An empirical study of testing machine learning in the wild

0
🧪
Sign in to get full access
Overview
- Recent research has focused on ensuring the quality of machine learning (ML) and deep learning (DL) systems, as they are increasingly being used in software applications.
- Traditional software testing methods may not be well-suited for these inductive ML/DL systems, which learn patterns from training data rather than being built deductively.
- This study aims to understand the practical application of ML testing strategies and the specific properties being tested in real-world ML deployments.
Plain English Explanation
Machine learning (ML) and deep learning (DL) algorithms have become more common in many software applications. Unlike traditional software that is built by explicitly writing out rules, ML/DL systems learn patterns from data. This makes ensuring the quality of these systems a significant challenge.
Researchers have tried adapting traditional software testing techniques, like mutation testing, to improve the reliability of ML/DL systems. However, it's unclear if these proposed testing methods are actually used in practice, or if new testing strategies have emerged from real-world ML deployments.
To address this gap, the researchers conducted a detailed study to understand the ML testing practices being used in the wild. They analyzed test files and cases from 11 open-source ML/DL projects on GitHub. By manually examining the testing strategies, tested ML properties, and implementation methods, the researchers gained insights into how ML/DL software systems are built and released in practice.
Technical Explanation
The researchers performed a mixed-methods study, combining quantitative analysis of test files and cases with qualitative open coding to understand the practical application of ML testing. They examined 11 open-source ML/DL projects on GitHub, looking at the testing strategies, tested ML properties, and implemented testing methods.
Their key findings include:
- The most common testing strategies, accounting for less than 40% of the tests, are Grey-box and White-box methods, such as Negative Testing, Oracle Approximation, and Statistical Testing.
- A wide range of 17 ML properties are tested, but only 20% to 30% are frequently tested, including Consistency, Correctness, and Efficiency.
- Certain ML properties are more often tested in specific domains - for example, Bias and Fairness is more tested in Recommendation systems, while Security & Privacy is tested in Computer Vision (CV), Application Platforms, and Natural Language Processing (NLP) systems.
These findings provide empirical evidence about the current state of ML testing practices, which can inform the development of more effective testing strategies and help bridge the gap between research and practice in ML software engineering.
Critical Analysis
The researchers acknowledge that their study is limited to a relatively small sample of 11 open-source projects, and the findings may not be fully representative of the broader ML/DL testing landscape. Additionally, the study focuses on understanding current practices, but does not evaluate the efficacy or suitability of the tested approaches.
Further research could explore testing strategies and ML properties in a larger, more diverse set of ML/DL projects, including both open-source and commercial systems. Investigating the reasons behind the observed testing practices, as well as the challenges and barriers to adopting more comprehensive testing approaches, could also provide valuable insights.
The researchers also suggest the need for systematic approaches to ML model testing and the use of machine learning to optimize software development, which could help address the unique challenges posed by the inductive nature of ML/DL systems.
Conclusion
This study provides the first fine-grained empirical insights into the current state of ML testing practices in the wild. The findings reveal that while a wide range of ML properties are being tested, the most common testing strategies account for less than 40% of the tests, and only a subset of the tested properties are frequently addressed.
These insights can inform the development of more comprehensive and effective testing approaches for ML/DL systems, helping to bridge the gap between research and practice in this critical area of software engineering. As ML/DL continue to be more widely adopted, ensuring the quality and reliability of these systems will become increasingly important for building safe and trustworthy applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
An empirical study of testing machine learning in the wild
Moses Openja (Jack), Foutse Khomh (Jack), Armstrong Foundjem (Jack), Zhen Ming (Jack), Jiang, Mouna Abidi, Ahmed E. Hassan
Recently, machine and deep learning (ML/DL) algorithms have been increasingly adopted in many software systems. Due to their inductive nature, ensuring the quality of these systems remains a significant challenge for the research community. Unlike traditional software built deductively by writing explicit rules, ML/DL systems infer rules from training data. Recent research in ML/DL quality assurance has adapted concepts from traditional software testing, such as mutation testing, to improve reliability. However, it is unclear if these proposed testing techniques are adopted in practice, or if new testing strategies have emerged from real-world ML deployments. There is little empirical evidence about the testing strategies. To fill this gap, we perform the first fine-grained empirical study on ML testing in the wild to identify the ML properties being tested, the testing strategies, and their implementation throughout the ML workflow. We conducted a mixed-methods study to understand ML software testing practices. We analyzed test files and cases from 11 open-source ML/DL projects on GitHub. Using open coding, we manually examined the testing strategies, tested ML properties, and implemented testing methods to understand their practical application in building and releasing ML/DL software systems. Our findings reveal several key insights: 1.) The most common testing strategies, accounting for less than 40%, are Grey-box and White-box methods, such as Negative Testing, Oracle Approximation and Statistical Testing. 2.) A wide range of 17 ML properties are tested, out of which only 20% to 30% are frequently tested, including Consistency, Correctness}, and Efficiency. 3.) Bias and Fairness is more tested in Recommendation, while Security & Privacy is tested in Computer Vision (CV) systems, Application Platforms, and Natural Language Processing (NLP) systems.
Read more7/16/2024
0
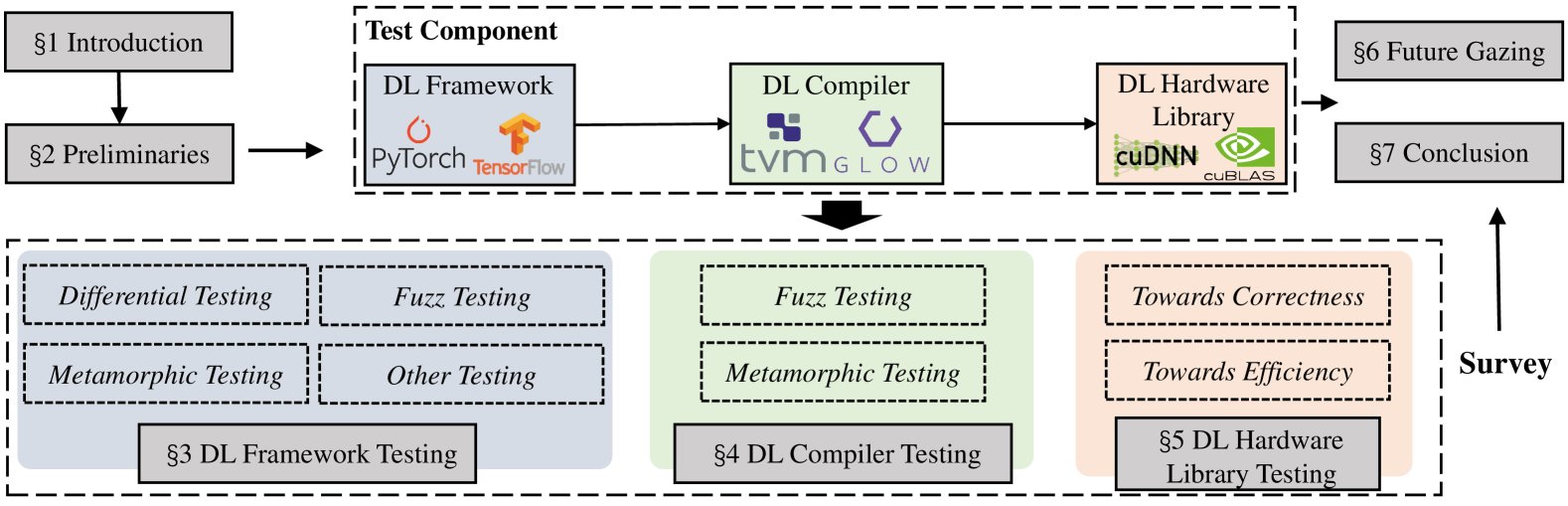
A Survey of Deep Learning Library Testing Methods
Xiaoyu Zhang, Weipeng Jiang, Chao Shen, Qi Li, Qian Wang, Chenhao Lin, Xiaohong Guan
In recent years, software systems powered by deep learning (DL) techniques have significantly facilitated people's lives in many aspects. As the backbone of these DL systems, various DL libraries undertake the underlying optimization and computation. However, like traditional software, DL libraries are not immune to bugs, which can pose serious threats to users' personal property and safety. Studying the characteristics of DL libraries, their associated bugs, and the corresponding testing methods is crucial for enhancing the security of DL systems and advancing the widespread application of DL technology. This paper provides an overview of the testing research related to various DL libraries, discusses the strengths and weaknesses of existing methods, and provides guidance and reference for the application of the DL library. This paper first introduces the workflow of DL underlying libraries and the characteristics of three kinds of DL libraries involved, namely DL framework, DL compiler, and DL hardware library. It then provides definitions for DL underlying library bugs and testing. Additionally, this paper summarizes the existing testing methods and tools tailored to these DL libraries separately and analyzes their effectiveness and limitations. It also discusses the existing challenges of DL library testing and outlines potential directions for future research.
Read more4/30/2024
🧪
0
The Role of Artificial Intelligence and Machine Learning in Software Testing
Ahmed Ramadan, Husam Yasin, Burhan Pektas
Artificial Intelligence (AI) and Machine Learning (ML) have significantly impacted various industries, including software development. Software testing, a crucial part of the software development lifecycle (SDLC), ensures the quality and reliability of software products. Traditionally, software testing has been a labor-intensive process requiring significant manual effort. However, the advent of AI and ML has transformed this landscape by introducing automation and intelligent decision-making capabilities. AI and ML technologies enhance the efficiency and effectiveness of software testing by automating complex tasks such as test case generation, test execution, and result analysis. These technologies reduce the time required for testing and improve the accuracy of defect detection, ultimately leading to higher quality software. AI can predict potential areas of failure by analyzing historical data and identifying patterns, which allows for more targeted and efficient testing. This paper explores the role of AI and ML in software testing by reviewing existing literature, analyzing current tools and techniques, and presenting case studies that demonstrate the practical benefits of these technologies. The literature review provides a comprehensive overview of the advancements in AI and ML applications in software testing, highlighting key methodologies and findings from various studies. The analysis of current tools showcases the capabilities of popular AI-driven testing tools such as Eggplant AI, Test.ai, Selenium, Appvance, Applitools Eyes, Katalon Studio, and Tricentis Tosca, each offering unique features and advantages. Case studies included in this paper illustrate real-world applications of AI and ML in software testing, showing significant improvements in testing efficiency, accuracy, and overall software quality.
Read more9/5/2024

0
A Large-Scale Study of Model Integration in ML-Enabled Software Systems
Yorick Sens, Henriette Knopp, Sven Peldszus, Thorsten Berger
The rise of machine learning (ML) and its embedding in systems has drastically changed the engineering of software-intensive systems. Traditionally, software engineering focuses on manually created artifacts such as source code and the process of creating them, as well as best practices for integrating them, i.e., software architectures. In contrast, the development of ML artifacts, i.e. ML models, comes from data science and focuses on the ML models and their training data. However, to deliver value to end users, these ML models must be embedded in traditional software, often forming complex topologies. In fact, ML-enabled software can easily incorporate many different ML models. While the challenges and practices of building ML-enabled systems have been studied to some extent, beyond isolated examples, little is known about the characteristics of real-world ML-enabled systems. Properly embedding ML models in systems so that they can be easily maintained or reused is far from trivial. We need to improve our empirical understanding of such systems, which we address by presenting the first large-scale study of real ML-enabled software systems, covering over 2,928 open source systems on GitHub. We classified and analyzed them to determine their characteristics, as well as their practices for reusing ML models and related code, and the architecture of these systems. Our findings provide practitioners and researchers with insight into practices for embedding and integrating ML models, bringing data science and software engineering closer together.
Read more8/13/2024