Empowering Large Language Models for Textual Data Augmentation
2404.17642
0
0
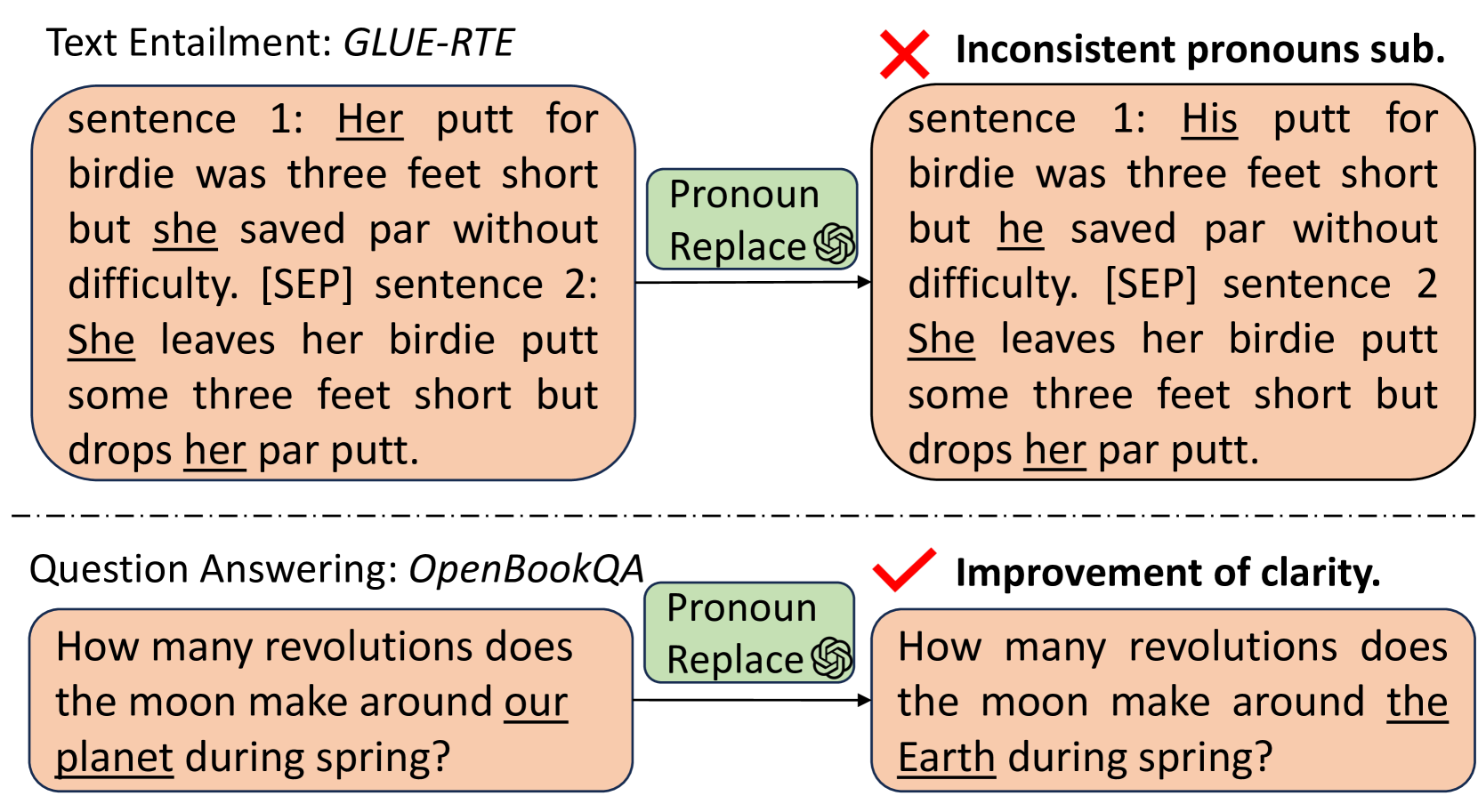
Abstract
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how large language models (LLMs) can be empowered to generate high-quality textual data for data augmentation, a technique used to improve the performance of machine learning models.
- The authors propose a novel approach that combines the strengths of LLMs with targeted prompting and fine-tuning, allowing for the generation of diverse and informative synthetic text.
- The research demonstrates the potential of LLMs to serve as a versatile and powerful tool for textual data augmentation, with implications for a wide range of natural language processing tasks.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can generate human-like text. In this paper, the researchers investigate how to use LLMs to create new text that can be used to improve the performance of other machine learning models. This is called "data augmentation," and it's a common technique in machine learning.
The researchers developed a new approach that combines the powerful language generation capabilities of LLMs with targeted prompting and fine-tuning. This allows the LLMs to generate diverse and informative synthetic text that can be used to supplement the original training data.
For example, let's say you have a machine learning model that is trying to classify whether a piece of text is positive or negative. You could use the LLM-based data augmentation approach to generate new positive and negative text samples, which you could then add to your training data. This could help the model learn more robust patterns and improve its performance.
The key insight of this research is that LLMs can be harnessed as a versatile tool for textual data augmentation, with applications across a wide range of natural language processing tasks, such as topic classification, personalized recommendation, and machine translation. By leveraging the generative power of LLMs, researchers and practitioners can generate high-quality synthetic data to enhance the performance of their models.
Technical Explanation
The paper proposes a novel approach for empowering large language models (LLMs) to generate high-quality synthetic text for data augmentation. The authors combine the strengths of LLMs with targeted prompting and fine-tuning to enable the generation of diverse and informative textual data.
The key technical components of the approach include:
-
Prompt Engineering: The researchers design specialized prompts that guide the LLM to generate text that is relevant and useful for the target task. This involves carefully crafting prompts that capture the desired characteristics of the synthetic data.
-
Iterative Fine-Tuning: The authors fine-tune the LLM on the target dataset, and then further fine-tune it on the generated synthetic data. This iterative process helps the LLM better understand the patterns and characteristics of the target domain, leading to the generation of higher-quality synthetic text.
-
Adaptive Filtering: To ensure the generated text is of high quality and aligns with the target task, the researchers develop an adaptive filtering mechanism. This allows them to selectively retain the most informative and diverse synthetic samples while discarding low-quality or redundant ones.
The paper presents a series of experiments that demonstrate the effectiveness of the proposed approach. The authors show that the LLM-based synthetic data can significantly improve the performance of machine learning models on a variety of natural language processing tasks, including text classification and question answering.
Critical Analysis
The paper presents a compelling approach for empowering LLMs to generate high-quality synthetic text for data augmentation. However, the authors acknowledge several caveats and areas for further research:
-
Prompt Engineering Complexity: The effectiveness of the approach relies heavily on the design of the prompts, which can be a complex and time-consuming task. The authors suggest exploring automated prompt generation techniques to address this limitation.
-
Generalization Across Domains: While the proposed method demonstrates strong performance on the evaluated tasks, the authors note that its generalization to significantly different domains may require further investigation and adaptation.
-
Potential Biases: Like any data generation process, the synthetic text produced by the LLM-based approach may inherit biases present in the training data. The authors emphasize the importance of carefully monitoring and mitigating such biases.
-
Computational Costs: The iterative fine-tuning process can be computationally expensive, especially when working with large-scale LLMs. Exploring more efficient fine-tuning strategies could help address this limitation.
Overall, the paper presents a promising approach that leverages the power of LLMs to enable high-quality textual data augmentation. The insights and techniques developed in this research could have far-reaching implications for enhancing the performance of a wide range of natural language processing applications.
Conclusion
This paper introduces a novel approach for empowering large language models (LLMs) to generate high-quality synthetic text for data augmentation. By combining targeted prompting and iterative fine-tuning, the researchers demonstrate how LLMs can be harnessed as a versatile tool for producing diverse and informative textual data.
The findings of this study highlight the potential of LLMs to significantly improve the performance of machine learning models across a variety of natural language processing tasks. As the field of artificial intelligence continues to advance, techniques like the one presented in this paper may play a crucial role in enhancing the capabilities of language-based systems and unlocking new possibilities for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Exploring LLMs as a Source of Targeted Synthetic Textual Data to Minimize High Confidence Misclassifications
Philip Lippmann, Matthijs T. J. Spaan, Jie Yang
0
0
Natural Language Processing (NLP) models optimized for predictive performance often make high confidence errors and suffer from vulnerability to adversarial and out-of-distribution data. Existing work has mainly focused on mitigation of such errors using either humans or an automated approach. In this study, we explore the usage of large language models (LLMs) for data augmentation as a potential solution to the issue of NLP models making wrong predictions with high confidence during classification tasks. We compare the effectiveness of synthetic data generated by LLMs with that of human data obtained via the same procedure. For mitigation, humans or LLMs provide natural language characterizations of high confidence misclassifications to generate synthetic data, which are then used to extend the training set. We conduct an extensive evaluation of our approach on three classification tasks and demonstrate its effectiveness in reducing the number of high confidence misclassifications present in the model, all while maintaining the same level of accuracy. Moreover, we find that the cost gap between humans and LLMs surpasses an order of magnitude, as LLMs attain human-like performance while being more scalable.
4/3/2024
💬
Large Language Model Enhanced Machine Learning Estimators for Classification
Yuhang Wu, Yingfei Wang, Chu Wang, Zeyu Zheng
0
0
Pre-trained large language models (LLM) have emerged as a powerful tool for simulating various scenarios and generating output given specific instructions and multimodal input. In this work, we analyze the specific use of LLM to enhance a classical supervised machine learning method for classification problems. We propose a few approaches to integrate LLM into a classical machine learning estimator to further enhance the prediction performance. We examine the performance of the proposed approaches through both standard supervised learning binary classification tasks, and a transfer learning task where the test data observe distribution changes compared to the training data. Numerical experiments using four publicly available datasets are conducted and suggest that using LLM to enhance classical machine learning estimators can provide significant improvement on prediction performance.
5/10/2024
💬
From Language Models to Practical Self-Improving Computer Agents
Alex Sheng
0
0
We develop a simple and straightforward methodology to create AI computer agents that can carry out diverse computer tasks and self-improve by developing tools and augmentations to enable themselves to solve increasingly complex tasks. As large language models (LLMs) have been shown to benefit from non-parametric augmentations, a significant body of recent work has focused on developing software that augments LLMs with various capabilities. Rather than manually developing static software to augment LLMs through human engineering effort, we propose that an LLM agent can systematically generate software to augment itself. We show, through a few case studies, that a minimal querying loop with appropriate prompt engineering allows an LLM to generate and use various augmentations, freely extending its own capabilities to carry out real-world computer tasks. Starting with only terminal access, we prompt an LLM agent to augment itself with retrieval, internet search, web navigation, and text editor capabilities. The agent effectively uses these various tools to solve problems including automated software development and web-based tasks.
4/19/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024