Encoding of lexical tone in self-supervised models of spoken language

0

Sign in to get full access
Overview
- This paper explores how self-supervised models of spoken language can learn to encode lexical tone, which is an important feature in many languages.
- The researchers investigate the internal representations learned by these models and how they capture tonal information.
- They find that self-supervised models are able to effectively encode lexical tone, providing insights into the language understanding capabilities of these models.
Plain English Explanation
Lexical tone is a feature of many languages where the pitch of a syllable can change the meaning of a word. For example, in Mandarin Chinese, the word "ma" can mean "mother," "hemp," "horse," or "to scold" depending on the tone used.
This paper looks at how self-supervised models of speech and language, which are trained on large amounts of unlabeled data, are able to learn and represent lexical tone information. These models have shown impressive language understanding capabilities, but it wasn't clear how they were handling this important aspect of many languages.
The researchers analyzed the internal representations of these models to see how they encode tonal information. They found that the models were quite effective at capturing the relevant acoustic cues and associating them with the correct lexical meanings. This suggests these models have a sophisticated understanding of how tone shapes the meaning of spoken language.
Understanding how self-supervised models handle tone is important because it gives us insight into their broader language comprehension abilities. Tone is a subtle but critical feature in many of the world's languages, so the fact that these models can handle it well indicates they are learning rich, nuanced representations of spoken language. This has implications for applications like speech recognition, language translation, and voice interfaces.
Technical Explanation
The paper investigates how self-supervised models of spoken language, such as wav2vec 2.0 and HuBERT, encode lexical tone information in their internal representations. The researchers analyzed the models' performance on tone classification tasks, as well as probing the model activations to understand how tonal cues are captured.
Experiments were conducted on Mandarin Chinese and Thai, two languages with rich tonal systems. The models were pretrained on large datasets of unlabeled speech, then fine-tuned and evaluated on tone classification tasks. The researchers found that the models were able to achieve high accuracy in predicting the correct tones, demonstrating an effective encoding of this linguistic feature.
Further analysis revealed that the models were able to associate the relevant acoustic cues, such as pitch variations, with the appropriate tonal categories. The learned representations showed systematic organization of tonal information, with distinct clusters for each tone class. This suggests the models have developed sophisticated tone-aware abstractions that go beyond simple acoustic pattern matching.
The paper provides insights into the inner workings of self-supervised speech models and their language understanding capabilities. The results indicate that these models are able to learn rich representations of lexical tone, a critical aspect of many of the world's languages. This has implications for the development of more robust and generalizable speech and language technologies.
Critical Analysis
The paper provides a thorough and well-designed investigation of how self-supervised speech models handle lexical tone. The experimental setup, with evaluations on two tonal languages, gives confidence in the generalizability of the findings. The detailed analysis of the models' internal representations also offers valuable insights into the mechanisms underlying their tone encoding.
That said, the paper does not address some potential limitations and caveats. For example, the experiments were conducted on high-resource languages with well-defined tonal systems. It would be interesting to see how the models perform on languages with more complex or ambiguous tone features. Additionally, the analysis focuses on the models' ability to classify tones, but does not explore how tone interacts with other linguistic phenomena, such as coarticulation or prosody.
Another potential area for further research would be to investigate how the models' tone encoding compares to human perception and representation of lexical tone. While the models show impressive performance, there may be subtle differences in how they process and organize tonal information compared to the human auditory system and language faculty.
Overall, this paper makes a valuable contribution to our understanding of self-supervised speech models and their language understanding capabilities. The findings suggest these models have developed sophisticated representations of lexical tone, but additional research is needed to fully characterize their strengths and limitations in this domain.
Conclusion
This paper provides an in-depth exploration of how self-supervised models of spoken language are able to effectively encode lexical tone information in their internal representations. The researchers' analysis of tone classification performance and the models' learned tone-aware abstractions offers important insights into the language understanding capabilities of these powerful AI systems.
The results indicate that self-supervised speech models can develop sophisticated representations of this crucial linguistic feature, which has implications for the development of more robust and generalizable speech and language technologies. While the paper focuses on high-resource tonal languages, further research is needed to understand how these models handle tone in more diverse linguistic contexts.
Overall, this work advances our understanding of the inner workings of self-supervised speech models and their ability to capture the nuances of spoken language. As these technologies continue to evolve, studies like this will be essential for ensuring they can effectively handle the rich complexities of human communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Encoding of lexical tone in self-supervised models of spoken language
Gaofei Shen, Michaela Watkins, Afra Alishahi, Arianna Bisazza, Grzegorz Chrupa{l}a
Interpretability research has shown that self-supervised Spoken Language Models (SLMs) encode a wide variety of features in human speech from the acoustic, phonetic, phonological, syntactic and semantic levels, to speaker characteristics. The bulk of prior research on representations of phonology has focused on segmental features such as phonemes; the encoding of suprasegmental phonology (such as tone and stress patterns) in SLMs is not yet well understood. Tone is a suprasegmental feature that is present in more than half of the world's languages. This paper aims to analyze the tone encoding capabilities of SLMs, using Mandarin and Vietnamese as case studies. We show that SLMs encode lexical tone to a significant degree even when they are trained on data from non-tonal languages. We further find that SLMs behave similarly to native and non-native human participants in tone and consonant perception studies, but they do not follow the same developmental trajectory.
Read more4/4/2024

0
A layer-wise analysis of Mandarin and English suprasegmentals in SSL speech models
Ant'on de la Fuente, Dan Jurafsky
This study asks how self-supervised speech models represent suprasegmental categories like Mandarin lexical tone, English lexical stress, and English phrasal accents. Through a series of probing tasks, we make layer-wise comparisons of English and Mandarin 12 layer monolingual models. Our findings suggest that 1) English and Mandarin wav2vec 2.0 models learn contextual representations of abstract suprasegmental categories which are strongest in the middle third of the network. 2) Models are better at representing features that exist in the language of their training data, and this difference is driven by enriched context in transformer blocks, not local acoustic representation. 3) Fine-tuned wav2vec 2.0 improves performance in later layers compared to pre-trained models mainly for lexically contrastive features like tone and stress, 4) HuBERT and WavLM learn similar representations to wav2vec 2.0, differing mainly in later layer performance. Our results extend previous understanding of how models represent suprasegmentals and offer new insights into the language-specificity and contextual nature of these representations.
Read more8/27/2024

0
Self-Supervised Speech Representations are More Phonetic than Semantic
Kwanghee Choi, Ankita Pasad, Tomohiko Nakamura, Satoru Fukayama, Karen Livescu, Shinji Watanabe
Self-supervised speech models (S3Ms) have become an effective backbone for speech applications. Various analyses suggest that S3Ms encode linguistic properties. In this work, we seek a more fine-grained analysis of the word-level linguistic properties encoded in S3Ms. Specifically, we curate a novel dataset of near homophone (phonetically similar) and synonym (semantically similar) word pairs and measure the similarities between S3M word representation pairs. Our study reveals that S3M representations consistently and significantly exhibit more phonetic than semantic similarity. Further, we question whether widely used intent classification datasets such as Fluent Speech Commands and Snips Smartlights are adequate for measuring semantic abilities. Our simple baseline, using only the word identity, surpasses S3M-based models. This corroborates our findings and suggests that high scores on these datasets do not necessarily guarantee the presence of semantic content.
Read more6/14/2024
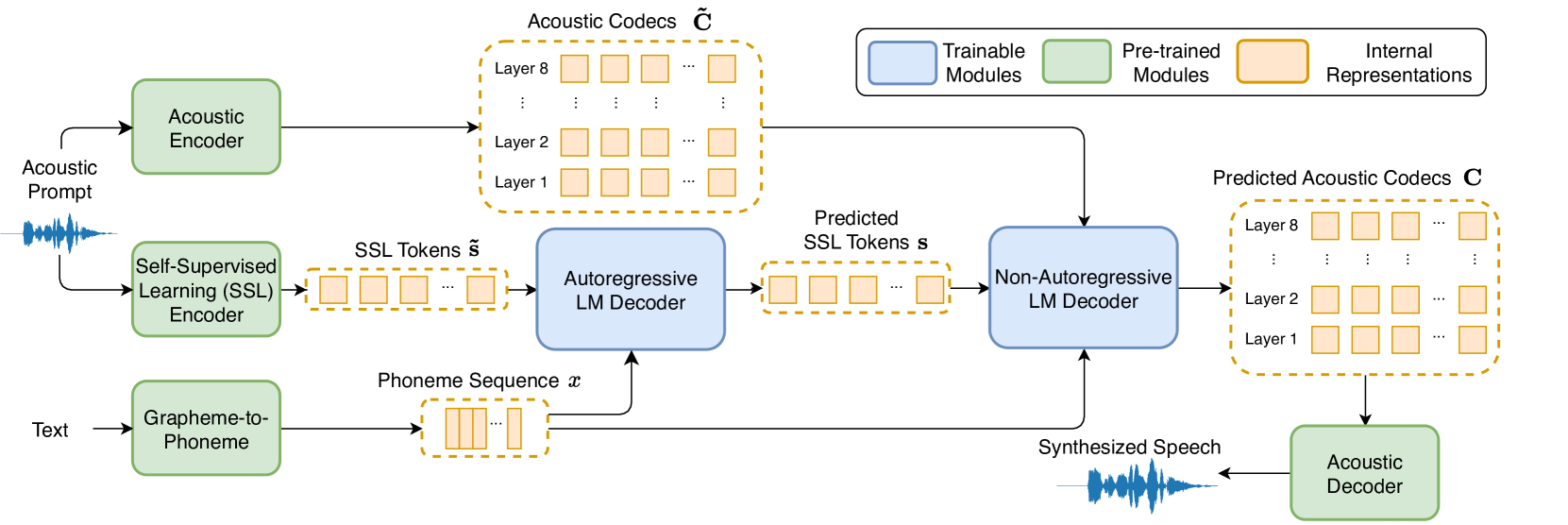
0
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Read more6/13/2024