EmoBench: Evaluating the Emotional Intelligence of Large Language Models
2402.12071
0
0
💬
Abstract
Recent advances in Large Language Models (LLMs) have highlighted the need for robust, comprehensive, and challenging benchmarks. Yet, research on evaluating their Emotional Intelligence (EI) is considerably limited. Existing benchmarks have two major shortcomings: first, they mainly focus on emotion recognition, neglecting essential EI capabilities such as emotion regulation and thought facilitation through emotion understanding; second, they are primarily constructed from existing datasets, which include frequent patterns, explicit information, and annotation errors, leading to unreliable evaluation. We propose EmoBench, a benchmark that draws upon established psychological theories and proposes a comprehensive definition for machine EI, including Emotional Understanding and Emotional Application. EmoBench includes a set of 400 hand-crafted questions in English and Chinese, which are meticulously designed to require thorough reasoning and understanding. Our findings reveal a considerable gap between the EI of existing LLMs and the average human, highlighting a promising direction for future research. Our code and data are publicly available at https://github.com/Sahandfer/EmoBench.
Create account to get full access
Overview
- Introduces the need for robust and comprehensive benchmarks to evaluate the Emotional Intelligence (EI) of Large Language Models (LLMs)
- Highlights the limitations of existing benchmarks, which focus mainly on emotion recognition and use datasets with frequent patterns, explicit information, and annotation errors
- Proposes EmoBench, a new benchmark that draws from psychological theories and defines a comprehensive view of machine EI, including Emotional Understanding and Emotional Application
- EmoBench includes 400 hand-crafted questions in English and Chinese designed to require thorough reasoning and understanding
- Findings reveal a significant gap between the EI of existing LLMs and the average human, suggesting a promising direction for future research
Plain English Explanation
As large language models have become more advanced, there is a growing need for robust and comprehensive benchmarks to evaluate their capabilities, particularly in the realm of emotional intelligence. However, current benchmarks have some significant limitations.
First, they tend to focus mainly on emotion recognition, neglecting other crucial aspects of emotional intelligence, such as emotion regulation and the ability to facilitate thought through emotion understanding. Second, these benchmarks are often built using existing datasets, which can contain frequent patterns, explicit information, and even annotation errors, leading to unreliable evaluations.
To address these shortcomings, the researchers proposed a new benchmark called EmoBench. EmoBench draws on established psychological theories to define a comprehensive view of machine emotional intelligence, including both Emotional Understanding and Emotional Application. The benchmark includes 400 carefully crafted questions in English and Chinese that require in-depth reasoning and understanding to answer correctly.
The researchers' findings reveal a substantial gap between the emotional intelligence of existing large language models and the average human. This suggests that there is still significant room for improvement in this critical area of AI development, which could have important implications for the ethical and social integration of these models into our lives.
Technical Explanation
The paper introduces EmoBench, a new benchmark for evaluating the Emotional Intelligence (EI) of Large Language Models (LLMs). Existing benchmarks for assessing LLM EI have two main limitations:
- They primarily focus on emotion recognition, neglecting other essential EI capabilities such as emotion regulation and the ability to facilitate thought through emotion understanding.
- They are primarily constructed from existing datasets, which often contain frequent patterns, explicit information, and annotation errors, leading to unreliable evaluations.
To address these shortcomings, the researchers propose EmoBench, a benchmark that draws upon established psychological theories to define a comprehensive view of machine EI. EmoBench includes two key components: Emotional Understanding and Emotional Application.
The Emotional Understanding component evaluates an LLM's ability to recognize, reason about, and understand emotions. The Emotional Application component assesses the model's capacity to apply emotional knowledge to facilitate thought and decision-making.
EmoBench includes a set of 400 hand-crafted questions in English and Chinese, designed to require thorough reasoning and understanding from the LLMs being evaluated. The questions cover a wide range of emotional scenarios and are carefully curated to avoid common dataset biases.
The researchers evaluated several state-of-the-art LLMs on EmoBench and found a considerable gap between the models' EI and the average human performance. This highlights the need for continued research and development in the area of emotional intelligence in large language models, which could have important implications for the ethical and social integration of these models into our lives.
Critical Analysis
The EmoBench benchmark proposed in this paper addresses some important limitations of existing approaches for evaluating the Emotional Intelligence (EI) of Large Language Models (LLMs). By drawing on established psychological theories and defining a more comprehensive view of machine EI, the researchers have created a more robust and challenging evaluation tool.
One potential limitation of the EmoBench approach is the reliance on hand-crafted questions. While this helps to avoid some of the biases and errors present in existing datasets, it may also introduce new biases or limitations in the types of emotional scenarios and reasoning that the benchmark can capture. It would be interesting to see how EmoBench could be expanded or combined with other approaches, such as MoralBench, to provide an even more comprehensive assessment of LLM EI and ethical reasoning.
Additionally, the current evaluation of LLMs on EmoBench suggests a significant gap between machine and human EI. However, it is not clear how this gap might change as LLMs continue to improve or as the benchmark itself evolves. Further research is needed to understand the trajectory of LLM EI development and the potential implications for the ethical and social integration of these models.
Overall, the EmoBench benchmark represents an important step forward in the evaluation of emotional intelligence in large language models. By highlighting the limitations of existing approaches and proposing a more robust and comprehensive alternative, this research paves the way for continued advancements in this critical area of AI development.
Conclusion
The paper introduces EmoBench, a new benchmark for evaluating the Emotional Intelligence (EI) of Large Language Models (LLMs). EmoBench addresses the limitations of existing benchmarks by drawing on established psychological theories to define a comprehensive view of machine EI, including both Emotional Understanding and Emotional Application.
The benchmark includes 400 hand-crafted questions in English and Chinese that are designed to require thorough reasoning and understanding from the LLMs being evaluated. The researchers' findings reveal a significant gap between the EI of existing LLMs and the average human, highlighting the need for continued research and development in this area.
This research represents an important step forward in the effort to create robust and comprehensive benchmarks for assessing the emotional intelligence of large language models. As these models continue to advance and become increasingly integrated into our lives, the ability to accurately evaluate their emotional capabilities will be crucial for ensuring their ethical and responsible deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
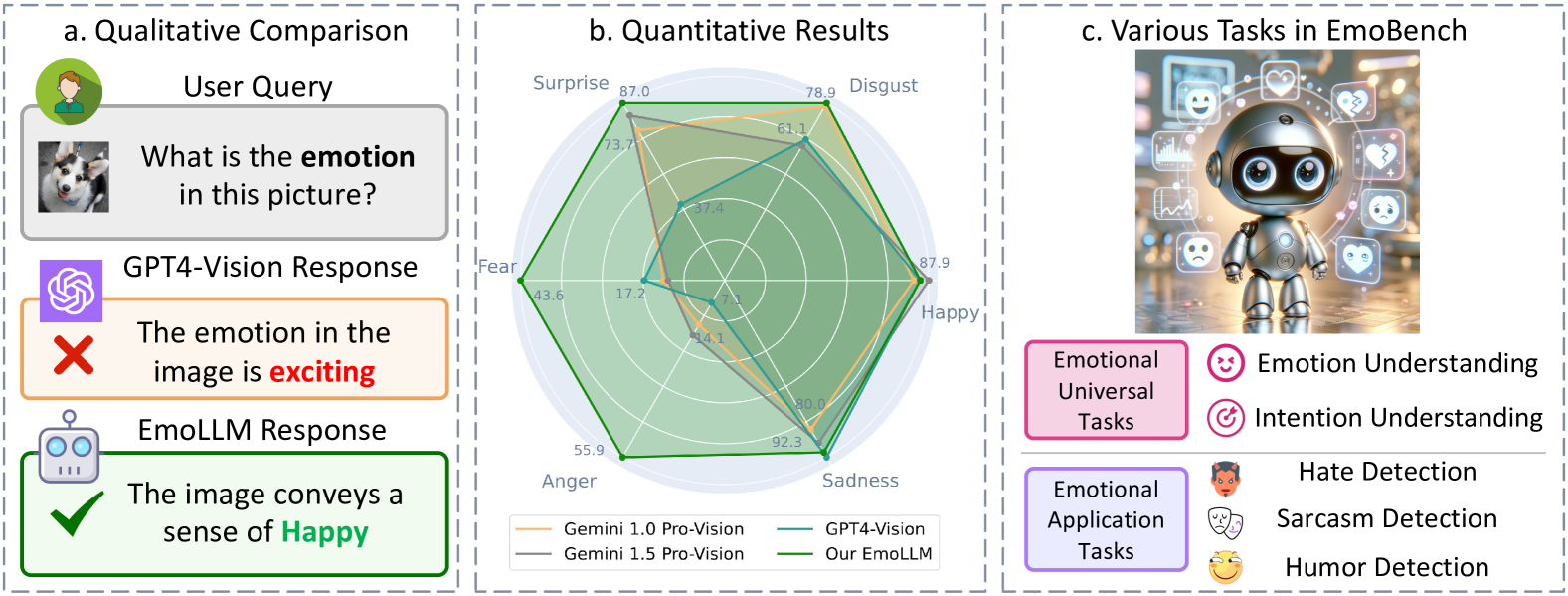
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
0
0
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
6/26/2024
💬
Both Matter: Enhancing the Emotional Intelligence of Large Language Models without Compromising the General Intelligence
Weixiang Zhao, Zhuojun Li, Shilong Wang, Yang Wang, Yulin Hu, Yanyan Zhao, Chen Wei, Bing Qin
0
0
Emotional Intelligence (EI), consisting of emotion perception, emotion cognition and emotion expression, plays the critical roles in improving user interaction experience for the current large language model (LLM) based conversational general AI assistants. Previous works mainly focus on raising the emotion perception ability of them via naive fine-tuning on EI-related classification or regression tasks. However, this leads to the incomplete enhancement of EI and catastrophic forgetting of the general intelligence (GI). To this end, we first introduce textsc{EiBench}, a large-scale collection of EI-related tasks in the text-to-text formation with task instructions that covers all three aspects of EI, which lays a solid foundation for the comprehensive EI enhancement of LLMs. Then a novel underline{textbf{Mo}}dular underline{textbf{E}}motional underline{textbf{I}}ntelligence enhancement method (textbf{MoEI}), consisting of Modular Parameter Expansion and intra-inter modulation, is proposed to comprehensively enhance the EI of LLMs without compromise their GI. Extensive experiments on two representative LLM-based assistants, Flan-T5 and LLaMA-2-Chat, demonstrate the effectiveness of MoEI to improving EI while maintain GI.
6/13/2024
💬
GIEBench: Towards Holistic Evaluation of Group Indentity-based Empathy for Large Language Models
Leyan Wang, Yonggang Jin, Tianhao Shen, Tianyu Zheng, Xinrun Du, Chenchen Zhang, Wenhao Huang, Jiaheng Liu, Shi Wang, Ge Zhang, Liuyu Xiang, Zhaofeng He
0
0
As large language models (LLMs) continue to develop and gain widespread application, the ability of LLMs to exhibit empathy towards diverse group identities and understand their perspectives is increasingly recognized as critical. Most existing benchmarks for empathy evaluation of LLMs focus primarily on universal human emotions, such as sadness and pain, often overlooking the context of individuals' group identities. To address this gap, we introduce GIEBench, a comprehensive benchmark that includes 11 identity dimensions, covering 97 group identities with a total of 999 single-choice questions related to specific group identities. GIEBench is designed to evaluate the empathy of LLMs when presented with specific group identities such as gender, age, occupation, and race, emphasizing their ability to respond from the standpoint of the identified group. This supports the ongoing development of empathetic LLM applications tailored to users with different identities. Our evaluation of 23 LLMs revealed that while these LLMs understand different identity standpoints, they fail to consistently exhibit equal empathy across these identities without explicit instructions to adopt those perspectives. This highlights the need for improved alignment of LLMs with diverse values to better accommodate the multifaceted nature of human identities. Our datasets are available at https://github.com/GIEBench/GIEBench.
6/26/2024
💬
EmoLLMs: A Series of Emotional Large Language Models and Annotation Tools for Comprehensive Affective Analysis
Zhiwei Liu, Kailai Yang, Tianlin Zhang, Qianqian Xie, Sophia Ananiadou
0
0
Sentiment analysis and emotion detection are important research topics in natural language processing (NLP) and benefit many downstream tasks. With the widespread application of LLMs, researchers have started exploring the application of LLMs based on instruction-tuning in the field of sentiment analysis. However, these models only focus on single aspects of affective classification tasks (e.g. sentimental polarity or categorical emotions), and overlook the regression tasks (e.g. sentiment strength or emotion intensity), which leads to poor performance in downstream tasks. The main reason is the lack of comprehensive affective instruction tuning datasets and evaluation benchmarks, which cover various affective classification and regression tasks. Moreover, although emotional information is useful for downstream tasks, existing downstream datasets lack high-quality and comprehensive affective annotations. In this paper, we propose EmoLLMs, the first series of open-sourced instruction-following LLMs for comprehensive affective analysis based on fine-tuning various LLMs with instruction data, the first multi-task affective analysis instruction dataset (AAID) with 234K data samples based on various classification and regression tasks to support LLM instruction tuning, and a comprehensive affective evaluation benchmark (AEB) with 14 tasks from various sources and domains to test the generalization ability of LLMs. We propose a series of EmoLLMs by fine-tuning LLMs with AAID to solve various affective instruction tasks. We compare our model with a variety of LLMs on AEB, where our models outperform all other open-sourced LLMs, and surpass ChatGPT and GPT-4 in most tasks, which shows that the series of EmoLLMs achieve the ChatGPT-level and GPT-4-level generalization capabilities on affective analysis tasks, and demonstrates our models can be used as affective annotation tools.
6/19/2024