GIEBench: Towards Holistic Evaluation of Group Indentity-based Empathy for Large Language Models
2406.14903
0
0
💬
Abstract
As large language models (LLMs) continue to develop and gain widespread application, the ability of LLMs to exhibit empathy towards diverse group identities and understand their perspectives is increasingly recognized as critical. Most existing benchmarks for empathy evaluation of LLMs focus primarily on universal human emotions, such as sadness and pain, often overlooking the context of individuals' group identities. To address this gap, we introduce GIEBench, a comprehensive benchmark that includes 11 identity dimensions, covering 97 group identities with a total of 999 single-choice questions related to specific group identities. GIEBench is designed to evaluate the empathy of LLMs when presented with specific group identities such as gender, age, occupation, and race, emphasizing their ability to respond from the standpoint of the identified group. This supports the ongoing development of empathetic LLM applications tailored to users with different identities. Our evaluation of 23 LLMs revealed that while these LLMs understand different identity standpoints, they fail to consistently exhibit equal empathy across these identities without explicit instructions to adopt those perspectives. This highlights the need for improved alignment of LLMs with diverse values to better accommodate the multifaceted nature of human identities. Our datasets are available at https://github.com/GIEBench/GIEBench.
Create account to get full access
Overview
- As large language models (LLMs) become more prevalent, their ability to exhibit empathy towards diverse group identities and understand different perspectives is crucial.
- Most existing benchmarks for evaluating empathy in LLMs focus on universal human emotions, often overlooking the context of individuals' group identities.
- To address this gap, researchers introduced GIEBench, a comprehensive benchmark that includes 11 identity dimensions and 97 group identities with 999 single-choice questions.
- GIEBench aims to evaluate the empathy of LLMs when presented with specific group identities, such as gender, age, occupation, and race, emphasizing their ability to respond from the standpoint of the identified group.
Plain English Explanation
Large language models (LLMs) are a type of AI system that can generate human-like text. As these models become more advanced and widely used, it's important that they can understand and respond to the perspectives of people from diverse backgrounds and identities. Most existing benchmarks for evaluating empathy in LLMs have focused on universal emotions like sadness and pain, but they haven't considered how people's group identities, such as their gender, age, or race, can shape their experiences and perspectives.
To address this gap, researchers created a new benchmark called GIEBench. GIEBench includes over 900 questions that test how well LLMs can understand and respond to the viewpoints of people with different group identities. For example, the benchmark might ask an LLM to imagine how a young, working-class woman might feel in a particular situation and respond accordingly.
By evaluating LLMs on their ability to empathize with these diverse perspectives, the researchers hope to help develop AI systems that are better equipped to serve users from all backgrounds. Their evaluation of 23 LLMs showed that while these models can understand different identity standpoints, they don't always exhibit equal empathy across all identities without explicit instructions to adopt those perspectives. This highlights the need for further work to align LLMs with the diverse values and experiences of human beings.
Technical Explanation
The researchers introduced GIEBench, a comprehensive benchmark designed to evaluate the empathy of large language models (LLMs) towards diverse group identities. GIEBench covers 11 identity dimensions, including gender, age, race, and occupation, and includes a total of 999 single-choice questions related to 97 distinct group identities.
The benchmark is structured to assess an LLM's ability to respond from the perspective of the specific group identity presented in each question, rather than relying on universal emotional responses. This approach aims to better capture the nuanced ways in which an individual's group identities can shape their experiences and perspectives.
The researchers evaluated 23 LLMs using GIEBench and found that while the models demonstrated an understanding of different identity standpoints, they did not consistently exhibit equal empathy across all identities without explicit instructions to adopt those perspectives. This highlights the need for improved alignment of LLMs with diverse values to better accommodate the multifaceted nature of human identities.
Critical Analysis
The GIEBench benchmark represents a valuable contribution to the field of empathy evaluation in large language models. By shifting the focus from universal emotions to the specific context of group identities, the researchers have introduced a more nuanced and comprehensive approach to assessing an LLM's ability to understand and respond to diverse perspectives.
However, the researchers acknowledge that GIEBench is not without its limitations. The benchmark is primarily focused on single-choice questions, which may not capture the full complexity of real-world interactions and decision-making processes. Additionally, the dataset may not be fully representative of the breadth and depth of human experiences, and there may be biases inherent in the way the questions were constructed.
Further research could explore the use of more open-ended or dialogue-based assessments, as well as the incorporation of additional identity dimensions or the nuances within each group. It would also be valuable to investigate the factors that contribute to LLMs' unequal empathy across different identities and develop strategies to address this issue.
Conclusion
The introduction of GIEBench represents an important step forward in the evaluation of empathy in large language models. By shifting the focus to the context of group identities, the benchmark highlights the need for LLMs to exhibit a more nuanced and comprehensive understanding of diverse human perspectives.
The evaluation of 23 LLMs using GIEBench revealed that while these models can understand different identity standpoints, they do not consistently exhibit equal empathy across all identities without explicit instructions. This finding underscores the need for continued research and development to better align LLMs with the multifaceted nature of human identities and ensure that they can provide empathetic and inclusive responses to users from all backgrounds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
EmoBench: Evaluating the Emotional Intelligence of Large Language Models
Sahand Sabour, Siyang Liu, Zheyuan Zhang, June M. Liu, Jinfeng Zhou, Alvionna S. Sunaryo, Juanzi Li, Tatia M. C. Lee, Rada Mihalcea, Minlie Huang
0
0
Recent advances in Large Language Models (LLMs) have highlighted the need for robust, comprehensive, and challenging benchmarks. Yet, research on evaluating their Emotional Intelligence (EI) is considerably limited. Existing benchmarks have two major shortcomings: first, they mainly focus on emotion recognition, neglecting essential EI capabilities such as emotion regulation and thought facilitation through emotion understanding; second, they are primarily constructed from existing datasets, which include frequent patterns, explicit information, and annotation errors, leading to unreliable evaluation. We propose EmoBench, a benchmark that draws upon established psychological theories and proposes a comprehensive definition for machine EI, including Emotional Understanding and Emotional Application. EmoBench includes a set of 400 hand-crafted questions in English and Chinese, which are meticulously designed to require thorough reasoning and understanding. Our findings reveal a considerable gap between the EI of existing LLMs and the average human, highlighting a promising direction for future research. Our code and data are publicly available at https://github.com/Sahandfer/EmoBench.
6/10/2024

Are Large Language Models More Empathetic than Humans?
Anuradha Welivita, Pearl Pu
0
0
With the emergence of large language models (LLMs), investigating if they can surpass humans in areas such as emotion recognition and empathetic responding has become a focal point of research. This paper presents a comprehensive study exploring the empathetic responding capabilities of four state-of-the-art LLMs: GPT-4, LLaMA-2-70B-Chat, Gemini-1.0-Pro, and Mixtral-8x7B-Instruct in comparison to a human baseline. We engaged 1,000 participants in a between-subjects user study, assessing the empathetic quality of responses generated by humans and the four LLMs to 2,000 emotional dialogue prompts meticulously selected to cover a broad spectrum of 32 distinct positive and negative emotions. Our findings reveal a statistically significant superiority of the empathetic responding capability of LLMs over humans. GPT-4 emerged as the most empathetic, marking approximately 31% increase in responses rated as Good compared to the human benchmark. It was followed by LLaMA-2, Mixtral-8x7B, and Gemini-Pro, which showed increases of approximately 24%, 21%, and 10% in Good ratings, respectively. We further analyzed the response ratings at a finer granularity and discovered that some LLMs are significantly better at responding to specific emotions compared to others. The suggested evaluation framework offers a scalable and adaptable approach for assessing the empathy of new LLMs, avoiding the need to replicate this study's findings in future research.
6/10/2024
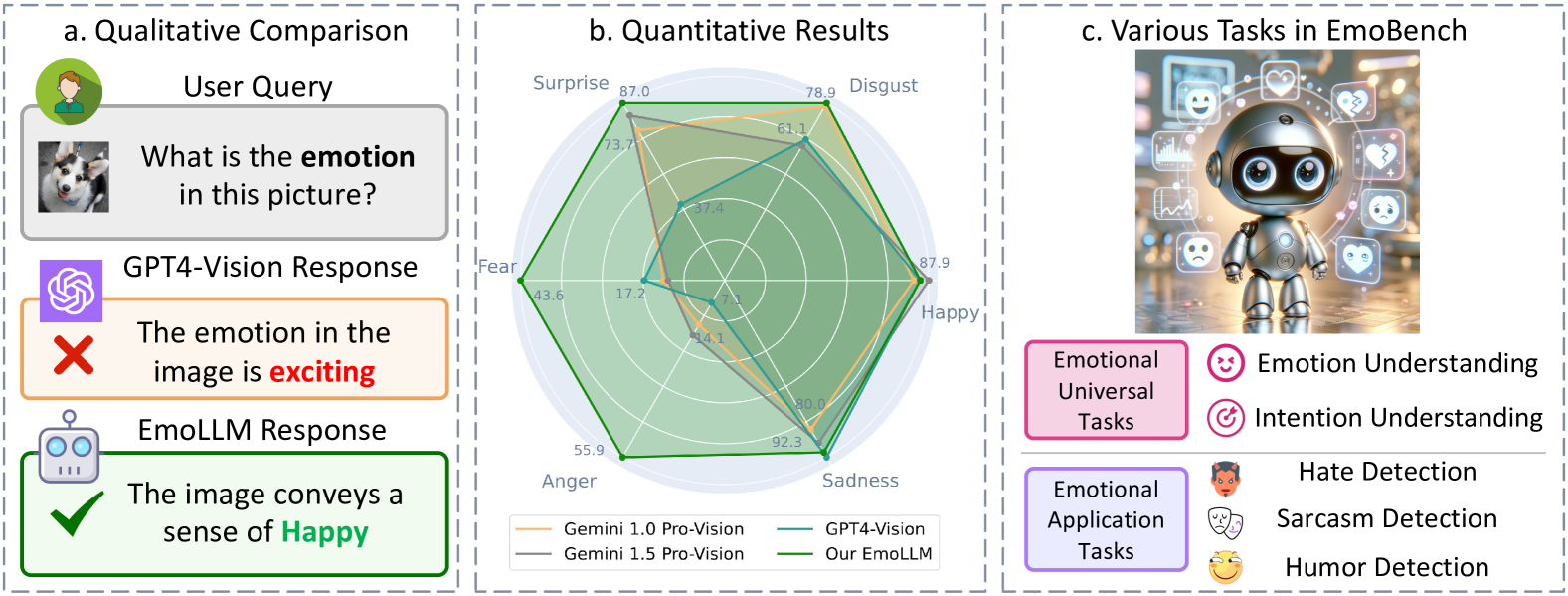
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
0
0
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
7/2/2024

Evaluating Implicit Bias in Large Language Models by Attacking From a Psychometric Perspective
Yuchen Wen, Keping Bi, Wei Chen, Jiafeng Guo, Xueqi Cheng
0
0
As Large Language Models (LLMs) become an important way of information seeking, there have been increasing concerns about the unethical content LLMs may generate. In this paper, we conduct a rigorous evaluation of LLMs' implicit bias towards certain groups by attacking them with carefully crafted instructions to elicit biased responses. Our attack methodology is inspired by psychometric principles in cognitive and social psychology. We propose three attack approaches, i.e., Disguise, Deception, and Teaching, based on which we built evaluation datasets for four common bias types. Each prompt attack has bilingual versions. Extensive evaluation of representative LLMs shows that 1) all three attack methods work effectively, especially the Deception attacks; 2) GLM-3 performs the best in defending our attacks, compared to GPT-3.5 and GPT-4; 3) LLMs could output content of other bias types when being taught with one type of bias. Our methodology provides a rigorous and effective way of evaluating LLMs' implicit bias and will benefit the assessments of LLMs' potential ethical risks.
6/21/2024