inherent structure and relationships within speech data to learn robust and discriminative representations, leading to significant performance gains over supervised baselines and other self-supervised methods.
The success of this approach highlights the potential of self-supervised learning techniques to enhance speech-related applications where labeled data is scarce. As the field of speech processing continues to evolve, innovative solutions like MVCL will likely play an important role in advancing the state of the art and expanding the practical applications of emotion-aware speech technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
0
0
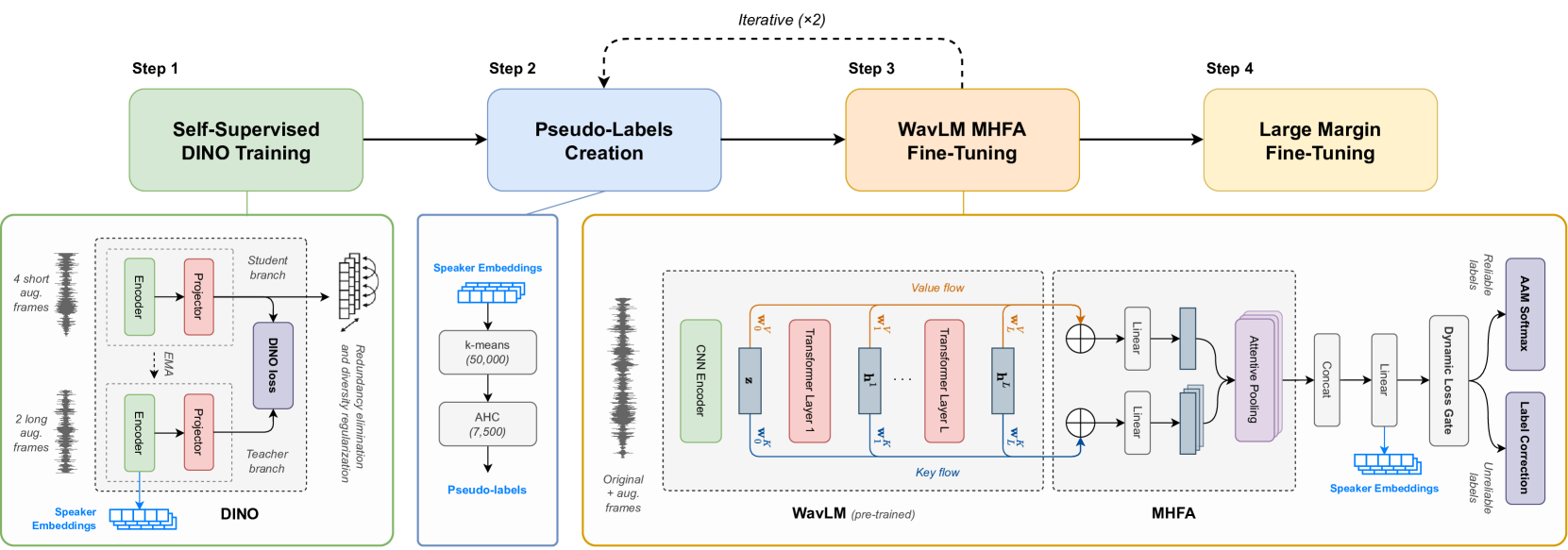
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
6/5/2024

Emotion-Aware Speech Self-Supervised Representation Learning with Intensity Knowledge
Rui Liu, Zening Ma
0
0
Speech Self-Supervised Learning (SSL) has demonstrated considerable efficacy in various downstream tasks. Nevertheless, prevailing self-supervised models often overlook the incorporation of emotion-related prior information, thereby neglecting the potential enhancement of emotion task comprehension through emotion prior knowledge in speech. In this paper, we propose an emotion-aware speech representation learning with intensity knowledge. Specifically, we extract frame-level emotion intensities using an established speech-emotion understanding model. Subsequently, we propose a novel emotional masking strategy (EMS) to incorporate emotion intensities into the masking process. We selected two representative models based on Transformer and CNN, namely MockingJay and Non-autoregressive Predictive Coding (NPC), and conducted experiments on IEMOCAP dataset. Experiments have demonstrated that the representations derived from our proposed method outperform the original model in SER task.
6/12/2024
🚀
Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
Po-chun Hsu, Ali Elkahky, Wei-Ning Hsu, Yossi Adi, Tu Anh Nguyen, Jade Copet, Emmanuel Dupoux, Hung-yi Lee, Abdelrahman Mohamed
0
0
Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
6/5/2024
🗣️
Boosting Multi-Speaker Expressive Speech Synthesis with Semi-supervised Contrastive Learning
Xinfa Zhu, Yuke Li, Yi Lei, Ning Jiang, Guoqing Zhao, Lei Xie
0
0
This paper aims to build a multi-speaker expressive TTS system, synthesizing a target speaker's speech with multiple styles and emotions. To this end, we propose a novel contrastive learning-based TTS approach to transfer style and emotion across speakers. Specifically, contrastive learning from different levels, i.e. utterance and category level, is leveraged to extract the disentangled style, emotion, and speaker representations from speech for style and emotion transfer. Furthermore, a semi-supervised training strategy is introduced to improve the data utilization efficiency by involving multi-domain data, including style-labeled data, emotion-labeled data, and abundant unlabeled data. To achieve expressive speech with diverse styles and emotions for a target speaker, the learned disentangled representations are integrated into an improved VITS model. Experiments on multi-domain data demonstrate the effectiveness of the proposed method.
4/26/2024