Mamba State-Space Models Can Be Strong Downstream Learners

0
Sign in to get full access
Overview
- This paper presents a new type of machine learning model called a Mamba State-Space Model (MSSM) that can be used as a strong downstream learner.
- MSSMs are a type of state-space model, which is a mathematical framework for modeling systems that evolve over time.
- The paper shows that MSSMs can outperform other types of models on a variety of downstream learning tasks, suggesting they may be a powerful and versatile tool for machine learning.
Plain English Explanation
MSSMs are a new kind of machine learning model that work by breaking down a problem into smaller pieces and tracking how those pieces change over time. This allows them to learn complex patterns in data that might be difficult for other types of models to capture.
The researchers found that when you train an MSSM on one task, like classifying images or predicting the future of a time series, it can then be used as a strong "downstream learner" to tackle other related tasks. This means the MSSM has learned general skills that transfer well to new problems, similar to how humans can apply what they've learned in one area to something new.
This is an important finding because it suggests MSSMs could be a versatile and powerful tool for machine learning. Rather than having to train a brand new model from scratch for each new task, you may be able to fine-tune an MSSM and get good results, saving time and computing resources.
Technical Explanation
The core idea behind MSSMs is to model a system's evolution over time using a state-space representation. This means breaking down the system into a set of latent state variables that interact dynamically. The model learns to predict how these states will change from one time step to the next.
In this paper, the authors show that MSSMs trained on one task can be effectively used as "downstream learners" for other related tasks. They evaluate this on a variety of benchmarks, including image classification, time series forecasting, and reinforcement learning. The results demonstrate that MSSMs can match or outperform other state-of-the-art models, suggesting they are a versatile and powerful tool for machine learning.
The authors attribute the strong downstream performance of MSSMs to their ability to learn rich and general representations of the input data. By modeling the underlying dynamics of the system, the MSSM discovers features and patterns that are useful across multiple tasks. This stands in contrast to more rigid models that may excel on a specific problem but struggle to generalize.
Critical Analysis
One potential limitation of this work is that the authors only evaluate the downstream learning capabilities of MSSMs on a relatively narrow set of benchmarks. It would be interesting to see how they perform on a wider range of tasks, including more complex real-world applications.
Additionally, the paper does not provide a detailed analysis of the computational efficiency of MSSMs compared to other models. This is an important consideration, as the added modeling complexity of state-space representations could come with increased training and inference times.
That said, the core finding that MSSMs can serve as strong downstream learners is a compelling one that merits further investigation. If these models can indeed transfer knowledge effectively between related tasks, it could lead to significant efficiency gains in machine learning pipelines.
Conclusion
This paper introduces Mamba State-Space Models (MSSMs) as a new type of machine learning model that can be used as a powerful downstream learner. By modeling the underlying dynamics of a system, MSSMs are able to discover rich and general representations that transfer well to other related tasks.
The strong empirical results presented in this work suggest that MSSMs could be a versatile and valuable tool for a wide range of machine learning applications. If further research confirms their ability to learn transferable features, it could lead to more efficient and effective machine learning systems that can adapt to new problems without having to start from scratch.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mamba State-Space Models Can Be Strong Downstream Learners
John T. Halloran, Manbir Gulati, Paul F. Roysdon
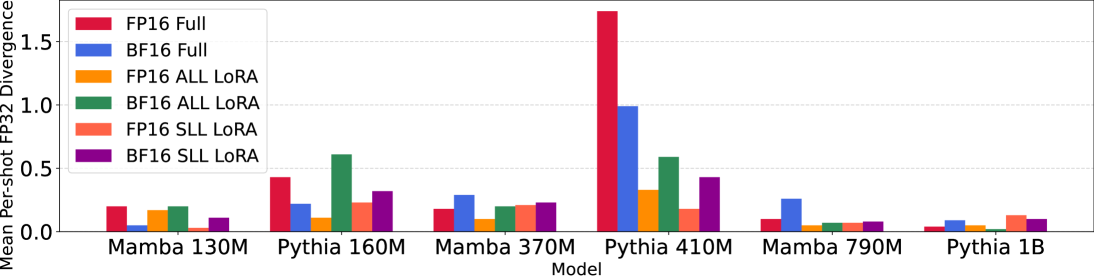
Mamba state-space models (SSMs) have recently outperformed state-of-the-art (SOTA) Transformer large language models (LLMs) in various tasks and been widely adapted. However, Mamba's downstream learning capabilities remain either unexplored$unicode{x2013}$e.g., mixed-precision (MPFT) and parameter-efficient fine-tuning (PEFT)--or under-evaluated$unicode{x2013}$e.g., in-context learning (ICL). For the latter, recent works reported Mamba's ICL rivals SOTA Transformer LLMs using non-standard benchmarks. In contrast, we show that on standard benchmarks, pretrained Mamba models achieve only 38% of the ICL performance improvements (over zero-shot) of comparable Transformers. Enabling MPFT and PEFT in Mamba architectures is challenging due to recurrent dynamics and highly customized CUDA kernels, respectively. However, we prove that Mamba's recurrent dynamics are robust to small input changes using dynamical systems theory. Empirically, we show that performance changes in Mamba's inference and fine-tuning due to mixed-precision align with Transformer LLMs. Furthermore, we show that targeting key memory buffers in Mamba's customized CUDA kernels for low-rank adaptation regularizes SSM parameters, thus achieving parameter efficiency while retaining speedups. We show that combining MPFT and PEFT enables up to 2.15 times more tokens-per-second and 65.5% reduced per-token-memory compared to full Mamba fine-tuning, while achieving up to 81.5% of the ICL performance improvements (over zero-shot) of comparably fine-tuned Transformers.
Read more6/4/2024
30
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
Read more6/13/2024
🎯
0
Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks
Jongho Park, Jaeseung Park, Zheyang Xiong, Nayoung Lee, Jaewoong Cho, Samet Oymak, Kangwook Lee, Dimitris Papailiopoulos
State-space models (SSMs), such as Mamba (Gu & Dao, 2023), have been proposed as alternatives to Transformer networks in language modeling, by incorporating gating, convolutions, and input-dependent token selection to mitigate the quadratic cost of multi-head attention. Although SSMs exhibit competitive performance, their in-context learning (ICL) capabilities, a remarkable emergent property of modern language models that enables task execution without parameter optimization, remain underexplored compared to Transformers. In this study, we evaluate the ICL performance of SSMs, focusing on Mamba, against Transformer models across various tasks. Our results show that SSMs perform comparably to Transformers in standard regression ICL tasks, while outperforming them in tasks like sparse parity learning. However, SSMs fall short in tasks involving non-standard retrieval functionality. To address these limitations, we introduce a hybrid model, MambaFormer, that combines Mamba with attention blocks, surpassing individual models in tasks where they struggle independently. Our findings suggest that hybrid architectures offer promising avenues for enhancing ICL in language models.
Read more4/26/2024

0
MambaTS: Improved Selective State Space Models for Long-term Time Series Forecasting
Xiuding Cai, Yaoyao Zhu, Xueyao Wang, Yu Yao
In recent years, Transformers have become the de-facto architecture for long-term sequence forecasting (LTSF), but faces challenges such as quadratic complexity and permutation invariant bias. A recent model, Mamba, based on selective state space models (SSMs), has emerged as a competitive alternative to Transformer, offering comparable performance with higher throughput and linear complexity related to sequence length. In this study, we analyze the limitations of current Mamba in LTSF and propose four targeted improvements, leading to MambaTS. We first introduce variable scan along time to arrange the historical information of all the variables together. We suggest that causal convolution in Mamba is not necessary for LTSF and propose the Temporal Mamba Block (TMB). We further incorporate a dropout mechanism for selective parameters of TMB to mitigate model overfitting. Moreover, we tackle the issue of variable scan order sensitivity by introducing variable permutation training. We further propose variable-aware scan along time to dynamically discover variable relationships during training and decode the optimal variable scan order by solving the shortest path visiting all nodes problem during inference. Extensive experiments conducted on eight public datasets demonstrate that MambaTS achieves new state-of-the-art performance.
Read more5/28/2024