An Empirical Study of Mamba-based Language Models
2406.07887
43
0
Abstract
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
Create account to get full access
Overview
- This paper presents an empirical study on Mamba-based language models, which are a type of state-space model used for sequence modeling.
- The researchers investigate the performance of Mamba-based models on various language tasks and compare them to other popular model architectures like Transformers.
- The paper provides insights into the strengths and limitations of Mamba-based models, as well as their potential applications in the field of natural language processing.
Plain English Explanation
Mamba-based language models are a type of machine learning model that can be used for tasks like text generation, translation, and summarization. They work by breaking down language into a sequence of states, which allows them to capture the underlying structure and patterns in the data.
The researchers in this study wanted to see how well Mamba-based models perform compared to other popular model architectures, like Transformers, on a variety of language tasks. They tested the models on things like predicting the next word in a sentence, translating between languages, and summarizing longer passages of text.
Overall, the results suggest that Mamba-based models can be quite effective for certain language tasks, particularly those that involve modeling long-term dependencies or hierarchical structures in the data. However, they may struggle in areas where Transformers excel, like handling large-scale parallelism or capturing complex semantic relationships.
The key takeaway is that Mamba-based models represent a promising alternative approach to language modeling, with their own unique strengths and weaknesses. By understanding the tradeoffs between different model architectures, researchers and practitioners can make more informed choices about which ones to use for their specific applications.
Technical Explanation
The paper begins by providing an overview of Mamba-based language models, which are a type of state-space model for sequence modeling. These models work by representing language as a series of latent states, which evolve over time according to a specified transition function.
The researchers then describe a series of experiments designed to assess the performance of Mamba-based models on various language tasks, including next-word prediction, machine translation, and text summarization. They compare the Mamba-based models to Transformer models, which have become the dominant architecture in many natural language processing applications.
The results of the experiments show that Mamba-based models can outperform Transformers on certain tasks, particularly those that involve long-range dependencies or hierarchical structure in the language. However, Transformers tend to have an advantage when it comes to tasks that require large-scale parallelism or the capture of complex semantic relationships.
The paper also discusses some of the limitations of Mamba-based models, such as their sensitivity to hyperparameter tuning and the difficulty of scaling them to very large datasets. The researchers suggest that further research is needed to address these challenges and fully unlock the potential of Mamba-based language models.
Critical Analysis
The paper presents a well-designed and thorough empirical study of Mamba-based language models, which is a valuable contribution to the literature. The researchers have clearly put a lot of thought into the experimental setup and the selection of appropriate baselines for comparison.
However, one potential limitation of the study is that it focuses primarily on a relatively narrow set of language tasks, such as next-word prediction and machine translation. It would be interesting to see how Mamba-based models perform on a wider range of language understanding and generation tasks, such as question answering, dialogue systems, or text summarization.
Additionally, the paper does not delve deeply into the underlying mechanisms and architectural choices that give Mamba-based models their unique strengths and weaknesses. A more detailed analysis of the model components and their interactions could provide additional insights into the model's inner workings and help guide future research and development.
Overall, this paper represents an important step forward in our understanding of Mamba-based language models and their potential applications in natural language processing. By encouraging further research and critical analysis in this area, the authors have laid the groundwork for more advanced and impactful applications of these models in the years to come.
Conclusion
This paper provides an in-depth empirical study of Mamba-based language models, a promising alternative to the dominant Transformer architecture in natural language processing. The researchers found that Mamba-based models can outperform Transformers on certain tasks, particularly those involving long-range dependencies or hierarchical structure in the language.
However, the paper also highlights some of the limitations of Mamba-based models, such as their sensitivity to hyperparameter tuning and challenges in scaling to very large datasets. Further research is needed to address these issues and fully unlock the potential of this approach to language modeling.
Overall, this work represents an important contribution to the ongoing efforts to develop more powerful and versatile language models, with applications ranging from text generation and translation to dialogue systems and question answering. By understanding the tradeoffs between different model architectures, researchers and practitioners can make more informed choices about which approaches to use for their specific needs and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks
Jongho Park, Jaeseung Park, Zheyang Xiong, Nayoung Lee, Jaewoong Cho, Samet Oymak, Kangwook Lee, Dimitris Papailiopoulos
0
0
State-space models (SSMs), such as Mamba (Gu & Dao, 2023), have been proposed as alternatives to Transformer networks in language modeling, by incorporating gating, convolutions, and input-dependent token selection to mitigate the quadratic cost of multi-head attention. Although SSMs exhibit competitive performance, their in-context learning (ICL) capabilities, a remarkable emergent property of modern language models that enables task execution without parameter optimization, remain underexplored compared to Transformers. In this study, we evaluate the ICL performance of SSMs, focusing on Mamba, against Transformer models across various tasks. Our results show that SSMs perform comparably to Transformers in standard regression ICL tasks, while outperforming them in tasks like sparse parity learning. However, SSMs fall short in tasks involving non-standard retrieval functionality. To address these limitations, we introduce a hybrid model, MambaFormer, that combines Mamba with attention blocks, surpassing individual models in tasks where they struggle independently. Our findings suggest that hybrid architectures offer promising avenues for enhancing ICL in language models.
4/26/2024

New!Exploring the Capability of Mamba in Speech Applications
Koichi Miyazaki, Yoshiki Masuyama, Masato Murata
0
0
This paper explores the capability of Mamba, a recently proposed architecture based on state space models (SSMs), as a competitive alternative to Transformer-based models. In the speech domain, well-designed Transformer-based models, such as the Conformer and E-Branchformer, have become the de facto standards. Extensive evaluations have demonstrated the effectiveness of these Transformer-based models across a wide range of speech tasks. In contrast, the evaluation of SSMs has been limited to a few tasks, such as automatic speech recognition (ASR) and speech synthesis. In this paper, we compared Mamba with state-of-the-art Transformer variants for various speech applications, including ASR, text-to-speech, spoken language understanding, and speech summarization. Experimental evaluations revealed that Mamba achieves comparable or better performance than Transformer-based models, and demonstrated its efficiency in long-form speech processing.
6/26/2024
🧠
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
Tri Dao, Albert Gu
0
0
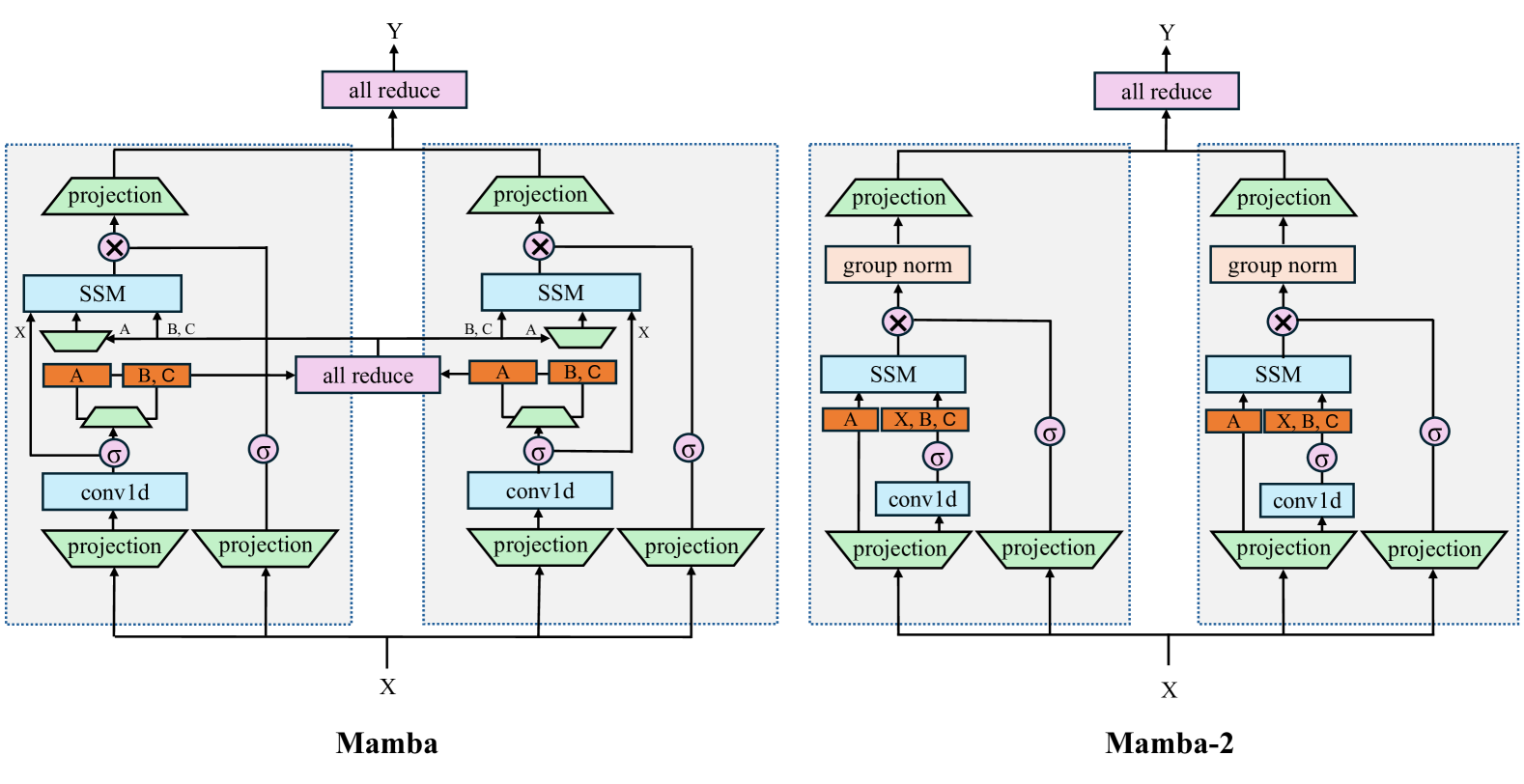
While Transformers have been the main architecture behind deep learning's success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Transformers at small to medium scale. We show that these families of models are actually quite closely related, and develop a rich framework of theoretical connections between SSMs and variants of attention, connected through various decompositions of a well-studied class of structured semiseparable matrices. Our state space duality (SSD) framework allows us to design a new architecture (Mamba-2) whose core layer is an a refinement of Mamba's selective SSM that is 2-8X faster, while continuing to be competitive with Transformers on language modeling.
6/3/2024
Mamba State-Space Models Can Be Strong Downstream Learners
John T. Halloran, Manbir Gulati, Paul F. Roysdon
0
0
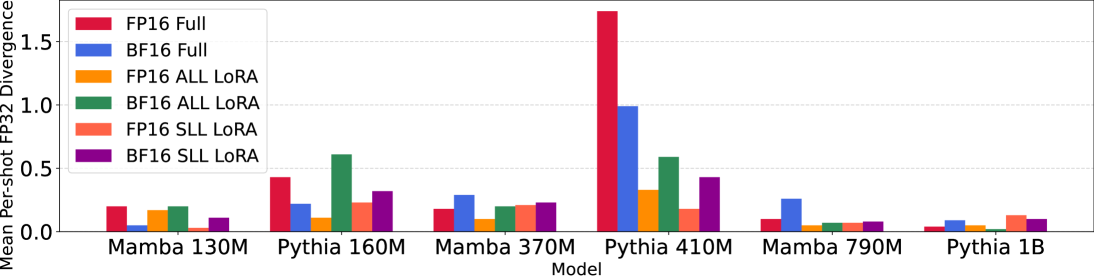
Mamba state-space models (SSMs) have recently outperformed state-of-the-art (SOTA) Transformer large language models (LLMs) in various tasks and been widely adapted. However, Mamba's downstream learning capabilities remain either unexplored$unicode{x2013}$e.g., mixed-precision (MPFT) and parameter-efficient fine-tuning (PEFT)--or under-evaluated$unicode{x2013}$e.g., in-context learning (ICL). For the latter, recent works reported Mamba's ICL rivals SOTA Transformer LLMs using non-standard benchmarks. In contrast, we show that on standard benchmarks, pretrained Mamba models achieve only 38% of the ICL performance improvements (over zero-shot) of comparable Transformers. Enabling MPFT and PEFT in Mamba architectures is challenging due to recurrent dynamics and highly customized CUDA kernels, respectively. However, we prove that Mamba's recurrent dynamics are robust to small input changes using dynamical systems theory. Empirically, we show that performance changes in Mamba's inference and fine-tuning due to mixed-precision align with Transformer LLMs. Furthermore, we show that targeting key memory buffers in Mamba's customized CUDA kernels for low-rank adaptation regularizes SSM parameters, thus achieving parameter efficiency while retaining speedups. We show that combining MPFT and PEFT enables up to 2.15 times more tokens-per-second and 65.5% reduced per-token-memory compared to full Mamba fine-tuning, while achieving up to 81.5% of the ICL performance improvements (over zero-shot) of comparably fine-tuned Transformers.
6/4/2024