Empowering LLMs with Pseudo-Untrimmed Videos for Audio-Visual Temporal Understanding

0
Sign in to get full access
Overview
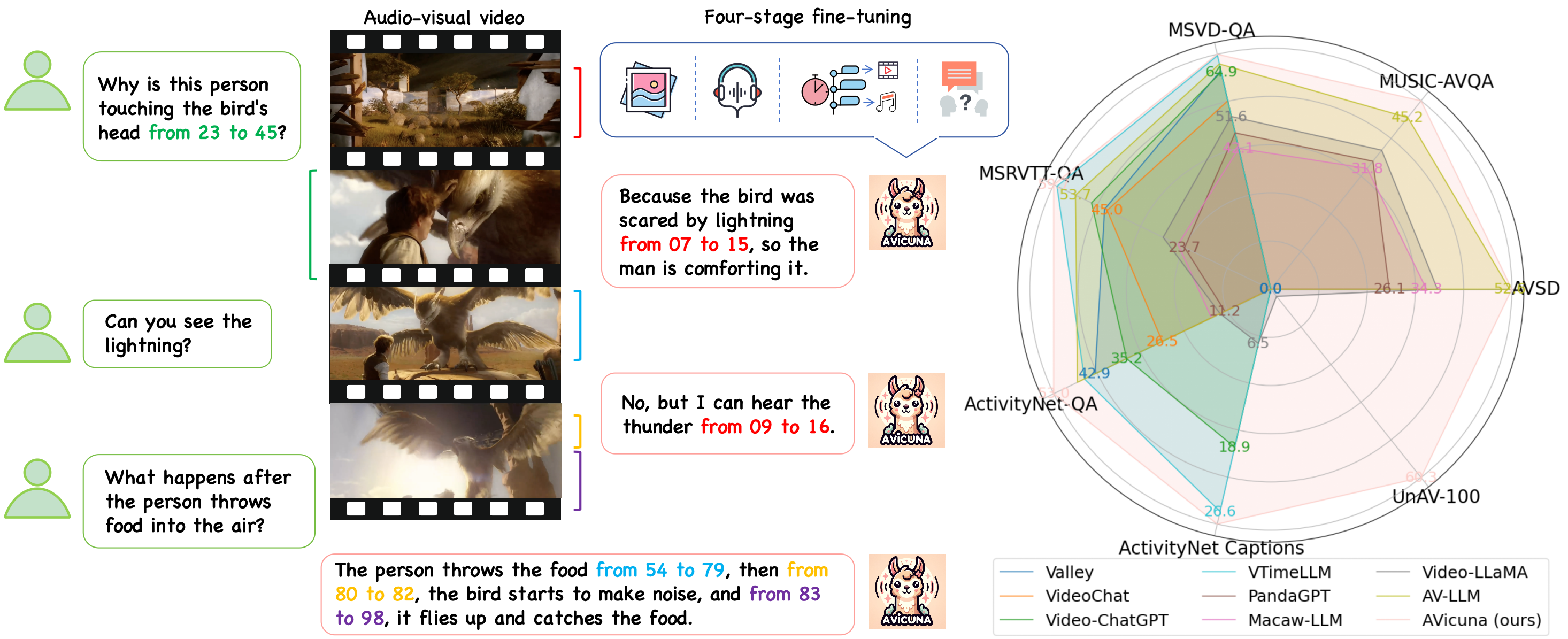
- Introduces AVicuna, an audio-visual language model that aligns context across modalities to enable temporal referential dialogue.
- Leverages an interleaver module and context-boundary alignment to improve the model's understanding of temporal references.
- Demonstrates strong performance on audio-visual tasks like emotion recognition and video captioning.
Plain English Explanation
AVicuna is a new type of language model that can understand and generate language not just from text, but also from audio and video. This allows it to better handle conversations that refer to things happening over time, like "the person in the red shirt just waved."
The key innovation in AVicuna is how it aligns the context across the different modalities (text, audio, video). This helps the model understand when a statement is referring to something seen or heard earlier in the conversation. It uses an interleaver module to fuse the information from the different inputs, and context-boundary alignment to make sure it's tracking the flow of the conversation correctly.
By handling these temporal references better, AVicuna performs well on tasks like emotion recognition from audio and video, and video captioning - describing what's happening in a video. It can understand the full context of a conversation, not just the words.
Technical Explanation
The paper introduces the AVicuna model, which is designed to handle temporal referential dialogue - conversations that refer back to things seen or heard earlier.
AVicuna uses an interleaver module to fuse the representations from the text, audio, and video inputs. This allows the model to reason about how the different modalities relate to each other over time. Additionally, it employs context-boundary alignment, which ensures the model correctly tracks the flow of the conversation and can associate statements with the appropriate visual and audio context.
The authors evaluate AVicuna on tasks like emotion recognition from audio-visual data and video captioning. They show that the model's ability to align context across modalities leads to strong performance, outperforming prior approaches that treat the modalities independently.
Critical Analysis
The paper provides a thorough technical explanation of the AVicuna model and demonstrates its effectiveness on relevant audio-visual tasks. However, the authors do acknowledge some limitations:
- The model was only evaluated on relatively short video clips, and it's unclear how it would scale to longer, more complex videos and conversations.
- The paper does not explore the model's generalization ability - how well it would perform on data very different from its training distribution.
- There could be interesting ethical considerations around the use of such powerful audio-visual language models, which the authors do not address.
Overall, the research is technically sound and represents an important step forward in audio-visual machine learning. Further exploration of the model's limitations and potential societal impacts would help provide a more holistic understanding of its capabilities and implications.
Conclusion
The AVicuna model introduced in this paper is a significant advancement in audio-visual language understanding. By aligning context across modalities, it can better handle temporal references and perform well on tasks like emotion recognition and video captioning.
This work highlights the potential for models that can seamlessly integrate information from multiple sensory inputs, opening up new possibilities for more natural and intuitive human-AI interaction. As the field of audio-visual machine learning continues to evolve, research like this will be crucial for developing AI systems that can truly understand and communicate in the way humans do.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Empowering LLMs with Pseudo-Untrimmed Videos for Audio-Visual Temporal Understanding
Yunlong Tang, Daiki Shimada, Jing Bi, Mingqian Feng, Hang Hua, Chenliang Xu
Large language models (LLMs) have demonstrated remarkable capabilities in natural language and multimodal domains. By fine-tuning multimodal LLMs with temporal annotations from well-annotated datasets, e.g., dense video captioning datasets, their temporal understanding capacity in video-language tasks can be obtained. However, there is a notable lack of untrimmed audio-visual video datasets with precise temporal annotations for events. This deficiency hinders LLMs from learning the alignment between time, audio-visual events, and text tokens, thus impairing their ability to temporally localize audio-visual events in videos. To address this gap, we introduce PU-VALOR, a comprehensive audio-visual dataset comprising over 114,000 pseudo-untrimmed videos with detailed temporal annotations. PU-VALOR is derived from the large-scale but coarse-annotated audio-visual dataset VALOR, through a subtle method involving event-based video clustering, random temporal scaling, and permutation. By fine-tuning a multimodal LLM on PU-VALOR, we developed AVicuna, a model capable of aligning audio-visual events with temporal intervals and corresponding text tokens. AVicuna excels in temporal localization and time-aware dialogue capabilities. Our experiments demonstrate that AVicuna effectively handles temporal understanding in audio-visual videos and achieves state-of-the-art performance on open-ended video QA, audio-visual QA, and audio-visual event dense localization tasks.
Read more8/22/2024

0
UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
Tiantian Geng, Teng Wang, Yanfu Zhang, Jinming Duan, Weili Guan, Feng Zheng, Ling shao
Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
Read more8/13/2024

0
Label-anticipated Event Disentanglement for Audio-Visual Video Parsing
Jinxing Zhou, Dan Guo, Yuxin Mao, Yiran Zhong, Xiaojun Chang, Meng Wang
Audio-Visual Video Parsing (AVVP) task aims to detect and temporally locate events within audio and visual modalities. Multiple events can overlap in the timeline, making identification challenging. While traditional methods usually focus on improving the early audio-visual encoders to embed more effective features, the decoding phase -- crucial for final event classification, often receives less attention. We aim to advance the decoding phase and improve its interpretability. Specifically, we introduce a new decoding paradigm, underline{l}abel sunderline{e}munderline{a}ntic-based underline{p}rojection (LEAP), that employs labels texts of event categories, each bearing distinct and explicit semantics, for parsing potentially overlapping events.LEAP works by iteratively projecting encoded latent features of audio/visual segments onto semantically independent label embeddings. This process, enriched by modeling cross-modal (audio/visual-label) interactions, gradually disentangles event semantics within video segments to refine relevant label embeddings, guaranteeing a more discriminative and interpretable decoding process. To facilitate the LEAP paradigm, we propose a semantic-aware optimization strategy, which includes a novel audio-visual semantic similarity loss function. This function leverages the Intersection over Union of audio and visual events (EIoU) as a novel metric to calibrate audio-visual similarities at the feature level, accommodating the varied event densities across modalities. Extensive experiments demonstrate the superiority of our method, achieving new state-of-the-art performance for AVVP and also enhancing the relevant audio-visual event localization task.
Read more7/12/2024
0
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
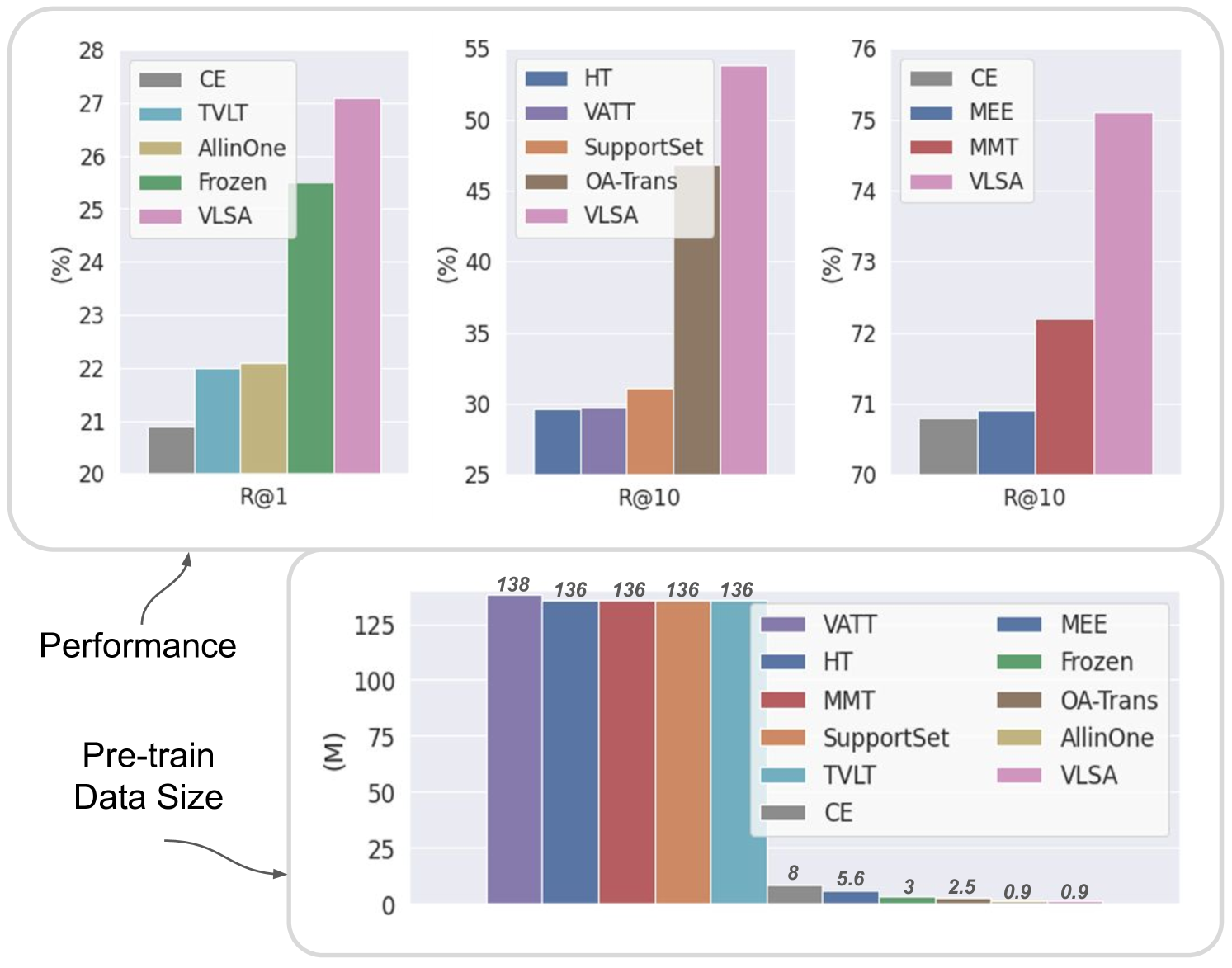
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
Read more5/14/2024