An Empirical Study of Pre-trained Model Selection for Out-of-Distribution Generalization and Calibration
2307.08187
0
0
📈
Abstract
In out-of-distribution (OOD) generalization tasks, fine-tuning pre-trained models has become a prevalent strategy. Different from most prior work that has focused on advancing learning algorithms, we systematically examined how pre-trained model size, pre-training dataset size, and training strategies impact generalization and uncertainty calibration on downstream tasks. We evaluated 100 models across diverse pre-trained model sizes, update{five} pre-training datasets, and five data augmentations through extensive experiments on four distribution shift datasets totaling over 120,000 GPU hours. Our results demonstrate the significant impact of pre-trained model selection, with optimal choices substantially improving OOD accuracy over algorithm improvement alone. We find larger models and bigger pre-training data improve OOD performance and calibration, in contrast to some prior studies that found modern deep networks to calibrate worse than classical shallow models. Our work underscores the overlooked importance of pre-trained model selection for out-of-distribution generalization and calibration.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Feature Protection For Out-of-distribution Generalization
Lu Tan, Huei Zhou, Yinxiang Huang, Zeming Zheng, Yujiu Yang
0
0
With the availability of large pre-trained models, a modern workflow for building real-world machine learning solutions is to fine-tune such models on a downstream task with a relatively small domain-specific dataset. In such applications, one major challenge is that the small fine-tuning dataset does not have sufficient coverage of the distribution encountered when the model is deployed. It is thus important to design fine-tuning methods that are robust to out-of-distribution (OOD) data that are under-represented by the training data. This paper compares common fine-tuning methods to investigate their OOD performance and demonstrates that standard methods will result in a significant change to the pre-trained model so that the fine-tuned features overfit the fine-tuning dataset. However, this causes deteriorated OOD performance. To overcome this issue, we show that protecting pre-trained features leads to a fine-tuned model more robust to OOD generalization. We validate the feature protection methods with extensive experiments of fine-tuning CLIP on ImageNet and DomainNet.
5/28/2024
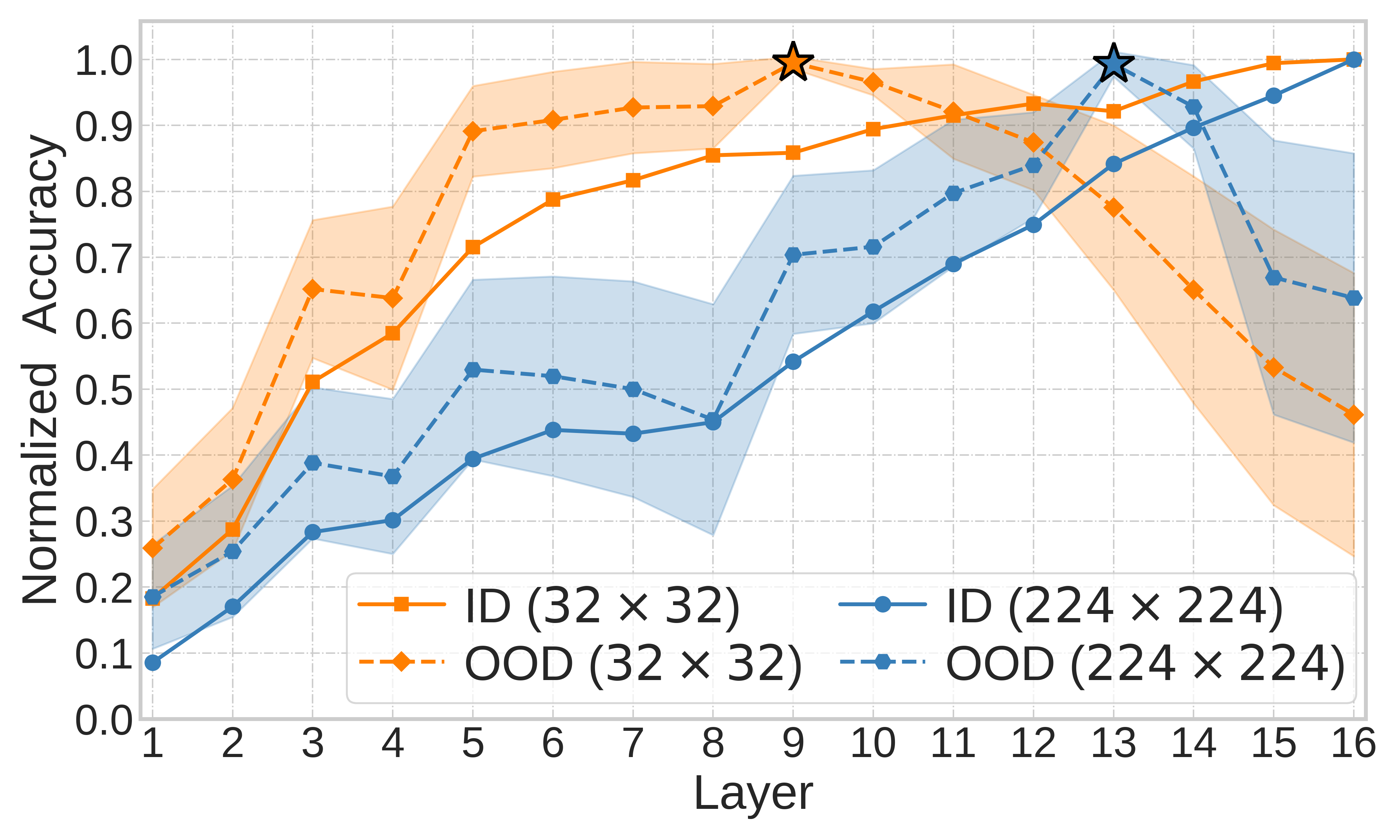
What Variables Affect Out-Of-Distribution Generalization in Pretrained Models?
Md Yousuf Harun, Kyungbok Lee, Jhair Gallardo, Giri Krishnan, Christopher Kanan
0
0
Embeddings produced by pre-trained deep neural networks (DNNs) are widely used; however, their efficacy for downstream tasks can vary widely. We study the factors influencing out-of-distribution (OOD) generalization of pre-trained DNN embeddings through the lens of the tunnel effect hypothesis, which suggests deeper DNN layers compress representations and hinder OOD performance. Contrary to earlier work, we find the tunnel effect is not universal. Based on 10,584 linear probes, we study the conditions that mitigate the tunnel effect by varying DNN architecture, training dataset, image resolution, and augmentations. We quantify each variable's impact using a novel SHAP analysis. Our results emphasize the danger of generalizing findings from toy datasets to broader contexts.
6/13/2024

How to train your ViT for OOD Detection
Maximilian Mueller, Matthias Hein
0
0
VisionTransformers have been shown to be powerful out-of-distribution detectors for ImageNet-scale settings when finetuned from publicly available checkpoints, often outperforming other model types on popular benchmarks. In this work, we investigate the impact of both the pretraining and finetuning scheme on the performance of ViTs on this task by analyzing a large pool of models. We find that the exact type of pretraining has a strong impact on which method works well and on OOD detection performance in general. We further show that certain training schemes might only be effective for a specific type of out-distribution, but not in general, and identify a best-practice training recipe.
5/29/2024
✨
Towards Calibrated Robust Fine-Tuning of Vision-Language Models
Changdae Oh, Hyesu Lim, Mijoo Kim, Dongyoon Han, Sangdoo Yun, Jaegul Choo, Alexander Hauptmann, Zhi-Qi Cheng, Kyungwoo Song
0
0
Improving out-of-distribution (OOD) generalization through in-distribution (ID) adaptation is a primary goal of robust fine-tuning methods beyond the naive fine-tuning approach. However, despite decent OOD generalization performance from recent robust fine-tuning methods, OOD confidence calibration for reliable machine learning has not been fully addressed. This work proposes a robust fine-tuning method that improves both OOD accuracy and calibration error in Vision Language Models (VLMs). Firstly, we show that both types of errors have a shared upper bound consisting of two terms of ID data: 1) calibration error and 2) the smallest singular value of the input covariance matrix. Based on this insight, we design a novel framework that conducts fine-tuning with a constrained multimodal contrastive loss enforcing a larger smallest singular value, which is further aided by the self-distillation of a moving averaged model to achieve well-calibrated prediction. Starting from an empirical validation of our theoretical statements, we provide extensive experimental results on ImageNet distribution shift benchmarks that demonstrate the effectiveness of our method.
5/28/2024