Exploring the Capability of Mamba in Speech Applications
2406.16808
0
0

Abstract
This paper explores the capability of Mamba, a recently proposed architecture based on state space models (SSMs), as a competitive alternative to Transformer-based models. In the speech domain, well-designed Transformer-based models, such as the Conformer and E-Branchformer, have become the de facto standards. Extensive evaluations have demonstrated the effectiveness of these Transformer-based models across a wide range of speech tasks. In contrast, the evaluation of SSMs has been limited to a few tasks, such as automatic speech recognition (ASR) and speech synthesis. In this paper, we compared Mamba with state-of-the-art Transformer variants for various speech applications, including ASR, text-to-speech, spoken language understanding, and speech summarization. Experimental evaluations revealed that Mamba achieves comparable or better performance than Transformer-based models, and demonstrated its efficiency in long-form speech processing.
Create account to get full access
Overview
- This paper explores the potential of the Mamba model, a novel neural network architecture, for speech applications.
- The researchers investigate how Mamba compares to other state-of-the-art models like Transformers in various speech-related tasks.
- The paper covers several Mamba-based models, including Mamba-Speech, SP-Mamba, and Dual-Path Mamba, which aim to leverage Mamba's unique properties for speech enhancement, recognition, and related applications.
Plain English Explanation
The paper examines how a new type of neural network called Mamba can be used for speech-related tasks. Mamba is a different way of structuring a neural network compared to other common models like Transformers. The researchers explore several Mamba-based models to see how they perform on things like improving the quality of speech recordings, recognizing speech, and other speech applications.
The key idea behind Mamba is that it can capture both short-term and long-term dependencies in data, which may be particularly useful for speech. The researchers compare the performance of Mamba-based models to other state-of-the-art approaches to see if Mamba offers any advantages for speech technology.
Technical Explanation
The paper presents an empirical study of Mamba-based language models and their application to speech-related tasks. Mamba is a novel neural network architecture that aims to model both short-term and long-term dependencies in data more effectively than traditional models like Transformers.
The researchers investigate several Mamba-based models for speech applications:
- Mamba-Speech: A Mamba-based model for speech enhancement that outperforms Transformer-based approaches.
- SP-Mamba: A state-space model that leverages Mamba's capabilities for speech recognition.
- Dual-Path Mamba: A Mamba-based model that captures both short-term and long-term dependencies for speech-related tasks.
The paper presents detailed experiments comparing the performance of these Mamba-based models to state-of-the-art Transformer-based approaches on various speech datasets and benchmarks. The results suggest that Mamba can offer advantages over Transformers for certain speech applications, particularly where capturing long-term dependencies is important.
Critical Analysis
The paper provides a comprehensive evaluation of Mamba-based models for speech applications and offers valuable insights. However, the authors acknowledge several limitations and areas for further research:
- The paper focuses on a relatively narrow set of speech-related tasks, and it would be beneficial to explore Mamba's potential for a broader range of speech applications.
- The experiments are conducted on a limited number of datasets, and additional validation on larger and more diverse datasets would strengthen the findings.
- The researchers note that the computational efficiency of Mamba-based models compared to Transformers is an open question that requires further investigation.
- Some of the Mamba-based models, such as SP-Mamba, are relatively complex, and their practical deployment may be challenging, particularly in resource-constrained environments.
While the paper presents promising results, further research is needed to fully understand the strengths and limitations of Mamba for speech technology and to explore its potential applications in real-world settings.
Conclusion
This paper provides a comprehensive exploration of the Mamba model and its potential for speech applications. The researchers demonstrate that Mamba-based models can outperform state-of-the-art Transformer-based approaches in various speech-related tasks, particularly where capturing long-term dependencies is crucial.
The findings suggest that Mamba may offer a valuable alternative to Transformers in speech technology, with potential applications in areas like speech enhancement, recognition, and related areas. However, the researchers also identify several limitations and areas for further investigation, highlighting the need for continued research to fully understand Mamba's capabilities and practical implications for speech applications.
Overall, this paper contributes to the growing body of research on novel neural network architectures and their potential to advance the field of speech technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
0
0
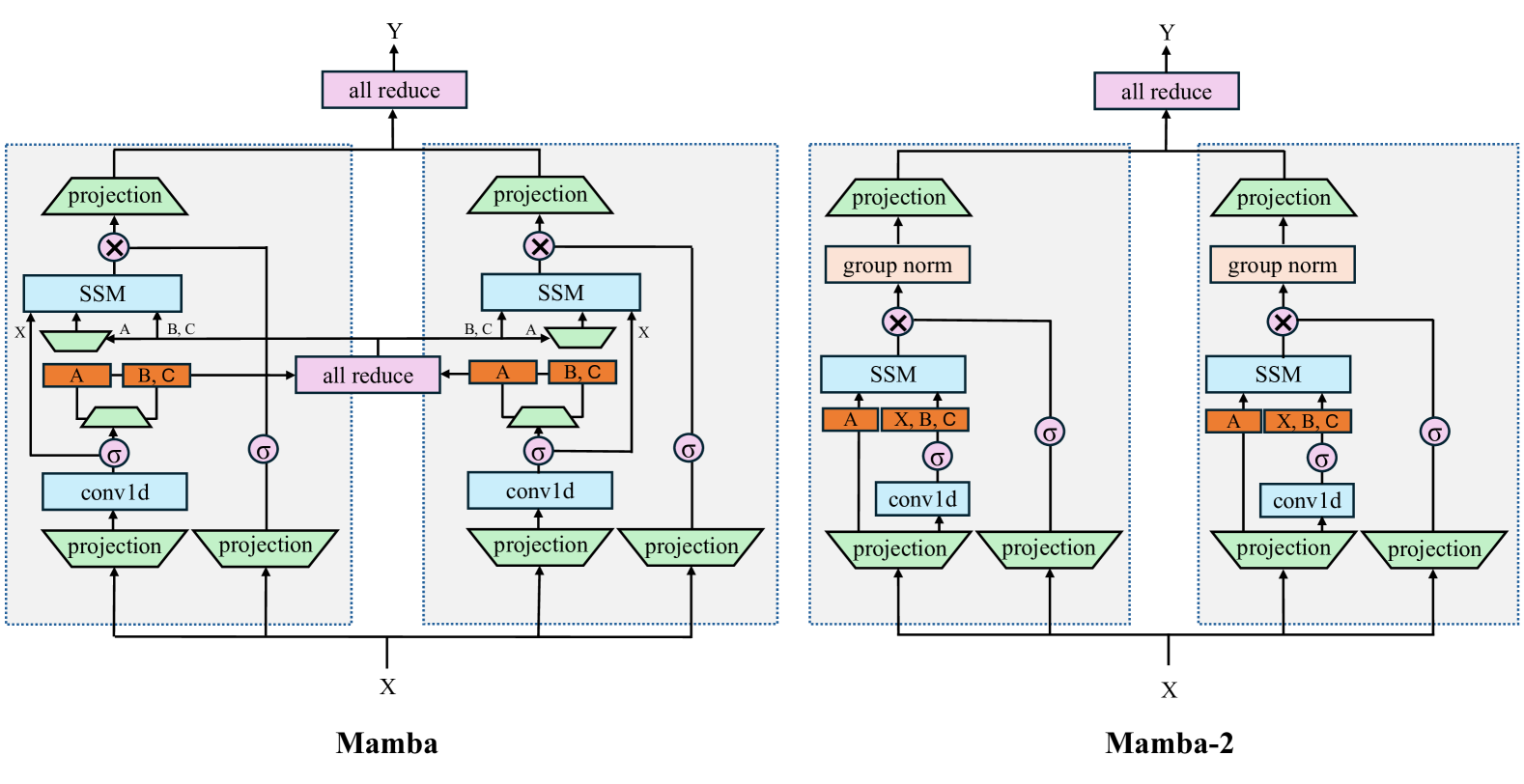
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
6/13/2024
🤯
Mamba in Speech: Towards an Alternative to Self-Attention
Xiangyu Zhang, Qiquan Zhang, Hexin Liu, Tianyi Xiao, Xinyuan Qian, Beena Ahmed, Eliathamby Ambikairajah, Haizhou Li, Julien Epps
0
0
Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing using two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The experimental results exhibit the superiority of bidirectional Mamba (BiMamba) for speech processing to vanilla Mamba. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in Transformer and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section to offer insights for future research.
5/27/2024
🗣️
An Investigation of Incorporating Mamba for Speech Enhancement
Rong Chao, Wen-Huang Cheng, Moreno La Quatra, Sabato Marco Siniscalchi, Chao-Han Huck Yang, Szu-Wei Fu, Yu Tsao
0
0
This work aims to study a scalable state-space model (SSM), Mamba, for the speech enhancement (SE) task. We exploit a Mamba-based regression model to characterize speech signals and build an SE system upon Mamba, termed SEMamba. We explore the properties of Mamba by integrating it as the core model in both basic and advanced SE systems, along with utilizing signal-level distances as well as metric-oriented loss functions. SEMamba demonstrates promising results and attains a PESQ score of 3.55 on the VoiceBank-DEMAND dataset. When combined with the perceptual contrast stretching technique, the proposed SEMamba yields a new state-of-the-art PESQ score of 3.69.
5/13/2024
SPMamba: State-space model is all you need in speech separation
Kai Li, Guo Chen
0
0
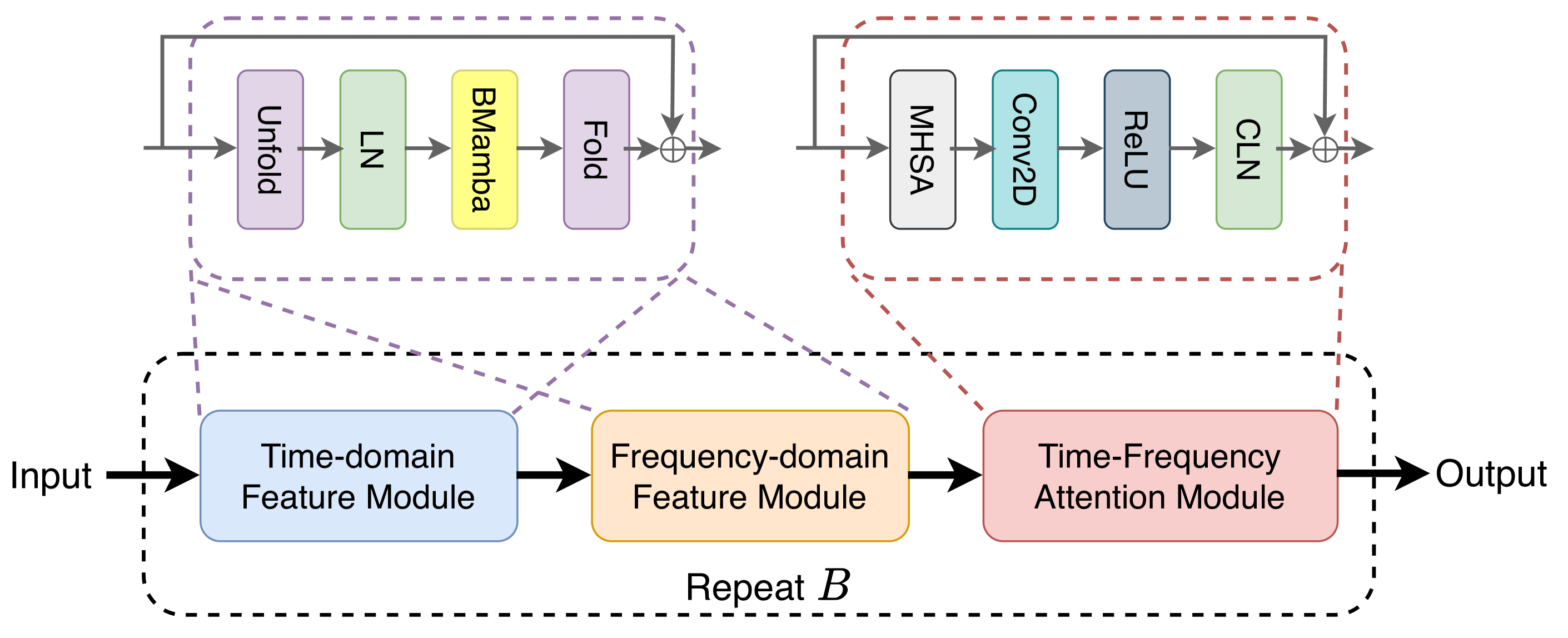
In speech separation, both CNN- and Transformer-based models have demonstrated robust separation capabilities, garnering significant attention within the research community. However, CNN-based methods have limited modelling capability for long-sequence audio, leading to suboptimal separation performance. Conversely, Transformer-based methods are limited in practical applications due to their high computational complexity. Notably, within computer vision, Mamba-based methods have been celebrated for their formidable performance and reduced computational requirements. In this paper, we propose a network architecture for speech separation using a state-space model, namely SPMamba. We adopt the TF-GridNet model as the foundational framework and substitute its Transformer component with a bidirectional Mamba module, aiming to capture a broader range of contextual information. Our experimental results reveal an important role in the performance aspects of Mamba-based models. SPMamba demonstrates superior performance with a significant advantage over existing separation models in a dataset built on Librispeech. Notably, SPMamba achieves a substantial improvement in separation quality, with a 2.42 dB enhancement in SI-SNRi compared to the TF-GridNet. The source code for SPMamba is publicly accessible at https://github.com/JusperLee/SPMamba .
4/3/2024