Language Models on a Diet: Cost-Efficient Development of Encoders for Closely-Related Languages via Additional Pretraining
2404.05428
0
0
Abstract
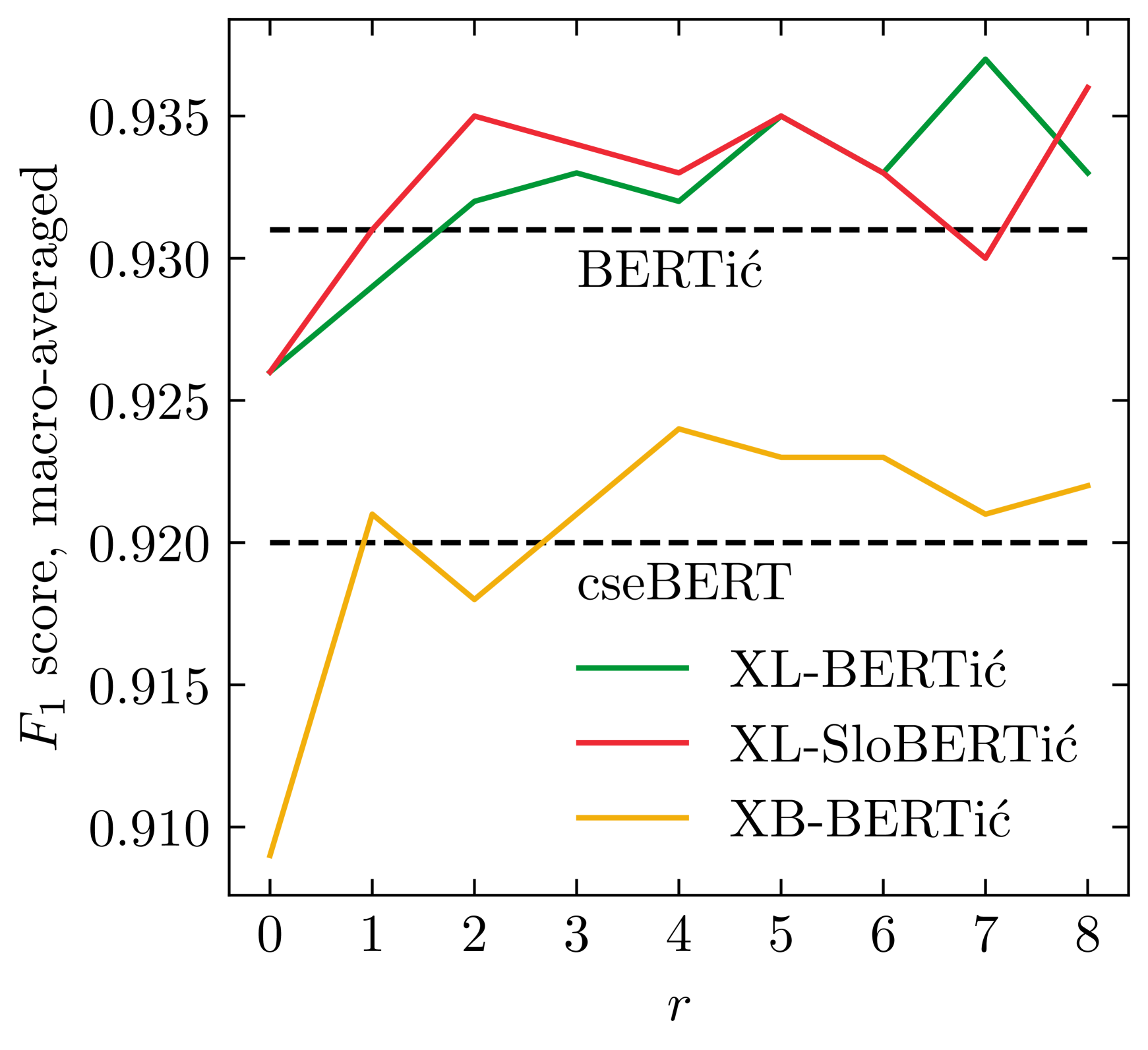
The world of language models is going through turbulent times, better and ever larger models are coming out at an unprecedented speed. However, we argue that, especially for the scientific community, encoder models of up to 1 billion parameters are still very much needed, their primary usage being in enriching large collections of data with metadata necessary for downstream research. We investigate the best way to ensure the existence of such encoder models on the set of very closely related languages - Croatian, Serbian, Bosnian and Montenegrin, by setting up a diverse benchmark for these languages, and comparing the trained-from-scratch models with the new models constructed via additional pretraining of existing multilingual models. We show that comparable performance to dedicated from-scratch models can be obtained by additionally pretraining available multilingual models even with a limited amount of computation. We also show that neighboring languages, in our case Slovenian, can be included in the additional pretraining with little to no loss in the performance of the final model.
Create account to get full access
Overview
- This paper explores a cost-efficient approach to developing language model encoders for closely related languages through additional pretraining.
- The researchers focus on developing language models for three Slavic languages - Russian, Ukrainian, and Belarusian - which are closely related.
- The key idea is to start with a base encoder trained on a high-resource language like English, and then perform additional pretraining on smaller datasets of the target languages to adapt the encoder.
- This enables building capable language models for the target languages without the need for full pretraining from scratch, which can be computationally expensive.
Plain English Explanation
The paper is about a way to build language models for similar languages without having to start from scratch each time. Language models are large AI systems that can understand and generate human language. They are often trained on huge datasets of text, which requires a lot of computing power and can be very expensive.
In this case, the researchers worked with three Slavic languages - Russian, Ukrainian, and Belarusian. These languages are quite similar to each other. The researchers started by training a base language model on a large, high-resource language like English. Then, they did additional training on smaller datasets of the target Slavic languages. This allowed them to adapt the base model to understand the Slavic languages, without having to do the full, expensive training process from the beginning.
The key insight is that since the Slavic languages are closely related, the base model trained on English already has a lot of the necessary knowledge. By fine-tuning it on the target languages, the researchers could create capable language models for Russian, Ukrainian, and Belarusian in a more cost-effective way. This could be useful for companies or researchers who want to build language models for similar languages but don't have the resources for full training from scratch.
Technical Explanation
The researchers start with a base encoder model, such as BERT, that has been pre-trained on a high-resource language like English. They then perform additional pretraining on smaller datasets of the target Slavic languages (Russian, Ukrainian, and Belarusian) to adapt the encoder.
This approach leverages the similarities between the Slavic languages to build specialized encoders without the need for full pretraining from scratch on each target language. The base encoder already contains a lot of relevant linguistic knowledge, so the additional pretraining can fine-tune it to the specifics of the target languages in a more efficient manner.
The experiments demonstrate that this approach can produce language models for the Slavic languages that achieve competitive performance compared to models trained from scratch, but at a lower computational cost. The researchers also analyze the effects of the additional pretraining, showing that it effectively transfers knowledge between the languages.
Critical Analysis
The paper presents a promising approach for efficiently developing language models for closely related languages. The core idea of leveraging a base encoder and performing targeted additional pretraining is sound and could be applicable to other language families beyond Slavic.
However, the paper does not explore the limitations of this approach. For instance, it's unclear how the method would scale to more distantly related languages, or how the performance would compare to multilingual models trained on a diverse set of languages. Additionally, the paper does not delve into potential issues around bias or fairness that could arise from the uneven distribution of resources across languages.
Further research could investigate the broader applicability of this approach, as well as its robustness and potential downsides. Exploring the tradeoffs between this targeted fine-tuning and more comprehensive multilingual modeling (Multilingual Brain Surgeon) would also be valuable.
Conclusion
This paper presents a cost-efficient approach to developing language model encoders for closely related languages. By starting with a base encoder trained on a high-resource language and performing additional pretraining on target language datasets, the researchers are able to adapt the encoder to understand similar languages without the need for full, expensive pretraining from scratch.
The results demonstrate the effectiveness of this approach for the Slavic language trio of Russian, Ukrainian, and Belarusian. This could be a useful technique for companies or researchers looking to build language models for related languages but lacking the resources for comprehensive multilingual training.
While the paper focuses on a specific language family, the core ideas could potentially be applied to other closely related languages, providing a more efficient path to developing capable language models. Further exploration of the limitations and broader applicability of this approach would be valuable for advancing the state of the art in multilingual language modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
LlamaTurk: Adapting Open-Source Generative Large Language Models for Low-Resource Language
Cagri Toraman
0
0
Despite advancements in English-dominant generative large language models, further development is needed for low-resource languages to enhance global accessibility. The primary methods for representing these languages are monolingual and multilingual pretraining. Monolingual pretraining is expensive due to hardware requirements, and multilingual models often have uneven performance across languages. This study explores an alternative solution by adapting large language models, primarily trained on English, to low-resource languages. We assess various strategies, including continual training, instruction fine-tuning, task-specific fine-tuning, and vocabulary extension. The results show that continual training improves language comprehension, as reflected in perplexity scores, and task-specific tuning generally enhances performance of downstream tasks. However, extending the vocabulary shows no substantial benefits. Additionally, while larger models improve task performance with few-shot tuning, multilingual models perform worse than their monolingual counterparts when adapted.
5/14/2024
💬
Targeted Multilingual Adaptation for Low-resource Language Families
C. M. Downey, Terra Blevins, Dhwani Serai, Dwija Parikh, Shane Steinert-Threlkeld
0
0
The massively-multilingual training of multilingual models is known to limit their utility in any one language, and they perform particularly poorly on low-resource languages. However, there is evidence that low-resource languages can benefit from targeted multilinguality, where the model is trained on closely related languages. To test this approach more rigorously, we systematically study best practices for adapting a pre-trained model to a language family. Focusing on the Uralic family as a test case, we adapt XLM-R under various configurations to model 15 languages; we then evaluate the performance of each experimental setting on two downstream tasks and 11 evaluation languages. Our adapted models significantly outperform mono- and multilingual baselines. Furthermore, a regression analysis of hyperparameter effects reveals that adapted vocabulary size is relatively unimportant for low-resource languages, and that low-resource languages can be aggressively up-sampled during training at little detriment to performance in high-resource languages. These results introduce new best practices for performing language adaptation in a targeted setting.
5/22/2024

Multilingual Large Language Models and Curse of Multilinguality
Daniil Gurgurov, Tanja Baumel, Tatiana Anikina
0
0
Multilingual Large Language Models (LLMs) have gained large popularity among Natural Language Processing (NLP) researchers and practitioners. These models, trained on huge datasets, show proficiency across various languages and demonstrate effectiveness in numerous downstream tasks. This paper navigates the landscape of multilingual LLMs, providing an introductory overview of their technical aspects. It explains underlying architectures, objective functions, pre-training data sources, and tokenization methods. This work explores the unique features of different model types: encoder-only (mBERT, XLM-R), decoder-only (XGLM, PALM, BLOOM, GPT-3), and encoder-decoder models (mT5, mBART). Additionally, it addresses one of the significant limitations of multilingual LLMs - the curse of multilinguality - and discusses current attempts to overcome it.
6/18/2024

Encoder vs Decoder: Comparative Analysis of Encoder and Decoder Language Models on Multilingual NLU Tasks
Dan Saattrup Nielsen, Kenneth Enevoldsen, Peter Schneider-Kamp
0
0
This paper explores the performance of encoder and decoder language models on multilingual Natural Language Understanding (NLU) tasks, with a broad focus on Germanic languages. Building upon the ScandEval benchmark, which initially was restricted to evaluating encoder models, we extend the evaluation framework to include decoder models. We introduce a method for evaluating decoder models on NLU tasks and apply it to the languages Danish, Swedish, Norwegian, Icelandic, Faroese, German, Dutch, and English. Through a series of experiments and analyses, we address key research questions regarding the comparative performance of encoder and decoder models, the impact of NLU task types, and the variation across language resources. Our findings reveal that decoder models can achieve significantly better NLU performance than encoder models, with nuances observed across different tasks and languages. Additionally, we investigate the correlation between decoders and task performance via a UMAP analysis, shedding light on the unique capabilities of decoder and encoder models. This study contributes to a deeper understanding of language model paradigms in NLU tasks and provides valuable insights for model selection and evaluation in multilingual settings.
6/21/2024