What Variables Affect Out-Of-Distribution Generalization in Pretrained Models?
2405.15018
0
0
Abstract
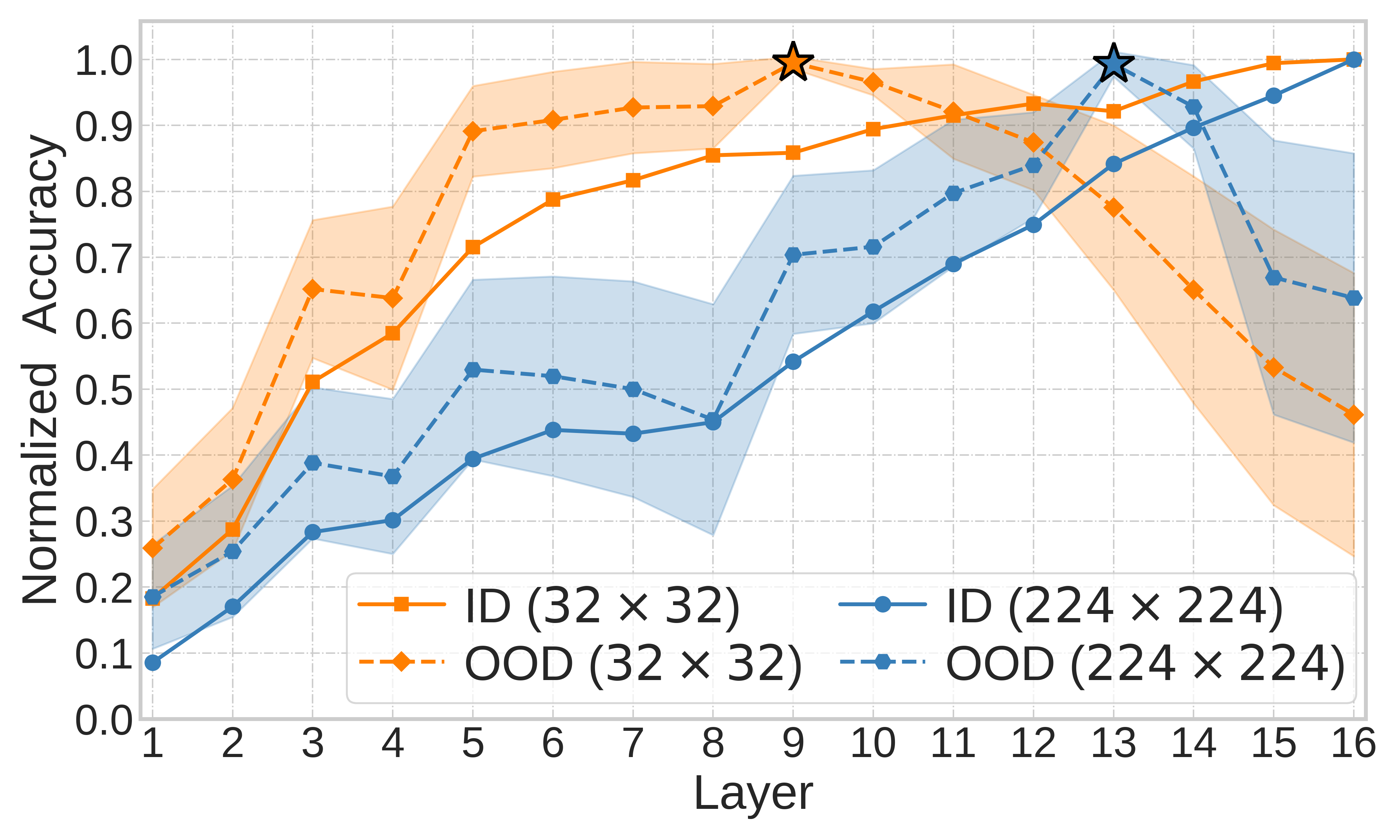
Embeddings produced by pre-trained deep neural networks (DNNs) are widely used; however, their efficacy for downstream tasks can vary widely. We study the factors influencing out-of-distribution (OOD) generalization of pre-trained DNN embeddings through the lens of the tunnel effect hypothesis, which suggests deeper DNN layers compress representations and hinder OOD performance. Contrary to earlier work, we find the tunnel effect is not universal. Based on 10,584 linear probes, we study the conditions that mitigate the tunnel effect by varying DNN architecture, training dataset, image resolution, and augmentations. We quantify each variable's impact using a novel SHAP analysis. Our results emphasize the danger of generalizing findings from toy datasets to broader contexts.
Create account to get full access
Overview
• This paper investigates the factors that affect the ability of pretrained models to generalize to data that is distributed differently from the training data, a phenomenon known as out-of-distribution (OOD) generalization.
• The researchers explore how variables like dataset size, model architecture, and training techniques impact a model's ability to perform well on OOD data.
• The findings have important implications for developing robust and generalizable AI systems that can reliably perform well across a variety of real-world scenarios.
Plain English Explanation
Machine learning models are often trained on specific datasets, which can limit their ability to perform well on data that looks different from the training data. This is known as the out-of-distribution (OOD) generalization problem.
The paper "Can Biases in ImageNet Models Explain Generalization?" showed that even models trained on large datasets like ImageNet can struggle with OOD tasks. This raises the question of what factors influence a model's ability to generalize to new, different data.
The researchers in this paper explored how variables like the size of the training dataset, the model architecture, and the training techniques used can affect OOD generalization. They conducted a series of experiments to understand these relationships better.
For example, they found that using a more diverse training dataset, as explored in "Unraveling the Key Components of OOD Generalization via Diversification", can help improve a model's ability to handle OOD data. However, simply mixing different datasets, as discussed in "Mixture of Data Training Cannot Ensure Out-of-Distribution Generalization", does not always lead to better OOD performance.
The researchers also looked at ways to quantify a model's OOD generalization capabilities, as outlined in "A Separability-based Approach to Quantifying Generalization". And they explored techniques for detecting OOD samples, as described in "Out-of-Distribution Detection Based on Subspace Projection".
Understanding the factors that influence OOD generalization is crucial for developing AI systems that can reliably perform well in the real world, where the data they encounter may differ significantly from their training data.
Technical Explanation
The paper examines how various factors, such as dataset size, model architecture, and training techniques, affect a model's ability to generalize to out-of-distribution (OOD) data. OOD generalization is an important challenge in machine learning, as models trained on specific datasets may struggle to perform well on data that looks different from the training data.
The researchers conducted a series of experiments to explore the relationships between these variables and OOD generalization. For example, they found that using a more diverse training dataset, as explored in "Unraveling the Key Components of OOD Generalization via Diversification", can help improve a model's ability to handle OOD data. However, simply mixing different datasets, as discussed in "Mixture of Data Training Cannot Ensure Out-of-Distribution Generalization", does not always lead to better OOD performance.
The paper also looks at ways to quantify a model's OOD generalization capabilities, as outlined in "A Separability-based Approach to Quantifying Generalization", and techniques for detecting OOD samples, as described in "Out-of-Distribution Detection Based on Subspace Projection".
Understanding the factors that influence OOD generalization is crucial for developing AI systems that can reliably perform well in the real world, where the data they encounter may differ significantly from their training data.
Critical Analysis
The paper provides valuable insights into the complex factors that affect out-of-distribution (OOD) generalization in pretrained models. By exploring the roles of dataset size, model architecture, and training techniques, the researchers offer a nuanced understanding of this important challenge in machine learning.
One potential limitation of the study is the scope of the experiments, which may not capture the full range of real-world scenarios. The researchers acknowledge this in their discussion of future work, noting the need to further investigate OOD generalization in more diverse and complex settings.
Additionally, the paper does not delve deeply into the underlying mechanisms that drive the observed relationships between the variables and OOD performance. Further research exploring the specific biases and limitations of pretrained models could provide additional insights into this phenomenon.
Overall, the paper makes a valuable contribution to the field of machine learning by shedding light on the factors that influence OOD generalization. The findings have important implications for the development of robust and generalizable AI systems that can reliably perform well across a variety of real-world scenarios.
Conclusion
This paper presents a comprehensive investigation into the factors that affect out-of-distribution (OOD) generalization in pretrained machine learning models. The researchers explored the roles of dataset size, model architecture, and training techniques, providing valuable insights into the complex interplay of these variables and their impact on a model's ability to perform well on data that differs from its training data.
The findings have significant implications for the development of AI systems that can reliably and robustly handle the diverse range of data encountered in real-world applications. By understanding the key drivers of OOD generalization, researchers and practitioners can work towards creating more generalizable and adaptable models that can thrive in dynamic and unpredictable environments.
Overall, this paper contributes to the ongoing efforts to address the critical challenge of OOD generalization, paving the way for the creation of more versatile and trustworthy AI systems that can truly benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
An Empirical Study of Pre-trained Model Selection for Out-of-Distribution Generalization and Calibration
Hiroki Naganuma, Ryuichiro Hataya, Ioannis Mitliagkas
0
0
In out-of-distribution (OOD) generalization tasks, fine-tuning pre-trained models has become a prevalent strategy. Different from most prior work that has focused on advancing learning algorithms, we systematically examined how pre-trained model size, pre-training dataset size, and training strategies impact generalization and uncertainty calibration on downstream tasks. We evaluated 100 models across diverse pre-trained model sizes, update{five} pre-training datasets, and five data augmentations through extensive experiments on four distribution shift datasets totaling over 120,000 GPU hours. Our results demonstrate the significant impact of pre-trained model selection, with optimal choices substantially improving OOD accuracy over algorithm improvement alone. We find larger models and bigger pre-training data improve OOD performance and calibration, in contrast to some prior studies that found modern deep networks to calibrate worse than classical shallow models. Our work underscores the overlooked importance of pre-trained model selection for out-of-distribution generalization and calibration.
6/3/2024

Benchmarking Out-of-Distribution Generalization Capabilities of DNN-based Encoding Models for the Ventral Visual Cortex
Spandan Madan, Will Xiao, Mingran Cao, Hanspeter Pfister, Margaret Livingstone, Gabriel Kreiman
0
0
We characterized the generalization capabilities of DNN-based encoding models when predicting neuronal responses from the visual cortex. We collected textit{MacaqueITBench}, a large-scale dataset of neural population responses from the macaque inferior temporal (IT) cortex to over $300,000$ images, comprising $8,233$ unique natural images presented to seven monkeys over $109$ sessions. Using textit{MacaqueITBench}, we investigated the impact of distribution shifts on models predicting neural activity by dividing the images into Out-Of-Distribution (OOD) train and test splits. The OOD splits included several different image-computable types including image contrast, hue, intensity, temperature, and saturation. Compared to the performance on in-distribution test images -- the conventional way these models have been evaluated -- models performed worse at predicting neuronal responses to out-of-distribution images, retaining as little as $20%$ of the performance on in-distribution test images. The generalization performance under OOD shifts can be well accounted by a simple image similarity metric -- the cosine distance between image representations extracted from a pre-trained object recognition model is a strong predictor of neural predictivity under different distribution shifts. The dataset of images, neuronal firing rate recordings, and computational benchmarks are hosted publicly at: https://bit.ly/3zeutVd.
6/26/2024

Feature Protection For Out-of-distribution Generalization
Lu Tan, Huei Zhou, Yinxiang Huang, Zeming Zheng, Yujiu Yang
0
0
With the availability of large pre-trained models, a modern workflow for building real-world machine learning solutions is to fine-tune such models on a downstream task with a relatively small domain-specific dataset. In such applications, one major challenge is that the small fine-tuning dataset does not have sufficient coverage of the distribution encountered when the model is deployed. It is thus important to design fine-tuning methods that are robust to out-of-distribution (OOD) data that are under-represented by the training data. This paper compares common fine-tuning methods to investigate their OOD performance and demonstrates that standard methods will result in a significant change to the pre-trained model so that the fine-tuned features overfit the fine-tuning dataset. However, this causes deteriorated OOD performance. To overcome this issue, we show that protecting pre-trained features leads to a fine-tuned model more robust to OOD generalization. We validate the feature protection methods with extensive experiments of fine-tuning CLIP on ImageNet and DomainNet.
5/28/2024
Can Biases in ImageNet Models Explain Generalization?
Paul Gavrikov, Janis Keuper
0
0
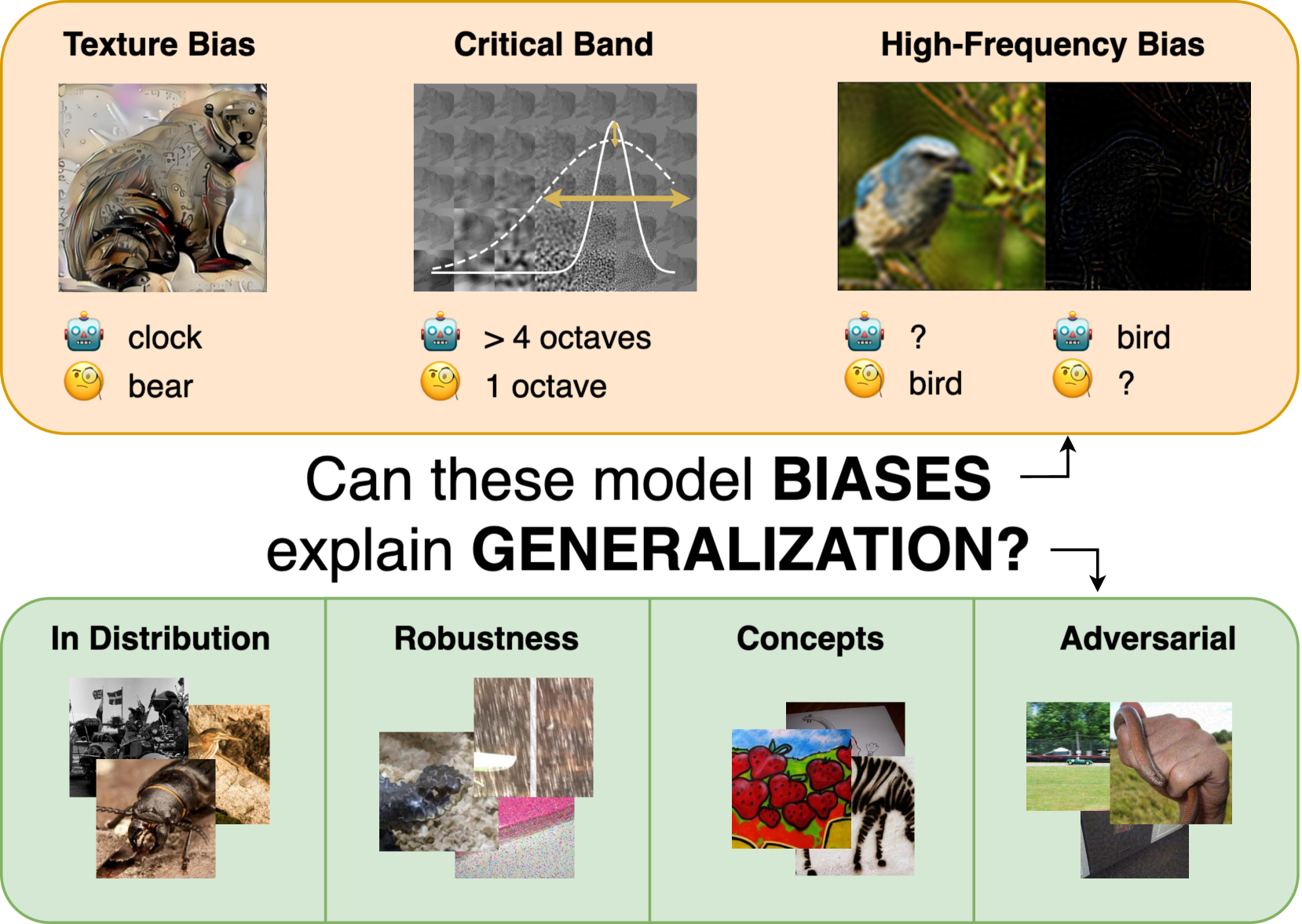
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
4/3/2024