EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
2406.07162
0
0
Abstract
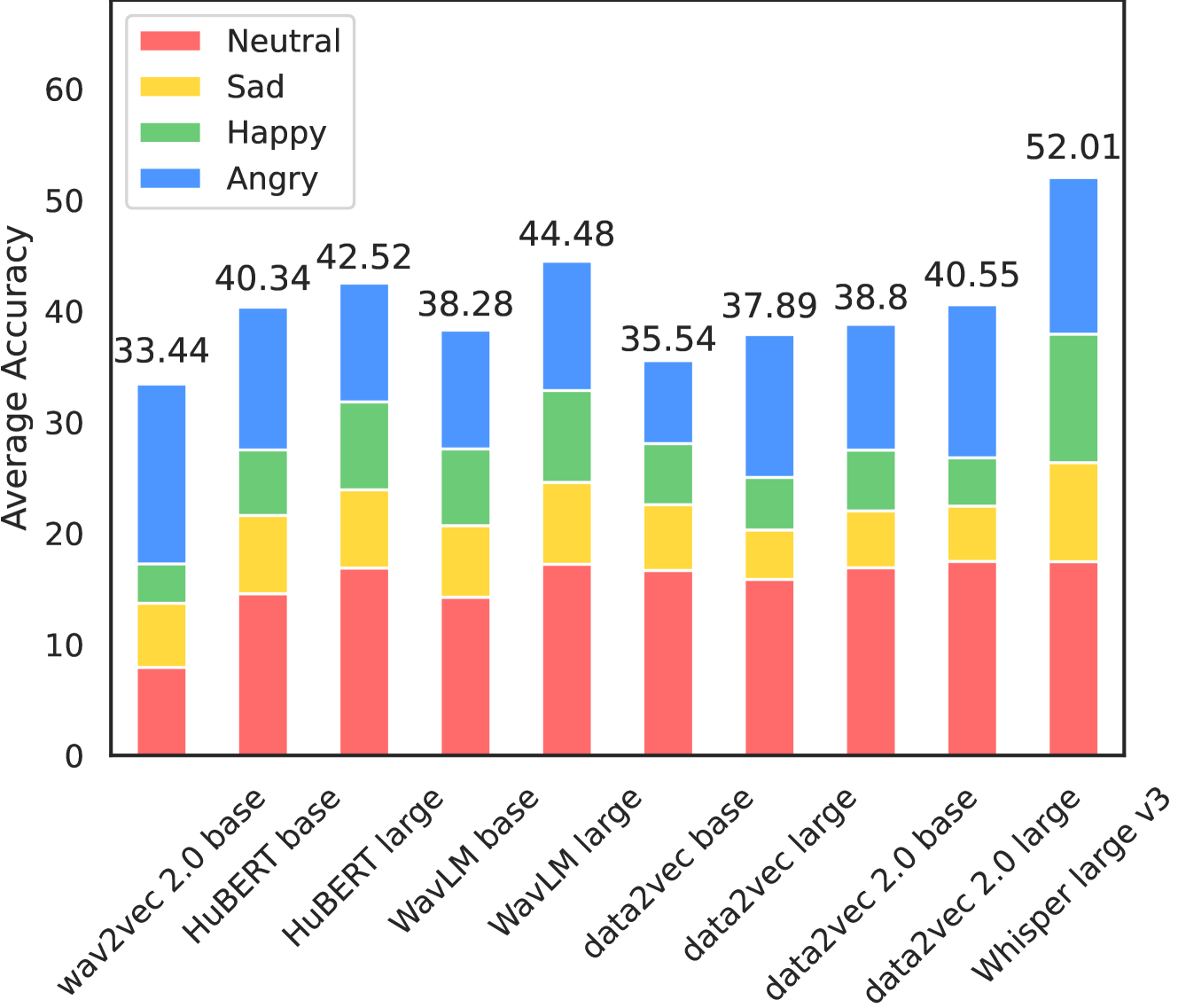
Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
Create account to get full access
Overview
- This paper introduces EmoBox, a multilingual, multi-corpus toolkit and benchmark for speech emotion recognition.
- EmoBox aims to provide a comprehensive and standardized framework for evaluating and developing speech emotion recognition models.
- The toolkit includes pre-processed data from multiple datasets, a set of baseline models, and evaluation metrics to facilitate research in this field.
Plain English Explanation
EmoBox is a toolkit that helps researchers and developers work on speech emotion recognition, which is the process of identifying the emotional state of a person based on their voice. This is an important technology with applications in areas like customer service, mental health monitoring, and human-computer interaction.
The key features of EmoBox are:
- Multilingual and Multi-corpus: EmoBox includes data from multiple languages and speech datasets, allowing researchers to develop and test models on diverse data.
- Standardized Benchmark: EmoBox provides a common set of baseline models, evaluation metrics, and data splits, ensuring fair and consistent comparisons between different approaches.
- Comprehensive Toolkit: The toolkit includes tools for data preprocessing, model training, and evaluation, making it easier for researchers to get started with speech emotion recognition research.
By providing a well-designed, open-source toolkit, the authors hope to accelerate progress in this field and enable more rigorous and reproducible research.
Technical Explanation
The paper introduces the EmoBox toolkit, which aims to address the lack of a comprehensive, multilingual, and standardized benchmark for speech emotion recognition. EmoBox includes preprocessed data from multiple datasets, including EmotionBias, MERBench, and MultiMicrophone, covering a range of languages, domains, and recording conditions.
The authors define a standardized data partitioning scheme and evaluation protocol, including train, validation, and test sets, as well as a set of baseline models, such as conventional machine learning and deep learning approaches. They also provide a set of evaluation metrics, including accuracy, F1-score, and confusion matrices, to enable comprehensive and comparable assessments of speech emotion recognition models.
To demonstrate the capabilities of EmoBox, the authors present a series of experiments, including cross-dataset and cross-lingual evaluations, to showcase the toolkit's versatility and the challenges of building robust and generalizable speech emotion recognition models.
Critical Analysis
The EmoBox toolkit addresses an important need in the field of speech emotion recognition by providing a standardized and comprehensive evaluation framework. By including data from multiple datasets and languages, the toolkit encourages the development of more robust and generalizable models, which is crucial for real-world deployment.
However, the authors acknowledge that the current version of EmoBox is limited to only a few datasets and languages. Expanding the toolkit to include a wider range of datasets, especially those covering more diverse cultures and languages, would further enhance its utility and enable more representative evaluations.
Additionally, the authors could explore the feasibility of incorporating EmoBench, a recently proposed benchmark for evaluating the emotional intelligence of large language models, into the EmoBox framework. This could provide valuable insights into the potential of these models for speech emotion recognition tasks.
Conclusion
The EmoBox toolkit represents a significant contribution to the field of speech emotion recognition by offering a standardized and comprehensive evaluation framework. By providing preprocessed data, baseline models, and evaluation metrics, the authors have created a valuable resource that can facilitate more rigorous and reproducible research in this area.
The versatility of EmoBox, as demonstrated by the cross-dataset and cross-lingual experiments, suggests that it has the potential to become a widely adopted tool in the speech emotion recognition community. As the field continues to evolve, the ongoing development and expansion of EmoBox will be crucial in driving progress and enabling the development of more robust and practical emotion recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

INTERSPEECH 2009 Emotion Challenge Revisited: Benchmarking 15 Years of Progress in Speech Emotion Recognition
Andreas Triantafyllopoulos, Anton Batliner, Simon Rampp, Manuel Milling, Bjorn Schuller
0
0
We revisit the INTERSPEECH 2009 Emotion Challenge -- the first ever speech emotion recognition (SER) challenge -- and evaluate a series of deep learning models that are representative of the major advances in SER research in the time since then. We start by training each model using a fixed set of hyperparameters, and further fine-tune the best-performing models of that initial setup with a grid search. Results are always reported on the official test set with a separate validation set only used for early stopping. Most models score below or close to the official baseline, while they marginally outperform the original challenge winners after hyperparameter tuning. Our work illustrates that, despite recent progress, FAU-AIBO remains a very challenging benchmark. An interesting corollary is that newer methods do not consistently outperform older ones, showing that progress towards `solving' SER is not necessarily monotonic.
6/11/2024
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Adham Ibrahim, Shady Shehata, Ajinkya Kulkarni, Mukhtar Mohamed, Muhammad Abdul-Mageed
0
0
Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
6/17/2024
🗣️
Emo-bias: A Large Scale Evaluation of Social Bias on Speech Emotion Recognition
Yi-Cheng Lin, Haibin Wu, Huang-Cheng Chou, Chi-Chun Lee, Hung-yi Lee
0
0
The rapid growth of Speech Emotion Recognition (SER) has diverse global applications, from improving human-computer interactions to aiding mental health diagnostics. However, SER models might contain social bias toward gender, leading to unfair outcomes. This study analyzes gender bias in SER models trained with Self-Supervised Learning (SSL) at scale, exploring factors influencing it. SSL-based SER models are chosen for their cutting-edge performance. Our research pioneering research gender bias in SER from both upstream model and data perspectives. Our findings reveal that females exhibit slightly higher overall SER performance than males. Modified CPC and XLS-R, two well-known SSL models, notably exhibit significant bias. Moreover, models trained with Mandarin datasets display a pronounced bias toward valence. Lastly, we find that gender-wise emotion distribution differences in training data significantly affect gender bias, while upstream model representation has a limited impact.
6/10/2024

Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
0
0
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
6/13/2024