Exploring LLMs as a Source of Targeted Synthetic Textual Data to Minimize High Confidence Misclassifications
2403.17860
0
0
📊
Abstract
Natural Language Processing (NLP) models optimized for predictive performance often make high confidence errors and suffer from vulnerability to adversarial and out-of-distribution data. Existing work has mainly focused on mitigation of such errors using either humans or an automated approach. In this study, we explore the usage of large language models (LLMs) for data augmentation as a potential solution to the issue of NLP models making wrong predictions with high confidence during classification tasks. We compare the effectiveness of synthetic data generated by LLMs with that of human data obtained via the same procedure. For mitigation, humans or LLMs provide natural language characterizations of high confidence misclassifications to generate synthetic data, which are then used to extend the training set. We conduct an extensive evaluation of our approach on three classification tasks and demonstrate its effectiveness in reducing the number of high confidence misclassifications present in the model, all while maintaining the same level of accuracy. Moreover, we find that the cost gap between humans and LLMs surpasses an order of magnitude, as LLMs attain human-like performance while being more scalable.
Create account to get full access
Overview
- Current NLP models are prone to making high-confidence errors and are vulnerable to adversarial and out-of-distribution data
- Existing work has focused on mitigating these errors using either human input or automated approaches
- This study explores using large language models (LLMs) for data augmentation as a potential solution
Plain English Explanation
Natural language processing (NLP) models are computer systems that can understand and generate human language. These models are often optimized to make accurate predictions, but they can sometimes be overconfident and make mistakes that they're very sure about. They're also vulnerable to adversarial attacks, where someone intentionally tries to trick the model, and to data that's outside the model's normal range of experience.
The researchers in this study wanted to see if they could use large language models (LLMs), which are very advanced NLP models, to help fix this problem. They had humans or LLMs provide descriptions of the situations where the NLP model was making high-confidence mistakes. They then used those descriptions to generate new training data, which they added to the model's original training set.
The idea was that this additional data would help the model learn to be more cautious and less overconfident in its predictions, without losing overall accuracy. The researchers tested this approach on three different classification tasks (where the model has to choose the right category for some input) and found that it was effective at reducing the number of high-confidence mistakes, while maintaining the model's overall performance.
Interestingly, they also found that using the LLMs was much more cost-effective than using humans to generate the additional training data. The LLMs were able to provide human-like performance at a fraction of the cost.
Technical Explanation
The researchers explored using large language models (LLMs) for data augmentation as a potential solution to the problem of NLP models making high-confidence errors. They compared the effectiveness of synthetic data generated by LLMs to human-generated data obtained through the same procedure.
For the mitigation approach, they had either humans or LLMs provide natural language characterizations of high-confidence misclassifications. These characterizations were then used to generate additional synthetic training data, which was added to the original training set.
The researchers conducted an extensive evaluation of their approach on three different classification tasks. They found that this data augmentation technique was effective in reducing the number of high-confidence misclassifications made by the NLP models, while maintaining the same level of overall accuracy.
Additionally, the researchers discovered that the cost gap between using humans and using LLMs for this data generation task was more than an order of magnitude. The LLMs were able to achieve human-like performance in generating the synthetic data, but at a much lower cost and with greater scalability.
Critical Analysis
The paper provides a promising approach to addressing the issue of high-confidence errors in NLP models, but there are a few potential limitations and areas for further research that could be considered.
One potential concern is the reliance on the LLMs' ability to accurately characterize the high-confidence misclassifications. If the LLMs themselves have biases or make mistakes in their descriptions, that could introduce issues with the generated synthetic data. Further exploration of the quality and reliability of the LLM-generated data may be warranted.
Additionally, the paper focuses on classification tasks, and it's unclear how well this approach would generalize to other types of NLP problems, such as language generation or question-answering. Extending the evaluation to a wider range of NLP applications could provide a more comprehensive understanding of the technique's effectiveness.
Finally, while the researchers mention the significant cost savings of using LLMs compared to humans, they don't provide a detailed analysis of the computational and environmental costs associated with training and deploying the LLMs. Understanding the full life-cycle costs and environmental impact of this approach would be important for assessing its long-term viability.
Conclusion
This study demonstrates a promising approach to addressing the problem of high-confidence errors in NLP models using data augmentation with LLMs. By leveraging the language generation capabilities of LLMs, the researchers were able to effectively reduce the number of high-confidence mistakes made by the models, while maintaining overall accuracy.
The finding that LLMs can achieve human-like performance in this task at a significantly lower cost is particularly noteworthy, as it suggests a path towards more scalable and cost-effective solutions for improving the robustness of NLP systems. As the field of NLP continues to advance, techniques like this that can enhance the reliability and trustworthiness of these models will become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
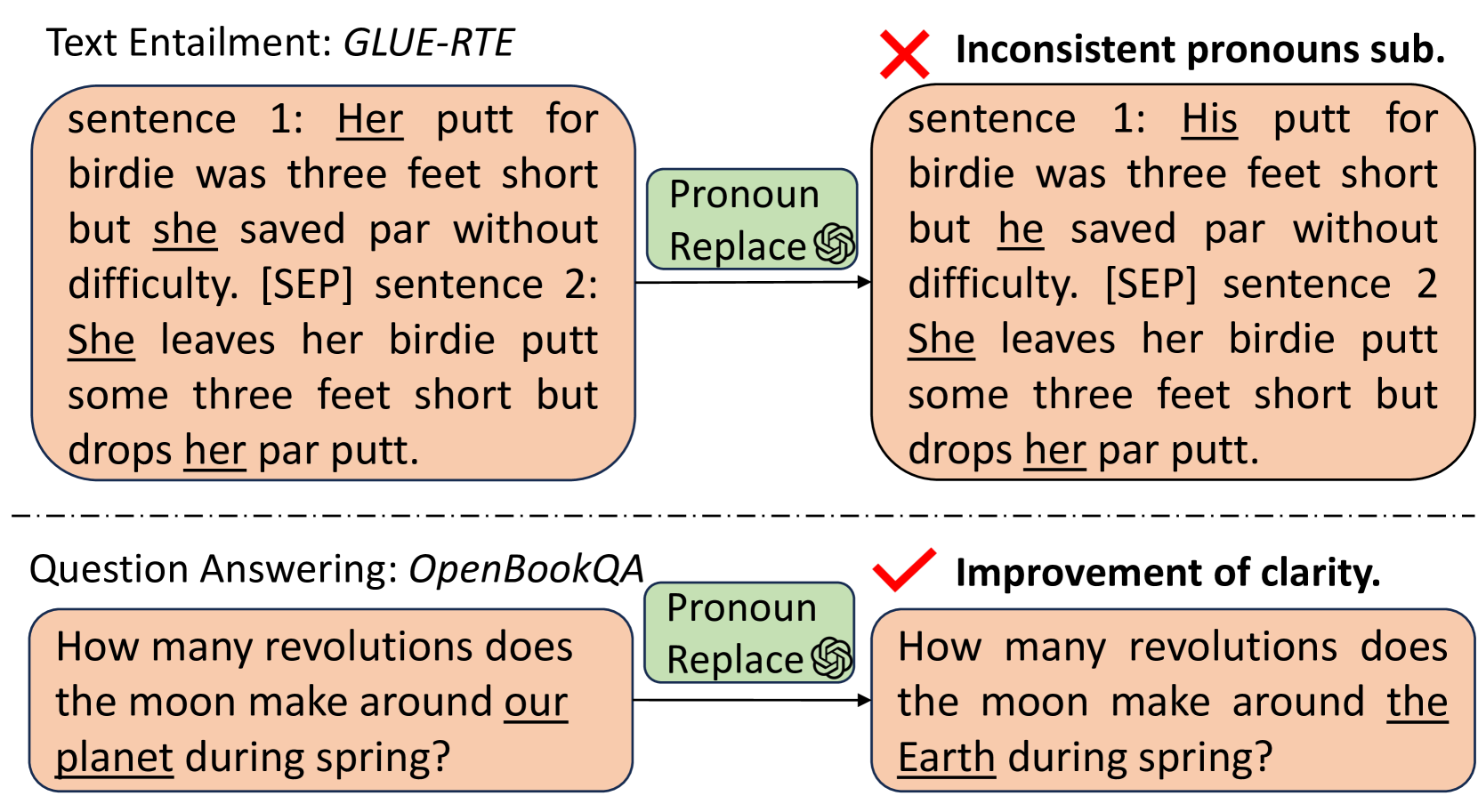
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
0
0
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
4/30/2024
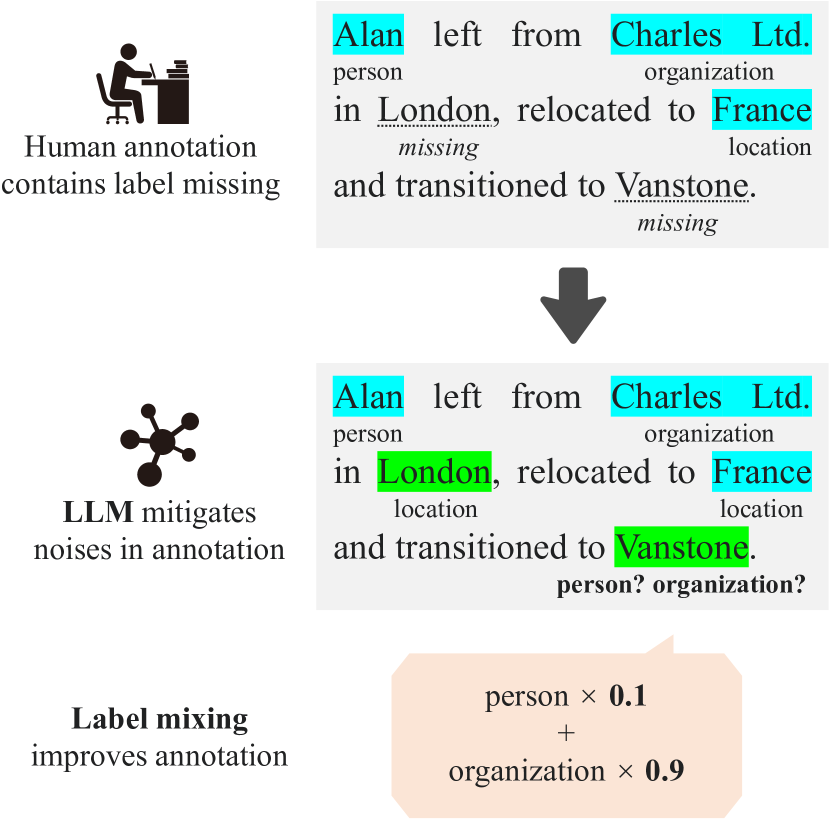
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
0
0
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
4/3/2024
💬
Large Human Language Models: A Need and the Challenges
Nikita Soni, H. Andrew Schwartz, Jo~ao Sedoc, Niranjan Balasubramanian
0
0
As research in human-centered NLP advances, there is a growing recognition of the importance of incorporating human and social factors into NLP models. At the same time, our NLP systems have become heavily reliant on LLMs, most of which do not model authors. To build NLP systems that can truly understand human language, we must better integrate human contexts into LLMs. This brings to the fore a range of design considerations and challenges in terms of what human aspects to capture, how to represent them, and what modeling strategies to pursue. To address these, we advocate for three positions toward creating large human language models (LHLMs) using concepts from psychological and behavioral sciences: First, LM training should include the human context. Second, LHLMs should recognize that people are more than their group(s). Third, LHLMs should be able to account for the dynamic and temporally-dependent nature of the human context. We refer to relevant advances and present open challenges that need to be addressed and their possible solutions in realizing these goals.
5/10/2024
💬
Utilizing Large Language Models to Generate Synthetic Data to Increase the Performance of BERT-Based Neural Networks
Chancellor R. Woolsey, Prakash Bisht, Joshua Rothman, Gondy Leroy
0
0
An important issue impacting healthcare is a lack of available experts. Machine learning (ML) models could resolve this by aiding in diagnosing patients. However, creating datasets large enough to train these models is expensive. We evaluated large language models (LLMs) for data creation. Using Autism Spectrum Disorders (ASD), we prompted ChatGPT and GPT-Premium to generate 4,200 synthetic observations to augment existing medical data. Our goal is to label behaviors corresponding to autism criteria and improve model accuracy with synthetic training data. We used a BERT classifier pre-trained on biomedical literature to assess differences in performance between models. A random sample (N=140) from the LLM-generated data was evaluated by a clinician and found to contain 83% correct example-label pairs. Augmenting data increased recall by 13% but decreased precision by 16%, correlating with higher quality and lower accuracy across pairs. Future work will analyze how different synthetic data traits affect ML outcomes.
5/14/2024