EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions

4

Sign in to get full access
Overview
- The paper presents EMO, a model that generates expressive portrait videos from audio input, even with limited training data.
- EMO uses an audio-to-video diffusion model to produce talking head videos that capture the emotions expressed in the audio.
- The model can generate high-quality videos under "weak conditions," meaning it can work with limited training data and modest computational resources.
Plain English Explanation
The EMO model is designed to create animated portrait videos that match the emotional tone of an audio input, even when the training data is limited. Unlike many other talking head video models, EMO can produce realistic and expressive results without requiring large datasets or powerful hardware.
The key innovation of EMO is its use of a [object Object] - a type of machine learning model that generates new data by iteratively adding and then removing "noise" from an initial image. By training this diffusion model on a dataset of portrait images and corresponding audio, EMO learns to generate portrait videos that visually express the emotions conveyed in the audio.
One of the main advantages of EMO is that it can achieve high-quality results even when the training dataset is relatively small and the computational resources are modest. This makes the model more accessible and practical for a wider range of applications, compared to approaches that require extensive training data and hardware.
Technical Explanation
The EMO model uses a diffusion-based architecture to generate expressive portrait videos from audio inputs. Diffusion models work by gradually adding noise to an initial image and then learning to reverse this process, effectively generating new images that match the training data.
In the case of EMO, the model is trained on a dataset of portrait images and their corresponding audio recordings. The diffusion process is then used to learn the mapping between the audio features and the corresponding facial expressions and head movements in the portrait videos.
The paper describes the key components of the EMO model, including the audio encoder, the video generator, and the overall training and inference process. The authors also introduce several techniques to improve the model's performance, such as using a conditional diffusion model and incorporating adaptive instance normalization to better capture the emotional nuances in the generated videos.
Critical Analysis
The EMO paper presents a compelling approach to generating expressive portrait videos from audio inputs, with the key advantage of being able to achieve strong results under "weak conditions" - that is, with limited training data and modest computational resources.
One potential limitation of the research, as noted by the authors, is that the model's performance may be sensitive to the quality and diversity of the training data. If the dataset does not capture a wide range of emotional expressions or audio-visual correlations, the generated videos may not fully reflect the intended emotional tone.
Additionally, the paper acknowledges that the current version of EMO focuses on generating portrait videos of a single individual. Extending the model to handle multiple speakers or more complex scenes could be an area for future research.
Overall, the EMO model represents an interesting and practical approach to audio-driven portrait video generation, with the potential to enable a wide range of applications in areas such as virtual assistants, animation, and multimedia creation.
Conclusion
The EMO paper presents a novel diffusion-based model that can generate expressive portrait videos from audio inputs, even when working with limited training data and computational resources. By leveraging the flexibility and efficiency of diffusion models, the EMO approach offers a practical solution for creating emotionally engaging talking head videos that could be useful in various applications, from virtual assistants to animated content creation.
The research highlights the potential of diffusion models to tackle challenging audio-visual generation tasks, and the authors' focus on "weak conditions" suggests a path towards more accessible and widely applicable AI-powered video synthesis tools. As the field of generative AI continues to evolve, the insights and techniques showcased in the EMO paper could inspire further innovations in emotional, audio-driven video generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
4
EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
Linrui Tian, Qi Wang, Bang Zhang, Liefeng Bo
In this work, we tackle the challenge of enhancing the realism and expressiveness in talking head video generation by focusing on the dynamic and nuanced relationship between audio cues and facial movements. We identify the limitations of traditional techniques that often fail to capture the full spectrum of human expressions and the uniqueness of individual facial styles. To address these issues, we propose EMO, a novel framework that utilizes a direct audio-to-video synthesis approach, bypassing the need for intermediate 3D models or facial landmarks. Our method ensures seamless frame transitions and consistent identity preservation throughout the video, resulting in highly expressive and lifelike animations. Experimental results demonsrate that EMO is able to produce not only convincing speaking videos but also singing videos in various styles, significantly outperforming existing state-of-the-art methodologies in terms of expressiveness and realism.
Read more8/7/2024

0
EMOdiffhead: Continuously Emotional Control in Talking Head Generation via Diffusion
Jian Zhang, Weijian Mai, Zhijun Zhang
The task of audio-driven portrait animation involves generating a talking head video using an identity image and an audio track of speech. While many existing approaches focus on lip synchronization and video quality, few tackle the challenge of generating emotion-driven talking head videos. The ability to control and edit emotions is essential for producing expressive and realistic animations. In response to this challenge, we propose EMOdiffhead, a novel method for emotional talking head video generation that not only enables fine-grained control of emotion categories and intensities but also enables one-shot generation. Given the FLAME 3D model's linearity in expression modeling, we utilize the DECA method to extract expression vectors, that are combined with audio to guide a diffusion model in generating videos with precise lip synchronization and rich emotional expressiveness. This approach not only enables the learning of rich facial information from emotion-irrelevant data but also facilitates the generation of emotional videos. It effectively overcomes the limitations of emotional data, such as the lack of diversity in facial and background information, and addresses the absence of emotional details in emotion-irrelevant data. Extensive experiments and user studies demonstrate that our approach achieves state-of-the-art performance compared to other emotion portrait animation methods.
Read more9/12/2024

0
EmoFace: Audio-driven Emotional 3D Face Animation
Chang Liu, Qunfen Lin, Zijiao Zeng, Ye Pan
Audio-driven emotional 3D face animation aims to generate emotionally expressive talking heads with synchronized lip movements. However, previous research has often overlooked the influence of diverse emotions on facial expressions or proved unsuitable for driving MetaHuman models. In response to this deficiency, we introduce EmoFace, a novel audio-driven methodology for creating facial animations with vivid emotional dynamics. Our approach can generate facial expressions with multiple emotions, and has the ability to generate random yet natural blinks and eye movements, while maintaining accurate lip synchronization. We propose independent speech encoders and emotion encoders to learn the relationship between audio, emotion and corresponding facial controller rigs, and finally map into the sequence of controller values. Additionally, we introduce two post-processing techniques dedicated to enhancing the authenticity of the animation, particularly in blinks and eye movements. Furthermore, recognizing the scarcity of emotional audio-visual data suitable for MetaHuman model manipulation, we contribute an emotional audio-visual dataset and derive control parameters for each frames. Our proposed methodology can be applied in producing dialogues animations of non-playable characters (NPCs) in video games, and driving avatars in virtual reality environments. Our further quantitative and qualitative experiments, as well as an user study comparing with existing researches show that our approach demonstrates superior results in driving 3D facial models. The code and sample data are available at https://github.com/SJTU-Lucy/EmoFace.
Read more7/18/2024
0
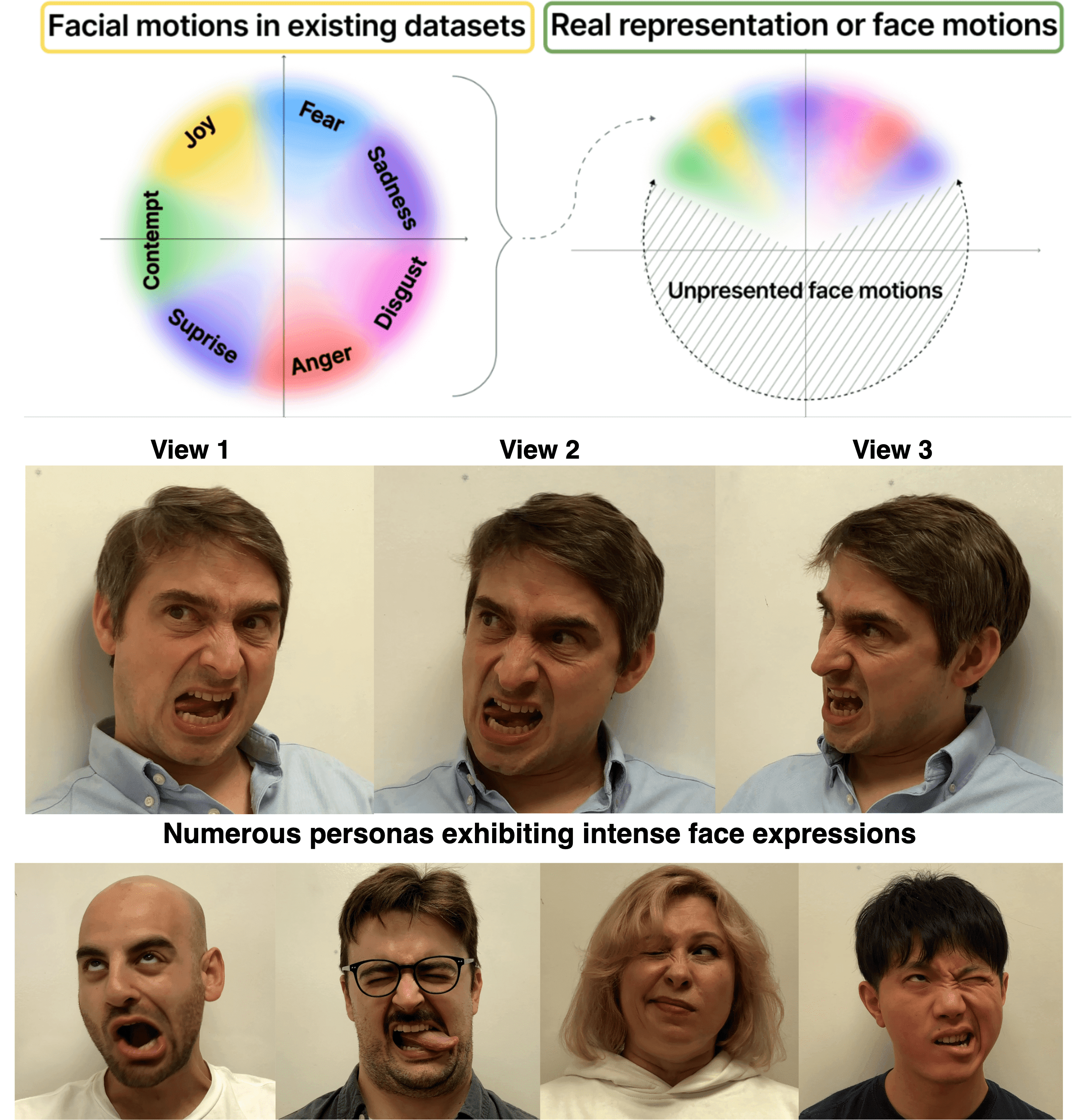
EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos Vougioukas, Zoe Landgraf, Stavros Petridis, Maja Pantic
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model's capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
Read more5/1/2024