Encoder vs Decoder: Comparative Analysis of Encoder and Decoder Language Models on Multilingual NLU Tasks
2406.13469
0
0

Abstract
This paper explores the performance of encoder and decoder language models on multilingual Natural Language Understanding (NLU) tasks, with a broad focus on Germanic languages. Building upon the ScandEval benchmark, which initially was restricted to evaluating encoder models, we extend the evaluation framework to include decoder models. We introduce a method for evaluating decoder models on NLU tasks and apply it to the languages Danish, Swedish, Norwegian, Icelandic, Faroese, German, Dutch, and English. Through a series of experiments and analyses, we address key research questions regarding the comparative performance of encoder and decoder models, the impact of NLU task types, and the variation across language resources. Our findings reveal that decoder models can achieve significantly better NLU performance than encoder models, with nuances observed across different tasks and languages. Additionally, we investigate the correlation between decoders and task performance via a UMAP analysis, shedding light on the unique capabilities of decoder and encoder models. This study contributes to a deeper understanding of language model paradigms in NLU tasks and provides valuable insights for model selection and evaluation in multilingual settings.
Create account to get full access
Overview
- This paper compares the performance of encoder-based and decoder-based language models on multilingual natural language understanding (NLU) tasks.
- The authors evaluate models like BERT (an encoder) and GPT (a decoder) on tasks like text classification, named entity recognition, and question answering across 12 different languages.
- The goal is to understand the relative strengths and weaknesses of these two types of language models when applied to multilingual NLU.
Plain English Explanation
Language models are AI systems that can understand and generate human language. Two common types are encoder models, like BERT, which read text and extract meaning, and decoder models, like GPT, which generate human-like text.
This research compares how well encoder and decoder models perform on various language understanding tasks, like classifying text, identifying named entities, and answering questions. They test these models across 12 different languages, from English to Swahili, to see how the model architectures handle multilingual data.
The key finding is that there are tradeoffs between encoder and decoder models. Encoders generally excel at extracting information from text, but decoders can be better at generating fluent language. The choice between the two depends on the specific task and language requirements.
For example, an encoder model might be better for a task like scanning documents to find important facts, while a decoder could be more suitable for generating natural-sounding summaries. Understanding these differences can help developers choose the right language model for their multilingual applications.
Technical Explanation
The paper evaluates two main types of language models: encoder-based models like BERT, which read input text and extract contextual representations, and decoder-based models like GPT, which generate text auto-regressively.
The authors conduct experiments on a suite of multilingual NLU tasks, including text classification, named entity recognition, and question answering, using datasets covering 12 diverse languages. They fine-tune both encoder and decoder models on these tasks and compare their performance.
The results show that encoder models generally outperform decoders on extractive tasks like named entity recognition, where the goal is to identify key information in the input text. However, decoders can be superior on generative tasks like open-ended question answering, where they leverage their strong language modeling capabilities to produce more fluent responses.
The authors also explore the impact of model size, pre-training data, and other factors on these performance differences. They find that larger models and more diverse pre-training data can help narrow the gap between encoders and decoders, but fundamental architectural differences still lead to distinct strengths and weaknesses.
These findings have implications for the choice of language model architecture in multilingual NLP applications. Encoder models may be preferred for tasks focused on understanding and extracting information, while decoder models could be more suitable for generation-oriented applications like video captioning.
Critical Analysis
The paper provides a thorough, well-designed comparison of encoder and decoder language models on multilingual NLU tasks. The experimental setup, with datasets covering a diverse set of 12 languages, gives the results broad applicability.
However, one limitation is that the study only considers a handful of specific NLU tasks. While these are important benchmarks, the performance differences between encoders and decoders may vary for other language understanding or generation applications. Further research is needed to fully characterize the tradeoffs in different real-world use cases.
Additionally, the authors acknowledge the curse of multilinguality - the fact that multilingual models often underperform monolingual ones, especially for lower-resource languages. This is an important consideration when deploying these models in practical settings.
Overall, this paper makes a valuable contribution to understanding the relative merits of encoder and decoder language models. The insights can help guide developers in selecting the appropriate architecture for their multilingual NLP needs.
Conclusion
This research provides a comparative analysis of encoder-based and decoder-based language models on multilingual natural language understanding tasks. The key findings are:
- Encoder models generally outperform decoders on extractive tasks like named entity recognition, while decoders can be superior on generative tasks like open-ended question answering.
- These performance differences are influenced by the inherent architectural strengths of each model type, as well as factors like model size and pre-training data.
- The choice of language model architecture should be guided by the specific requirements of the target application, such as whether the focus is on understanding or generating language.
These insights can help developers make more informed decisions when selecting language models for their multilingual NLP systems, leading to better performance and more effective real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
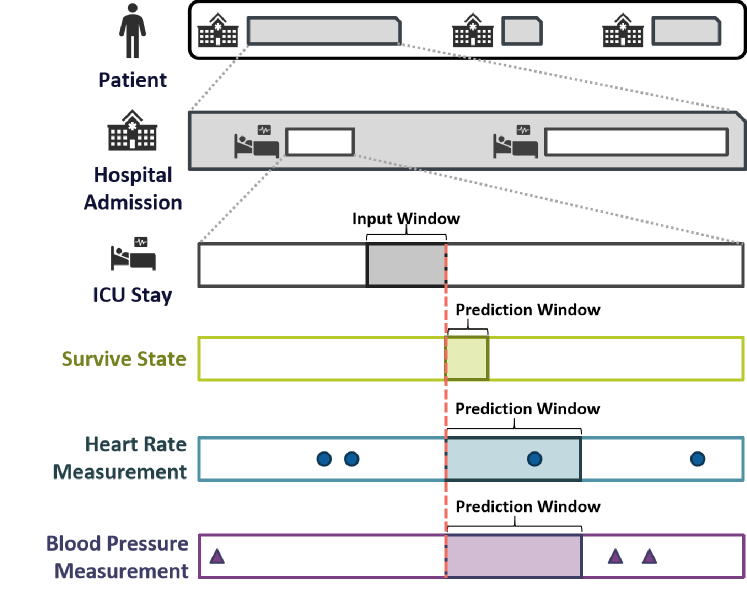
Large Language Model as a Universal Clinical Multi-task Decoder
Yujiang Wu, Hongjian Song, Jiawen Zhang, Xumeng Wen, Shun Zheng, Jiang Bian
0
0
The development of effective machine learning methodologies for enhancing the efficiency and accuracy of clinical systems is crucial. Despite significant research efforts, managing a plethora of diversified clinical tasks and adapting to emerging new tasks remain significant challenges. This paper presents a novel paradigm that employs a pre-trained large language model as a universal clinical multi-task decoder. This approach leverages the flexibility and diversity of language expressions to handle task topic variations and associated arguments. The introduction of a new task simply requires the addition of a new instruction template. We validate this framework across hundreds of tasks, demonstrating its robustness in facilitating multi-task predictions, performing on par with traditional multi-task learning and single-task learning approaches. Moreover, it shows exceptional adaptability to new tasks, with impressive zero-shot performance in some instances and superior data efficiency in few-shot scenarios. This novel approach offers a unified solution to manage a wide array of new and emerging tasks in clinical applications.
6/19/2024
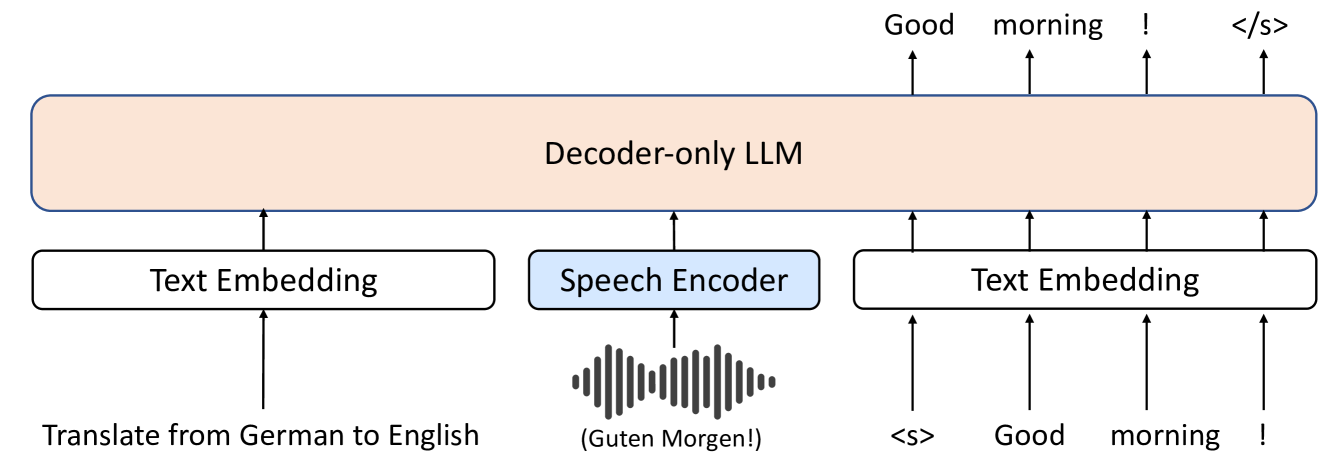
New!Investigating Decoder-only Large Language Models for Speech-to-text Translation
Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, Sravya Popuri
0
0
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.
7/4/2024
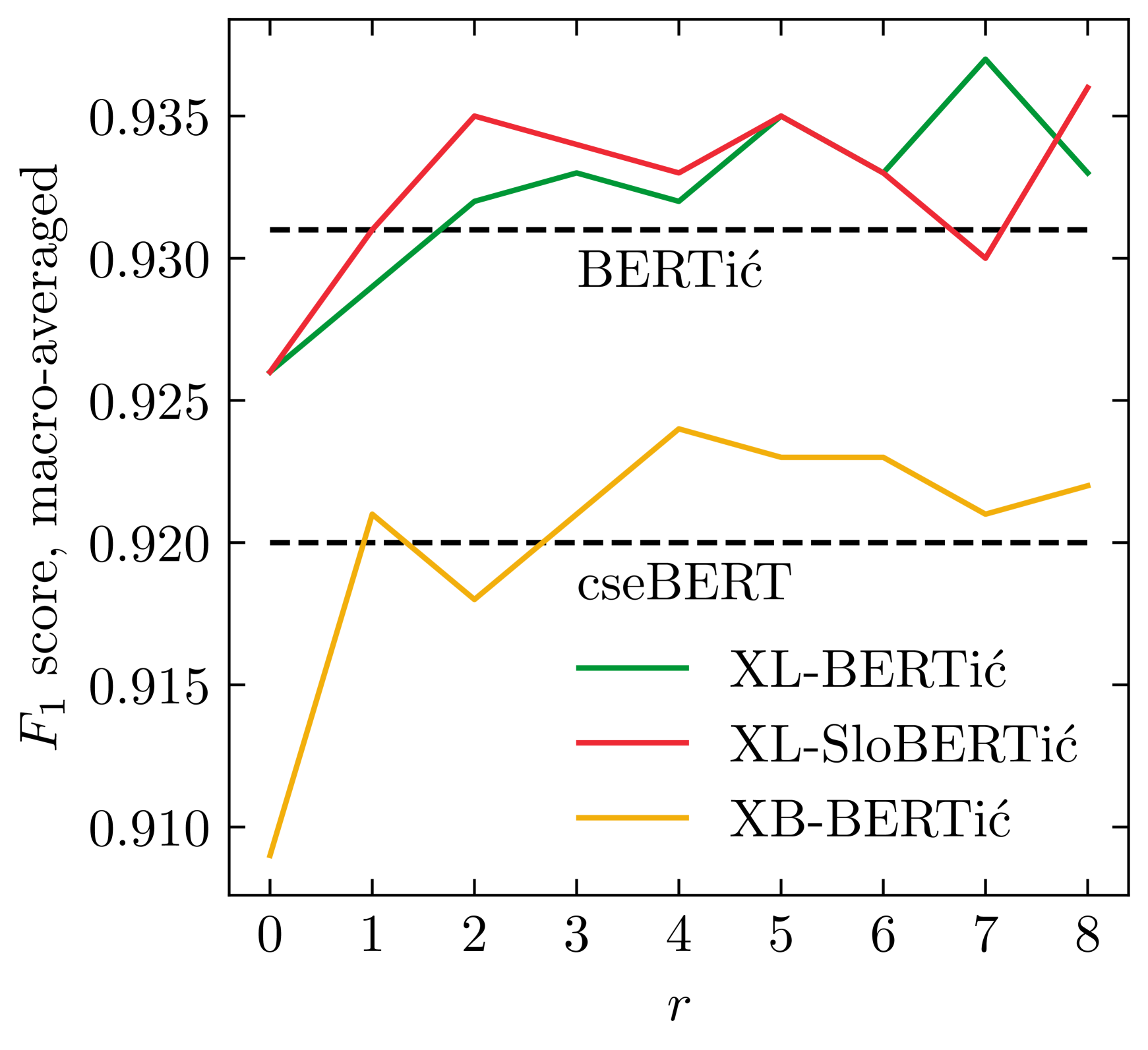
Language Models on a Diet: Cost-Efficient Development of Encoders for Closely-Related Languages via Additional Pretraining
Nikola Ljubev{s}i'c, V'it Suchomel, Peter Rupnik, Taja Kuzman, Rik van Noord
0
0
The world of language models is going through turbulent times, better and ever larger models are coming out at an unprecedented speed. However, we argue that, especially for the scientific community, encoder models of up to 1 billion parameters are still very much needed, their primary usage being in enriching large collections of data with metadata necessary for downstream research. We investigate the best way to ensure the existence of such encoder models on the set of very closely related languages - Croatian, Serbian, Bosnian and Montenegrin, by setting up a diverse benchmark for these languages, and comparing the trained-from-scratch models with the new models constructed via additional pretraining of existing multilingual models. We show that comparable performance to dedicated from-scratch models can be obtained by additionally pretraining available multilingual models even with a limited amount of computation. We also show that neighboring languages, in our case Slovenian, can be included in the additional pretraining with little to no loss in the performance of the final model.
4/9/2024

A Thorough Examination of Decoding Methods in the Era of LLMs
Chufan Shi, Haoran Yang, Deng Cai, Zhisong Zhang, Yifan Wang, Yujiu Yang, Wai Lam
0
0
Decoding methods play an indispensable role in converting language models from next-token predictors into practical task solvers. Prior research on decoding methods, primarily focusing on task-specific models, may not extend to the current era of general-purpose large language models (LLMs). Moreover, the recent influx of decoding strategies has further complicated this landscape. This paper provides a comprehensive and multifaceted analysis of various decoding methods within the context of LLMs, evaluating their performance, robustness to hyperparameter changes, and decoding speeds across a wide range of tasks, models, and deployment environments. Our findings reveal that decoding method performance is notably task-dependent and influenced by factors such as alignment, model size, and quantization. Intriguingly, sensitivity analysis exposes that certain methods achieve superior performance at the cost of extensive hyperparameter tuning, highlighting the trade-off between attaining optimal results and the practicality of implementation in varying contexts.
6/18/2024